 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Before Agreeing: Aligning Multi-Agent Consensus with Visual Evidence
May 29, 2026Vision-language models (VLMs) have achieved strong performance on visual question answering (VQA). To mitigate individual hallucinations and blind spots, aggregating diverse perspectives via multi-agent collaboration has emerged as a promising paradigm. While this approach has shown great success in textual QA, its potential in the multimodal domain remains under-explored. Existing multi-agent VQA methods predominantly adapt text-centric protocols, focusing on textual discussions while ignoring the alignment of visual information. In this work, we reveal a key insight: answer-level agreement is insufficient for reliable multi-agent VQA; \textit{aligned visual evidence} -- shared support from the image regions agents rely on -- is essential for trustworthy consensus. To leverage this insight, we propose EAGLE (\textbf{E}vidence-\textbf{A}ligned \textbf{G}rounded mu\textbf{L}ti-agent r\textbf{E}asoning), a training-free evidence-centered framework for coordinating multiple VLM agents. EAGLE explicitly exposes each agent's grounding regions as visual evidence, enables mutual verification over the evidence, and uses evidence consistency to guide final decision-making. Experiments on six VQA benchmarks show that EAGLE achieves best average performance across domains while remaining lightweight, interpretable, and practical for deployment.
Enhancing Anti-spoofing Countermeasures Robustness through Joint Optimization and Transfer Learning
Jul 29, 2024Current research in synthesized speech detection primarily focuses on the generalization of detection systems to unknown spoofing methods of noise-free speech. However, the performance of anti-spoofing countermeasures (CM) system is often don't work as well in more challenging scenarios, such as those involving noise and reverberation. To address the problem of enhancing the robustness of CM systems, we propose a transfer learning-based speech enhancement front-end joint optimization (TL-SEJ) method, investigating its effectiveness in improving robustness against noise and reverberation. We evaluated the proposed method's performance through a series of comparative and ablation experiments. The experimental results show that, across different signal-to-noise ratio test conditions, the proposed TL-SEJ method improves recognition accuracy by 2.7% to 15.8% compared to the baseline. Compared to conventional data augmentation methods, our system achieves an accuracy improvement ranging from 0.7% to 5.8% in various noisy conditions and from 1.7% to 2.8% under different RT60 reverberation scenarios. These experiments demonstrate that the proposed method effectively enhances system robustness in noisy and reverberant conditions.
The DKU-DUKEECE System for the Manipulation Region Location Task of ADD 2023
Aug 20, 2023



This paper introduces our system designed for Track 2, which focuses on locating manipulated regions, in the second Audio Deepfake Detection Challenge (ADD 2023). Our approach involves the utilization of multiple detection systems to identify splicing regions and determine their authenticity. Specifically, we train and integrate two frame-level systems: one for boundary detection and the other for deepfake detection. Additionally, we employ a third VAE model trained exclusively on genuine data to determine the authenticity of a given audio clip. Through the fusion of these three systems, our top-performing solution for the ADD challenge achieves an impressive 82.23% sentence accuracy and an F1 score of 60.66%. This results in a final ADD score of 0.6713, securing the first rank in Track 2 of ADD 2023.
Pretraining Conformer with ASR or ASV for Anti-Spoofing Countermeasure
Jul 04, 2023



This paper introduces the Multi-scale Feature Aggregation Conformer (MFA-Conformer) structure for audio anti-spoofing countermeasure (CM). MFA-Conformer combines a convolutional neural networkbased on the Transformer, allowing it to aggregate global andlocal information. This may benefit the anti-spoofing CM system to capture the synthetic artifacts hidden both locally and globally. In addition, given the excellent performance of MFA Conformer on automatic speech recognition (ASR) and automatic speaker verification (ASV) tasks, we present a transfer learning method that utilizes pretrained Conformer models on ASR or ASV tasks to enhance the robustness of CM systems. The proposed method is evaluated on both Chinese and Englishs poofing detection databases. On the FAD clean set, the MFA-Conformer model pretrained on the ASR task achieves an EER of 0.038%, which dramatically outperforms the baseline. Moreover, experimental results demonstrate that proposed transfer learning method on Conformer is effective on pure speech segments after voice activity detection processing.
