 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-RADAR: A Multi-Dimensional Benchmark for Evaluating Tool Use Capabilities in Large Language Models
May 22, 2025



As Large Language Models (LLMs) evolve from passive text generators to active reasoning agents capable of tool interaction, the Model Context Protocol (MCP) has emerged as a standardized framework for dynamic tool discovery and orchestration. Despite widespread industry adoption, existing evaluation methodologies fail to adequately assess tool utilization capabilities within this new paradigm. This paper introduces MCP-RADAR, the first comprehensive benchmark specifically designed to evaluate LLM performance in the MCP framework through a novel five-dimensional approach measuring: answer accuracy, tool selection efficiency, computational resource efficiency, parameter construction accuracy, and execution speed. Unlike conventional benchmarks that rely on subjective human evaluations or binary success metrics, MCP-RADAR employs objective, quantifiable measurements across multiple task domains including software engineering, mathematical reasoning, and general problem-solving. Our evaluations of leading commercial and open-source LLMs reveal distinctive capability profiles with significant trade-offs between accuracy, efficiency, and speed, challenging traditional single-metric performance rankings. Besides, we provide valuable guidance for developers to optimize their tools for maximum model compatibility and effectiveness. While focused on MCP due to its standardized approach, our methodology remains applicable across all LLM agent tool integration frameworks, providing valuable insights for both LLM developers and tool creators to optimize the entire LLM-tool interaction ecosystem. The implementation, configurations, and datasets used in our evaluation are publicly available at https://anonymous.4open.science/r/MCPRadar-B143.
Efficient DNN-Powered Software with Fair Sparse Models
Jul 03, 2024With the emergence of the Software 3.0 era, there is a growing trend of compressing and integrating large models into software systems, with significant societal implications. Regrettably, in numerous instances, model compression techniques impact the fairness performance of these models and thus the ethical behavior of DNN-powered software. One of the most notable example is the Lottery Ticket Hypothesis (LTH), a prevailing model pruning approach. This paper demonstrates that fairness issue of LTHbased pruning arises from both its subnetwork selection and training procedures, highlighting the inadequacy of existing remedies. To address this, we propose a novel pruning framework, Ballot, which employs a novel conflict-detection-based subnetwork selection to find accurate and fair subnetworks, coupled with a refined training process to attain a high-performance model, thereby improving the fairness of DNN-powered software. By means of this procedure, Ballot improves the fairness of pruning by 38.00%, 33.91%, 17.96%, and 35.82% compared to state-of-the-art baselines, namely Magnitude Pruning, Standard LTH, SafeCompress, and FairScratch respectively, based on our evaluation of five popular datasets and three widely used models. Our code is available at https://anonymous.4open.science/r/Ballot-506E.
CILIATE: Towards Fairer Class-based Incremental Learning by Dataset and Training Refinement
Apr 09, 2023



Due to the model aging problem, Deep Neural Networks (DNNs) need updates to adjust them to new data distributions. The common practice leverages incremental learning (IL), e.g., Class-based Incremental Learning (CIL) that updates output labels, to update the model with new data and a limited number of old data. This avoids heavyweight training (from scratch) using conventional methods and saves storage space by reducing the number of old data to store. But it also leads to poor performance in fairness. In this paper, we show that CIL suffers both dataset and algorithm bias problems, and existing solutions can only partially solve the problem. We propose a novel framework, CILIATE, that fixes both dataset and algorithm bias in CIL. It features a novel differential analysis guided dataset and training refinement process that identifies unique and important samples overlooked by existing CIL and enforces the model to learn from them. Through this process, CILIATE improves the fairness of CIL by 17.03%, 22.46%, and 31.79% compared to state-of-the-art methods, iCaRL, BiC, and WA, respectively, based on our evaluation on three popular datasets and widely used ResNet models.
FairNeuron: Improving Deep Neural Network Fairness with Adversary Games on Selective Neurons
Apr 06, 2022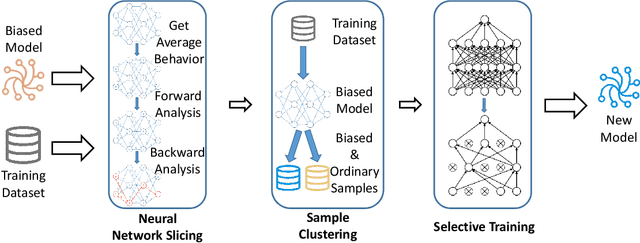

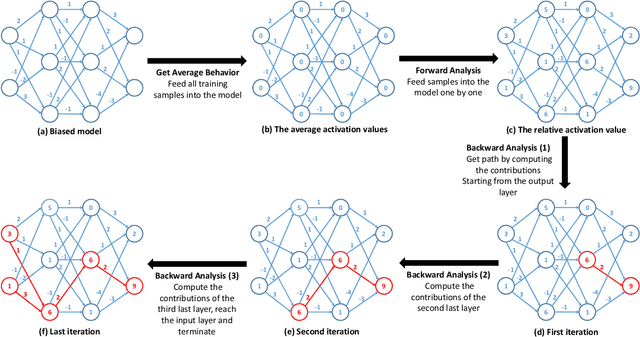
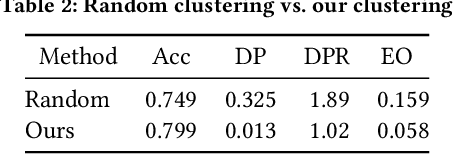
With Deep Neural Network (DNN) being integrated into a growing number of critical systems with far-reaching impacts on society, there are increasing concerns on their ethical performance, such as fairness. Unfortunately, model fairness and accuracy in many cases are contradictory goals to optimize. To solve this issue, there has been a number of work trying to improve model fairness by using an adversarial game in model level. This approach introduces an adversary that evaluates the fairness of a model besides its prediction accuracy on the main task, and performs joint-optimization to achieve a balanced result. In this paper, we noticed that when performing backward propagation based training, such contradictory phenomenon has shown on individual neuron level. Based on this observation, we propose FairNeuron, a DNN model automatic repairing tool, to mitigate fairness concerns and balance the accuracy-fairness trade-off without introducing another model. It works on detecting neurons with contradictory optimization directions from accuracy and fairness training goals, and achieving a trade-off by selective dropout. Comparing with state-of-the-art methods, our approach is lightweight, making it scalable and more efficient. Our evaluation on 3 datasets shows that FairNeuron can effectively improve all models' fairness while maintaining a stable utility.