 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Post-Training for Vision-Language-Action Models
May 22, 2025We introduce RIPT-VLA, a simple and scalable reinforcement-learning-based interactive post-training paradigm that fine-tunes pretrained Vision-Language-Action (VLA) models using only sparse binary success rewards. Existing VLA training pipelines rely heavily on offline expert demonstration data and supervised imitation, limiting their ability to adapt to new tasks and environments under low-data regimes. RIPT-VLA addresses this by enabling interactive post-training with a stable policy optimization algorithm based on dynamic rollout sampling and leave-one-out advantage estimation. RIPT-VLA has the following characteristics. First, it applies to various VLA models, resulting in an improvement on the lightweight QueST model by 21.2%, and the 7B OpenVLA-OFT model to an unprecedented 97.5% success rate. Second, it is computationally efficient and data-efficient: with only one demonstration, RIPT-VLA enables an unworkable SFT model (4%) to succeed with a 97% success rate within 15 iterations. Furthermore, we demonstrate that the policy learned by RIPT-VLA generalizes across different tasks and scenarios and is robust to the initial state context. These results highlight RIPT-VLA as a practical and effective paradigm for post-training VLA models through minimal supervision.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
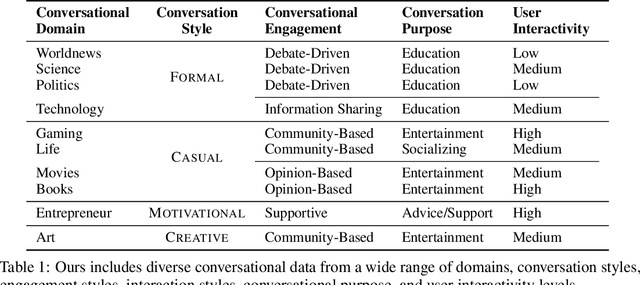


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
AD-AGENT: A Multi-agent Framework for End-to-end Anomaly Detection
May 19, 2025



Anomaly detection (AD) is essential in areas such as fraud detection, network monitoring, and scientific research. However, the diversity of data modalities and the increasing number of specialized AD libraries pose challenges for non-expert users who lack in-depth library-specific knowledge and advanced programming skills. To tackle this, we present AD-AGENT, an LLM-driven multi-agent framework that turns natural-language instructions into fully executable AD pipelines. AD-AGENT coordinates specialized agents for intent parsing, data preparation, library and model selection, documentation mining, and iterative code generation and debugging. Using a shared short-term workspace and a long-term cache, the agents integrate popular AD libraries like PyOD, PyGOD, and TSLib into a unified workflow. Experiments demonstrate that AD-AGENT produces reliable scripts and recommends competitive models across libraries. The system is open-sourced to support further research and practical applications in AD.
Convert Language Model into a Value-based Strategic Planner
May 11, 2025



Emotional support conversation (ESC) aims to alleviate the emotional distress of individuals through effective conversations. Although large language models (LLMs) have obtained remarkable progress on ESC, most of these studies might not define the diagram from the state model perspective, therefore providing a suboptimal solution for long-term satisfaction. To address such an issue, we leverage the Q-learning on LLMs, and propose a framework called straQ*. Our framework allows a plug-and-play LLM to bootstrap the planning during ESC, determine the optimal strategy based on long-term returns, and finally guide the LLM to response. Substantial experiments on ESC datasets suggest that straQ* outperforms many baselines, including direct inference, self-refine, chain of thought, finetuning, and finite state machines.
RayZer: A Self-supervised Large View Synthesis Model
May 01, 2025



We present RayZer, a self-supervised multi-view 3D Vision model trained without any 3D supervision, i.e., camera poses and scene geometry, while exhibiting emerging 3D awareness. Concretely, RayZer takes unposed and uncalibrated images as input, recovers camera parameters, reconstructs a scene representation, and synthesizes novel views. During training, RayZer relies solely on its self-predicted camera poses to render target views, eliminating the need for any ground-truth camera annotations and allowing RayZer to be trained with 2D image supervision. The emerging 3D awareness of RayZer is attributed to two key factors. First, we design a self-supervised framework, which achieves 3D-aware auto-encoding of input images by disentangling camera and scene representations. Second, we design a transformer-based model in which the only 3D prior is the ray structure, connecting camera, pixel, and scene simultaneously. RayZer demonstrates comparable or even superior novel view synthesis performance than ``oracle'' methods that rely on pose annotations in both training and testing. Project: https://hwjiang1510.github.io/RayZer/
Multivariate Conformal Selection
May 01, 2025



