 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Selective Prediction with General Risk Control
Mar 25, 2026In deploying artificial intelligence (AI) models, selective prediction offers the option to abstain from making a prediction when uncertain about model quality. To fulfill its promise, it is crucial to enforce strict and precise error control over cases where the model is trusted. We propose Selective Conformal Risk control with E-values (SCoRE), a new framework for deriving such decisions for any trained model and any user-defined, bounded and continuously-valued risk. SCoRE offers two types of guarantees on the risk among ``positive'' cases in which the system opts to trust the model. Built upon conformal inference and hypothesis testing ideas, SCoRE first constructs a class of (generalized) e-values, which are non-negative random variables whose product with the unknown risk has expectation no greater than one. Such a property is ensured by data exchangeability without requiring any modeling assumptions. Passing these e-values on to hypothesis testing procedures, we yield the binary trust decisions with finite-sample error control. SCoRE avoids the need of uniform concentration, and can be readily extended to settings with distribution shifts. We evaluate the proposed methods with simulations and demonstrate their efficacy through applications to error management in drug discovery, health risk prediction, and large language models.
ExpAlign: Expectation-Guided Vision-Language Alignment for Open-Vocabulary Grounding
Jan 30, 2026Open-vocabulary grounding requires accurate vision-language alignment under weak supervision, yet existing methods either rely on global sentence embeddings that lack fine-grained expressiveness or introduce token-level alignment with explicit supervision or heavy cross-attention designs. We propose ExpAlign, a theoretically grounded vision-language alignment framework built on a principled multiple instance learning formulation. ExpAlign introduces an Expectation Alignment Head that performs attention-based soft MIL pooling over token-region similarities, enabling implicit token and instance selection without additional annotations. To further stabilize alignment learning, we develop an energy-based multi-scale consistency regularization scheme, including a Top-K multi-positive contrastive objective and a Geometry-Aware Consistency Objective derived from a Lagrangian-constrained free-energy minimization. Extensive experiments show that ExpAlign consistently improves open-vocabulary detection and zero-shot instance segmentation, particularly on long-tail categories. Most notably, it achieves 36.2 AP$_r$ on the LVIS minival split, outperforming other state-of-the-art methods at comparable model scale, while remaining lightweight and inference-efficient.
Multi-Stage Patient Role-Playing Framework for Realistic Clinical Interactions
Jan 16, 2026The simulation of realistic clinical interactions plays a pivotal role in advancing clinical Large Language Models (LLMs) and supporting medical diagnostic education. Existing approaches and benchmarks rely on generic or LLM-generated dialogue data, which limits the authenticity and diversity of doctor-patient interactions. In this work, we propose the first Chinese patient simulation dataset (Ch-PatientSim), constructed from realistic clinical interaction scenarios to comprehensively evaluate the performance of models in emulating patient behavior. Patients are simulated based on a five-dimensional persona structure. To address issues of the persona class imbalance, a portion of the dataset is augmented using few-shot generation, followed by manual verification. We evaluate various state-of-the-art LLMs and find that most produce overly formal responses that lack individual personality. To address this limitation, we propose a training-free Multi-Stage Patient Role-Playing (MSPRP) framework, which decomposes interactions into three stages to ensure both personalization and realism in model responses. Experimental results demonstrate that our approach significantly improves model performance across multiple dimensions of patient simulation.
VERHallu: Evaluating and Mitigating Event Relation Hallucination in Video Large Language Models
Jan 15, 2026Video Large Language Models (VideoLLMs) exhibit various types of hallucinations. Existing research has primarily focused on hallucinations involving the presence of events, objects, and scenes in videos, while largely neglecting event relation hallucination. In this paper, we introduce a novel benchmark for evaluating the Video Event Relation Hallucination, named VERHallu. This benchmark focuses on causal, temporal, and subevent relations between events, encompassing three types of tasks: relation classification, question answering, and counterfactual question answering, for a comprehensive evaluation of event relation hallucination. Additionally, it features counterintuitive video scenarios that deviate from typical pretraining distributions, with each sample accompanied by human-annotated candidates covering both vision-language and pure language biases. Our analysis reveals that current state-of-the-art VideoLLMs struggle with dense-event relation reasoning, often relying on prior knowledge due to insufficient use of frame-level cues. Although these models demonstrate strong grounding capabilities for key events, they often overlook the surrounding subevents, leading to an incomplete and inaccurate understanding of event relations. To tackle this, we propose a Key-Frame Propagating (KFP) strategy, which reallocates frame-level attention within intermediate layers to enhance multi-event understanding. Experiments show it effectively mitigates the event relation hallucination without affecting inference speed.
Pyramid Sparse Transformer: Enhancing Multi-Scale Feature Fusion with Dynamic Token Selection
May 19, 2025



Feature fusion is critical for high-performance vision models but often incurs prohibitive complexity. However, prevailing attention-based fusion methods often involve significant computational complexity and implementation challenges, limiting their efficiency in resource-constrained environments. To address these issues, we introduce the Pyramid Sparse Transformer (PST), a lightweight, plug-and-play module that integrates coarse-to-fine token selection and shared attention parameters to reduce computation while preserving spatial detail. PST can be trained using only coarse attention and seamlessly activated at inference for further accuracy gains without retraining. When added to state-of-the-art real-time detection models, such as YOLOv11-N/S/M, PST yields mAP improvements of 0.9%, 0.5%, and 0.4% on MS COCO with minimal latency impact. Likewise, embedding PST into ResNet-18/50/101 as backbones, boosts ImageNet top-1 accuracy by 6.5%, 1.7%, and 1.0%, respectively. These results demonstrate PST's effectiveness as a simple, hardware-friendly enhancement for both detection and classification tasks.
Multivariate Conformal Selection
May 01, 2025



