 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCKAN: Structural Consensus-based KAN Prototype Learning for Semi-Supervised Pancreas Segmentation
May 26, 2026Accurate pancreas segmentation is critical for early cancer diagnosis, where annotation scarcity necessitates Semi-Supervised Learning (SSL). However, due to significant inter-sample morphological variability, existing SSL methods face severe generalizability limitations under sparse supervision, leading to the Supervision Bias problem. To address this, we propose Structural Consensus-based KAN Prototype Learning (SCKAN), which constructs the first cross-sample structural consensus learning with Kolmogorov-Arnold Networks (KANs), to achieve more generalizable and accurate segmentation. Specifically, SCKAN contains two key designs: Structure-constrained Prototype Consistency Learning (SPCL), which prompts unbiased structural representation by enforcing cross-sample consistency via prototype-level contrastive optimization, and Consensus-based Kolmogorov-Arnold Fusion (CKaF), which reduces morphology-specific bias by aggregating stable consensus and filtering sample-wise noise via KAN's adaptive B-spline nonlinearity. Extensive experiments on two public pancreas datasets demonstrate the effectiveness of SCKAN. Code is at https://github.com/rhodaliu17/SCKAN.
Granular conditional entropy-based attribute reduction for partially labeled data with proxy labels
Jan 23, 2021
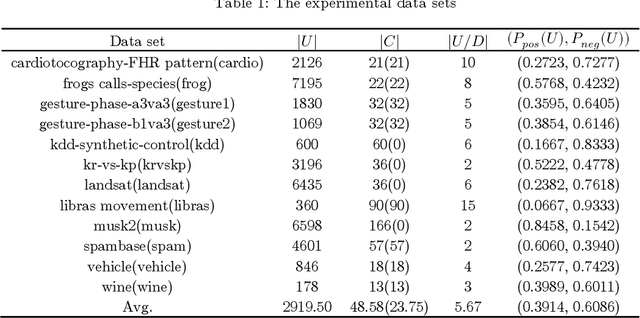
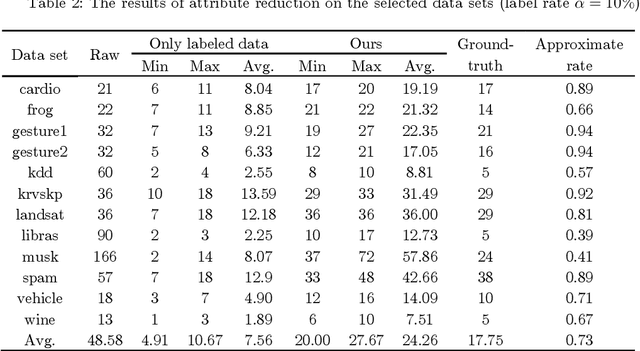
Attribute reduction is one of the most important research topics in the theory of rough sets, and many rough sets-based attribute reduction methods have thus been presented. However, most of them are specifically designed for dealing with either labeled data or unlabeled data, while many real-world applications come in the form of partial supervision. In this paper, we propose a rough sets-based semi-supervised attribute reduction method for partially labeled data. Particularly, with the aid of prior class distribution information about data, we first develop a simple yet effective strategy to produce the proxy labels for unlabeled data. Then the concept of information granularity is integrated into the information-theoretic measure, based on which, a novel granular conditional entropy measure is proposed, and its monotonicity is proved in theory. Furthermore, a fast heuristic algorithm is provided to generate the optimal reduct of partially labeled data, which could accelerate the process of attribute reduction by removing irrelevant examples and excluding redundant attributes simultaneously. Extensive experiments conducted on UCI data sets demonstrate that the proposed semi-supervised attribute reduction method is promising and even compares favourably with the supervised methods on labeled data and unlabeled data with true labels in terms of classification performance.