 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRN: Fractal-Based Recursive Spectral Reconstruction Network
May 21, 2025



Generating hyperspectral images (HSIs) from RGB images through spectral reconstruction can significantly reduce the cost of HSI acquisition. In this paper, we propose a Fractal-Based Recursive Spectral Reconstruction Network (FRN), which differs from existing paradigms that attempt to directly integrate the full-spectrum information from the R, G, and B channels in a one-shot manner. Instead, it treats spectral reconstruction as a progressive process, predicting from broad to narrow bands or employing a coarse-to-fine approach for predicting the next wavelength. Inspired by fractals in mathematics, FRN establishes a novel spectral reconstruction paradigm by recursively invoking an atomic reconstruction module. In each invocation, only the spectral information from neighboring bands is used to provide clues for the generation of the image at the next wavelength, which follows the low-rank property of spectral data. Moreover, we design a band-aware state space model that employs a pixel-differentiated scanning strategy at different stages of the generation process, further suppressing interference from low-correlation regions caused by reflectance differences. Through extensive experimentation across different datasets, FRN achieves superior reconstruction performance compared to state-of-the-art methods in both quantitative and qualitative evaluations.
EfficientLLM: Efficiency in Large Language Models
May 20, 2025Large Language Models (LLMs) have driven significant progress, yet their growing parameter counts and context windows incur prohibitive compute, energy, and monetary costs. We introduce EfficientLLM, a novel benchmark and the first comprehensive empirical study evaluating efficiency techniques for LLMs at scale. Conducted on a production-class cluster (48xGH200, 8xH200 GPUs), our study systematically explores three key axes: (1) architecture pretraining (efficient attention variants: MQA, GQA, MLA, NSA; sparse Mixture-of-Experts (MoE)), (2) fine-tuning (parameter-efficient methods: LoRA, RSLoRA, DoRA), and (3) inference (quantization methods: int4, float16). We define six fine-grained metrics (Memory Utilization, Compute Utilization, Latency, Throughput, Energy Consumption, Compression Rate) to capture hardware saturation, latency-throughput balance, and carbon cost. Evaluating over 100 model-technique pairs (0.5B-72B parameters), we derive three core insights: (i) Efficiency involves quantifiable trade-offs: no single method is universally optimal; e.g., MoE reduces FLOPs and improves accuracy but increases VRAM by 40%, while int4 quantization cuts memory/energy by up to 3.9x at a 3-5% accuracy drop. (ii) Optima are task- and scale-dependent: MQA offers optimal memory-latency trade-offs for constrained devices, MLA achieves lowest perplexity for quality-critical tasks, and RSLoRA surpasses LoRA efficiency only beyond 14B parameters. (iii) Techniques generalize across modalities: we extend evaluations to Large Vision Models (Stable Diffusion 3.5, Wan 2.1) and Vision-Language Models (Qwen2.5-VL), confirming effective transferability. By open-sourcing datasets, evaluation pipelines, and leaderboards, EfficientLLM provides essential guidance for researchers and engineers navigating the efficiency-performance landscape of next-generation foundation models.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
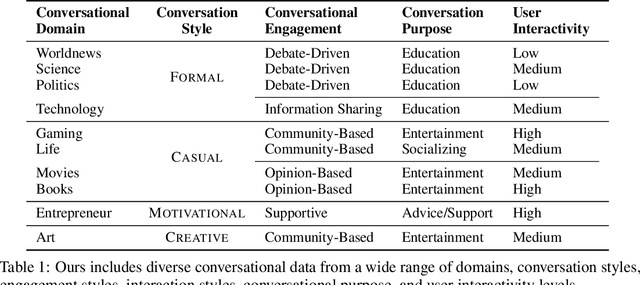


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
Single Image Reflection Removal via inter-layer Complementarity
May 19, 2025Although dual-stream architectures have achieved remarkable success in single image reflection removal, they fail to fully exploit inter-layer complementarity in their physical modeling and network design, which limits the quality of image separation. To address this fundamental limitation, we propose two targeted improvements to enhance dual-stream architectures: First, we introduce a novel inter-layer complementarity model where low-frequency components extracted from the residual layer interact with the transmission layer through dual-stream architecture to enhance inter-layer complementarity. Meanwhile, high-frequency components from the residual layer provide inverse modulation to both streams, improving the detail quality of the transmission layer. Second, we propose an efficient inter-layer complementarity attention mechanism which first cross-reorganizes dual streams at the channel level to obtain reorganized streams with inter-layer complementary structures, then performs attention computation on the reorganized streams to achieve better inter-layer separation, and finally restores the original stream structure for output. Experimental results demonstrate that our method achieves state-of-the-art separation quality on multiple public datasets while significantly reducing both computational cost and model complexity.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
Enhancing Systematic Reviews with Large Language Models: Using GPT-4 and Kimi
Apr 28, 2025
This research delved into GPT-4 and Kimi, two Large Language Models (LLMs), for systematic reviews. We evaluated their performance by comparing LLM-generated codes with human-generated codes from a peer-reviewed systematic review on assessment. Our findings suggested that the performance of LLMs fluctuates by data volume and question complexity for systematic reviews.
Pan-LUT: Efficient Pan-sharpening via Learnable Look-Up Tables
Mar 31, 2025