Low Pass Filtering and Bandwidth Extension for Robust Anti-spoofing Countermeasure Against Codec Variabilities
Nov 12, 2022A reliable voice anti-spoofing countermeasure system needs to robustly protect automatic speaker verification (ASV) systems in various kinds of spoofing scenarios. However, the performance of countermeasure systems could be degraded by channel effects and codecs. In this paper, we show that using the low-frequency subbands of signals as input can mitigate the negative impact introduced by codecs on the countermeasure systems. To validate this, two types of low-pass filters with different cut-off frequencies are applied to countermeasure systems, and the equal error rate (EER) is reduced by up to 25% relatively. In addition, we propose a deep learning based bandwidth extension approach to further improve the detection accuracy. Recent studies show that the error rate of countermeasure systems increase dramatically when the silence part is removed by Voice Activity Detection (VAD), our experimental results show that the filtering and bandwidth extension approaches are also effective under the codec condition when VAD is applied.
The DKU-OPPO System for the 2022 Spoofing-Aware Speaker Verification Challenge
Jul 15, 2022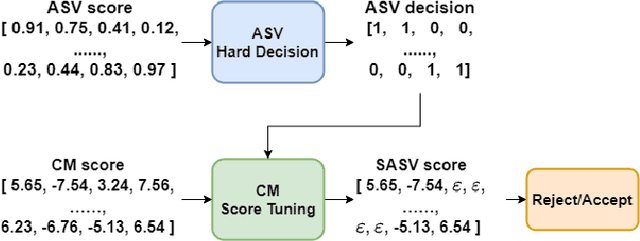
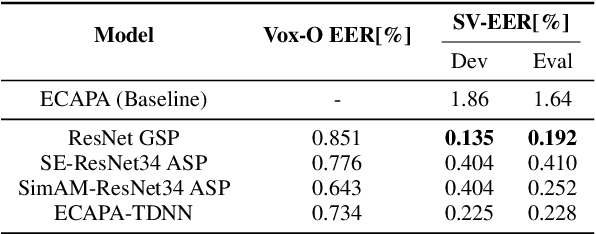
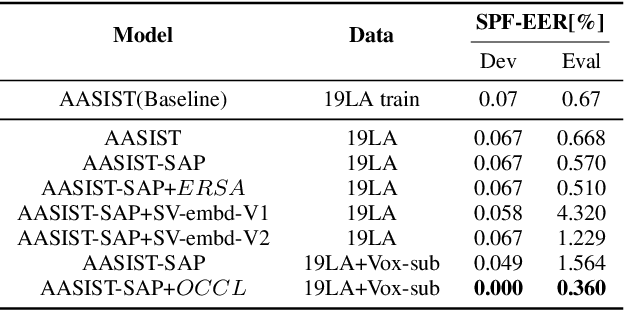
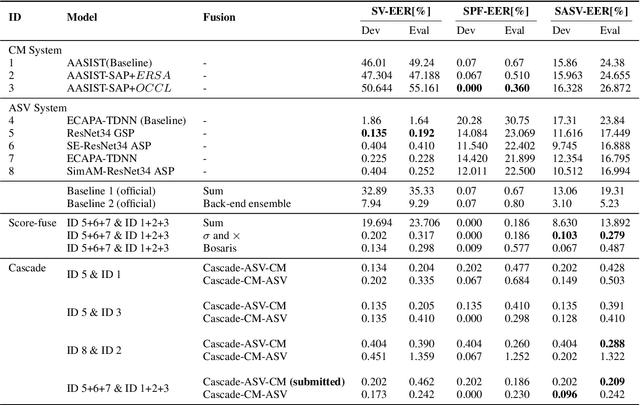
This paper describes our DKU-OPPO system for the 2022 Spoofing-Aware Speaker Verification (SASV) Challenge. First, we split the joint task into speaker verification (SV) and spoofing countermeasure (CM), these two tasks which are optimized separately. For ASV systems, four state-of-the-art methods are employed. For CM systems, we propose two methods on top of the challenge baseline to further improve the performance, namely Embedding Random Sampling Augmentation (ERSA) and One-Class Confusion Loss(OCCL). Second, we also explore whether SV embedding could help improve CM system performance. We observe a dramatic performance degradation of existing CM systems on the domain-mismatched Voxceleb2 dataset. Third, we compare different fusion strategies, including parallel score fusion and sequential cascaded systems. Compared to the 1.71% SASV-EER baseline, our submitted cascaded system obtains a 0.21% SASV-EER on the challenge official evaluation set.