Selecting high-quality candidates from large datasets is critical in applications such as drug discovery, precision medicine, and alignment of large language models (LLMs). While Conformal Selection (CS) provides rigorous uncertainty quantification, it is limited to univariate responses and scalar criteria. To address this issue, we propose Multivariate Conformal Selection (mCS), a generalization of CS designed for multivariate response settings. Our method introduces regional monotonicity and employs multivariate nonconformity scores to construct conformal p-values, enabling finite-sample False Discovery Rate (FDR) control. We present two variants: mCS-dist, using distance-based scores, and mCS-learn, which learns optimal scores via differentiable optimization. Experiments on simulated and real-world datasets demonstrate that mCS significantly improves selection power while maintaining FDR control, establishing it as a robust framework for multivariate selection tasks.
Doxing via the Lens: Revealing Privacy Leakage in Image Geolocation for Agentic Multi-Modal Large Reasoning Model
Apr 29, 2025The increasing capabilities of agentic multi-modal large reasoning models, such as ChatGPT o3, have raised critical concerns regarding privacy leakage through inadvertent image geolocation. In this paper, we conduct the first systematic and controlled study on the potential privacy risks associated with visual reasoning abilities of ChatGPT o3. We manually collect and construct a dataset comprising 50 real-world images that feature individuals alongside privacy-relevant environmental elements, capturing realistic and sensitive scenarios for analysis. Our experimental evaluation reveals that ChatGPT o3 can predict user locations with high precision, achieving street-level accuracy (within one mile) in 60% of cases. Through analysis, we identify key visual cues, including street layout and front yard design, that significantly contribute to the model inference success. Additionally, targeted occlusion experiments demonstrate that masking critical features effectively mitigates geolocation accuracy, providing insights into potential defense mechanisms. Our findings highlight an urgent need for privacy-aware development for agentic multi-modal large reasoning models, particularly in applications involving private imagery.
Graph Synthetic Out-of-Distribution Exposure with Large Language Models
Apr 29, 2025



Out-of-distribution (OOD) detection in graphs is critical for ensuring model robustness in open-world and safety-sensitive applications. Existing approaches to graph OOD detection typically involve training an in-distribution (ID) classifier using only ID data, followed by the application of post-hoc OOD scoring techniques. Although OOD exposure - introducing auxiliary OOD samples during training - has proven to be an effective strategy for enhancing detection performance, current methods in the graph domain generally assume access to a set of real OOD nodes. This assumption, however, is often impractical due to the difficulty and cost of acquiring representative OOD samples. In this paper, we introduce GOE-LLM, a novel framework that leverages Large Language Models (LLMs) for OOD exposure in graph OOD detection without requiring real OOD nodes. GOE-LLM introduces two pipelines: (1) identifying pseudo-OOD nodes from the initially unlabeled graph using zero-shot LLM annotations, and (2) generating semantically informative synthetic OOD nodes via LLM-prompted text generation. These pseudo-OOD nodes are then used to regularize the training of the ID classifier for improved OOD awareness. We evaluate our approach across multiple benchmark datasets, showing that GOE-LLM significantly outperforms state-of-the-art graph OOD detection methods that do not use OOD exposure and achieves comparable performance to those relying on real OOD data.
GLIP-OOD: Zero-Shot Graph OOD Detection with Foundation Model
Apr 29, 2025



Out-of-distribution (OOD) detection is critical for ensuring the safety and reliability of machine learning systems, particularly in dynamic and open-world environments. In the vision and text domains, zero-shot OOD detection - which requires no training on in-distribution (ID) data - has made significant progress through the use of large-scale pretrained models such as vision-language models (VLMs) and large language models (LLMs). However, zero-shot OOD detection in graph-structured data remains largely unexplored, primarily due to the challenges posed by complex relational structures and the absence of powerful, large-scale pretrained models for graphs. In this work, we take the first step toward enabling zero-shot graph OOD detection by leveraging a graph foundation model (GFM). We show that, when provided only with class label names, the GFM can perform OOD detection without any node-level supervision - outperforming existing supervised methods across multiple datasets. To address the more practical setting where OOD label names are unavailable, we introduce GLIP-OOD, a novel framework that employs LLMs to generate semantically informative pseudo-OOD labels from unlabeled data. These labels enable the GFM to capture nuanced semantic boundaries between ID and OOD classes and perform fine-grained OOD detection - without requiring any labeled nodes. Our approach is the first to enable node-level graph OOD detection in a fully zero-shot setting, and achieves state-of-the-art performance on four benchmark text-attributed graph datasets.
FiSMiness: A Finite State Machine Based Paradigm for Emotional Support Conversations
Apr 16, 2025



Emotional support conversation (ESC) aims to alleviate the emotional distress of individuals through effective conversations. Although large language models (LLMs) have obtained remarkable progress on ESC, most of these studies might not define the diagram from the state model perspective, therefore providing a suboptimal solution for long-term satisfaction. To address such an issue, we leverage the Finite State Machine (FSM) on LLMs, and propose a framework called FiSMiness. Our framework allows a single LLM to bootstrap the planning during ESC, and self-reason the seeker's emotion, support strategy and the final response upon each conversational turn. Substantial experiments on ESC datasets suggest that FiSMiness outperforms many baselines, including direct inference, self-refine, chain of thought, finetuning, and external-assisted methods, even those with many more parameters.