Selecting high-quality candidates from large datasets is critical in applications such as drug discovery, precision medicine, and alignment of large language models (LLMs). While Conformal Selection (CS) provides rigorous uncertainty quantification, it is limited to univariate responses and scalar criteria. To address this issue, we propose Multivariate Conformal Selection (mCS), a generalization of CS designed for multivariate response settings. Our method introduces regional monotonicity and employs multivariate nonconformity scores to construct conformal p-values, enabling finite-sample False Discovery Rate (FDR) control. We present two variants: mCS-dist, using distance-based scores, and mCS-learn, which learns optimal scores via differentiable optimization. Experiments on simulated and real-world datasets demonstrate that mCS significantly improves selection power while maintaining FDR control, establishing it as a robust framework for multivariate selection tasks.
Text-to-TrajVis: Enabling Trajectory Data Visualizations from Natural Language Questions
Apr 23, 2025This paper introduces the Text-to-TrajVis task, which aims to transform natural language questions into trajectory data visualizations, facilitating the development of natural language interfaces for trajectory visualization systems. As this is a novel task, there is currently no relevant dataset available in the community. To address this gap, we first devised a new visualization language called Trajectory Visualization Language (TVL) to facilitate querying trajectory data and generating visualizations. Building on this foundation, we further proposed a dataset construction method that integrates Large Language Models (LLMs) with human efforts to create high-quality data. Specifically, we first generate TVLs using a comprehensive and systematic process, and then label each TVL with corresponding natural language questions using LLMs. This process results in the creation of the first large-scale Text-to-TrajVis dataset, named TrajVL, which contains 18,140 (question, TVL) pairs. Based on this dataset, we systematically evaluated the performance of multiple LLMs (GPT, Qwen, Llama, etc.) on this task. The experimental results demonstrate that this task is both feasible and highly challenging and merits further exploration within the research community.
Optimized Conformal Selection: Powerful Selective Inference After Conformity Score Optimization
Nov 27, 2024



Model selection/optimization in conformal inference is challenging, since it may break the exchangeability between labeled and unlabeled data. We study this problem in the context of conformal selection, which uses conformal p-values to select ``interesting'' instances with large unobserved labels from a pool of unlabeled data, while controlling the FDR in finite sample. For validity, existing solutions require the model choice to be independent of the data used to construct the p-values and calibrate the selection set. However, when presented with many model choices and limited labeled data, it is desirable to (i) select the best model in a data-driven manner, and (ii) mitigate power loss due to sample splitting. This paper presents OptCS, a general framework that allows valid statistical testing (selection) after flexible data-driven model optimization. We introduce general conditions under which OptCS constructs valid conformal p-values despite substantial data reuse and handles complex p-value dependencies to maintain finite-sample FDR control via a novel multiple testing procedure. We instantiate this general recipe to propose three FDR-controlling procedures, each optimizing the models differently: (i) selecting the most powerful one among multiple pre-trained candidate models, (ii) using all data for model fitting without sample splitting, and (iii) combining full-sample model fitting and selection. We demonstrate the efficacy of our methods via simulation studies and real applications in drug discovery and alignment of large language models in radiology report generation.
Facility Location with Entrance Fees
Apr 24, 2022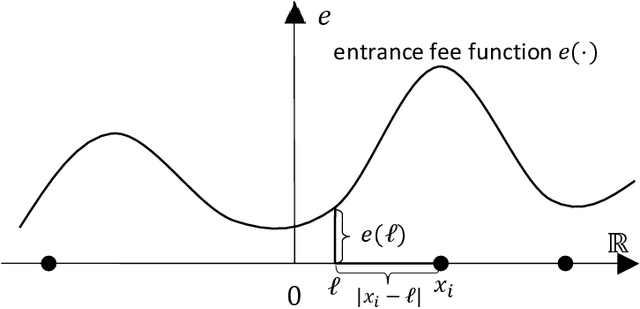
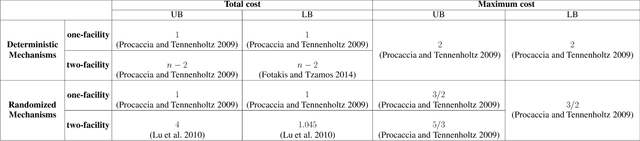

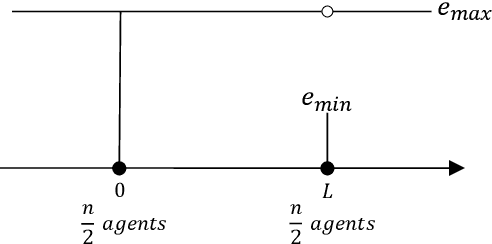
In mechanism design, the facility location game is an extensively studied problem. In the classical model, the cost of each agent is her distance to the nearest facility. In this paper, we consider a new model, where there is a location-dependent entrance fee to the facility. Thus, in our model, the cost of each agent is the sum of the distance to the facility and the entrance fee of the facility. This is a refined generalization of the classical model. We study the model and design strategyproof mechanisms. For one and two facilities, we provide upper and lower bounds for the approximation ratio given by deterministic and randomized mechanisms, with respect to the utilitarian objective and the egalitarian objective. Most of our bounds are tight and these bounds are independent of the entrance fee functions. Our results are as general as possible because the entrance fee function we consider is arbitrary.