Combination of Time-domain, Frequency-domain, and Cepstral-domain Acoustic Features for Speech Commands Classification
Mar 30, 2022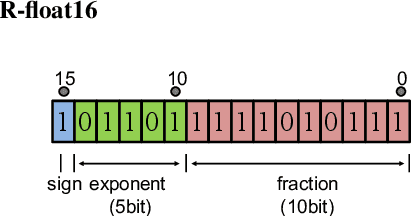
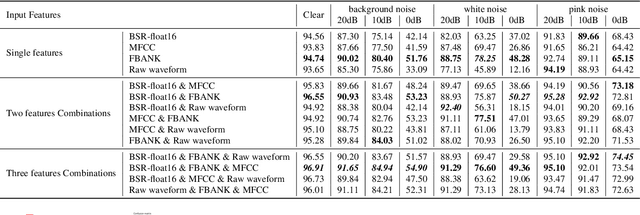
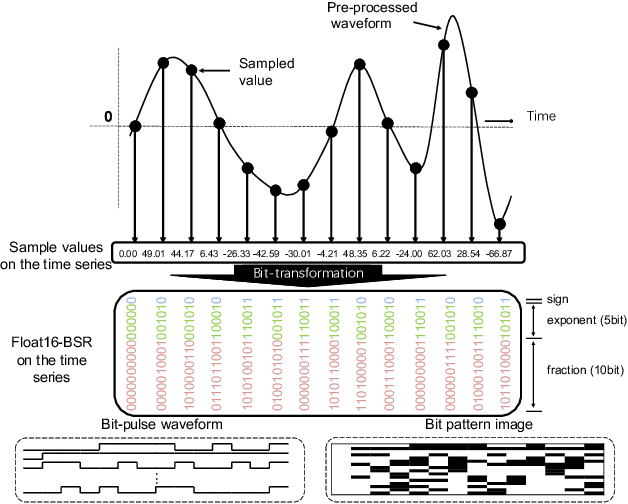
In speech-related classification tasks, frequency-domain acoustic features such as logarithmic Mel-filter bank coefficients (FBANK) and cepstral-domain acoustic features such as Mel-frequency cepstral coefficients (MFCC) are often used. However, time-domain features perform more effectively in some sound classification tasks which contain non-vocal or weakly speech-related sounds. We previously proposed a feature called bit sequence representation (BSR), which is a time-domain binary acoustic feature based on the raw waveform. Compared with MFCC, BSR performed better in environmental sound detection and showed comparable accuracy performance in limited-vocabulary speech recognition tasks. In this paper, we propose a novel improvement BSR feature called BSR-float16 to represent floating-point values more precisely. We experimentally demonstrated the complementarity among time-domain, frequency-domain, and cepstral-domain features using a dataset called Speech Commands proposed by Google. Therefore, we used a simple back-end score fusion method to improve the final classification accuracy. The fusion results also showed better noise robustness.