Recently, deep learning-based pan-sharpening algorithms have achieved notable advancements over traditional methods. However, many deep learning-based approaches incur substantial computational overhead during inference, especially with high-resolution images. This excessive computational demand limits the applicability of these methods in real-world scenarios, particularly in the absence of dedicated computing devices such as GPUs and TPUs. To address these challenges, we propose Pan-LUT, a novel learnable look-up table (LUT) framework for pan-sharpening that strikes a balance between performance and computational efficiency for high-resolution remote sensing images. To finely control the spectral transformation, we devise the PAN-guided look-up table (PGLUT) for channel-wise spectral mapping. To effectively capture fine-grained spatial details and adaptively learn local contexts, we introduce the spatial details look-up table (SDLUT) and adaptive aggregation look-up table (AALUT). Our proposed method contains fewer than 300K parameters and processes a 8K resolution image in under 1 ms using a single NVIDIA GeForce RTX 2080 Ti GPU, demonstrating significantly faster performance compared to other methods. Experiments reveal that Pan-LUT efficiently processes large remote sensing images in a lightweight manner, bridging the gap to real-world applications. Furthermore, our model surpasses SOTA methods in full-resolution scenes under real-world conditions, highlighting its effectiveness and efficiency.
OCRT: Boosting Foundation Models in the Open World with Object-Concept-Relation Triad
Mar 24, 2025Although foundation models (FMs) claim to be powerful, their generalization ability significantly decreases when faced with distribution shifts, weak supervision, or malicious attacks in the open world. On the other hand, most domain generalization or adversarial fine-tuning methods are task-related or model-specific, ignoring the universality in practical applications and the transferability between FMs. This paper delves into the problem of generalizing FMs to the out-of-domain data. We propose a novel framework, the Object-Concept-Relation Triad (OCRT), that enables FMs to extract sparse, high-level concepts and intricate relational structures from raw visual inputs. The key idea is to bind objects in visual scenes and a set of object-centric representations through unsupervised decoupling and iterative refinement. To be specific, we project the object-centric representations onto a semantic concept space that the model can readily interpret and estimate their importance to filter out irrelevant elements. Then, a concept-based graph, which has a flexible degree, is constructed to incorporate the set of concepts and their corresponding importance, enabling the extraction of high-order factors from informative concepts and facilitating relational reasoning among these concepts. Extensive experiments demonstrate that OCRT can substantially boost the generalizability and robustness of SAM and CLIP across multiple downstream tasks.
UPME: An Unsupervised Peer Review Framework for Multimodal Large Language Model Evaluation
Mar 19, 2025Multimodal Large Language Models (MLLMs) have emerged to tackle the challenges of Visual Question Answering (VQA), sparking a new research focus on conducting objective evaluations of these models. Existing evaluation methods face limitations due to the significant human workload required to design Q&A pairs for visual images, which inherently restricts the scale and scope of evaluations. Although automated MLLM-as-judge approaches attempt to reduce the human workload through automatic evaluations, they often introduce biases. To address these problems, we propose an Unsupervised Peer review MLLM Evaluation framework. It utilizes only image data, allowing models to automatically generate questions and conduct peer review assessments of answers from other models, effectively alleviating the reliance on human workload. Additionally, we introduce the vision-language scoring system to mitigate the bias issues, which focuses on three aspects: (i) response correctness; (ii) visual understanding and reasoning; and (iii) image-text correlation. Experimental results demonstrate that UPME achieves a Pearson correlation of 0.944 with human evaluations on the MMstar dataset and 0.814 on the ScienceQA dataset, indicating that our framework closely aligns with human-designed benchmarks and inherent human preferences.
Bridging Synthetic-to-Real Gaps: Frequency-Aware Perturbation and Selection for Single-shot Multi-Parametric Mapping Reconstruction
Mar 05, 2025Data-centric artificial intelligence (AI) has remarkably advanced medical imaging, with emerging methods using synthetic data to address data scarcity while introducing synthetic-to-real gaps. Unsupervised domain adaptation (UDA) shows promise in ground truth-scarce tasks, but its application in reconstruction remains underexplored. Although multiple overlapping-echo detachment (MOLED) achieves ultra-fast multi-parametric reconstruction, extending its application to various clinical scenarios, the quality suffers from deficiency in mitigating the domain gap, difficulty in maintaining structural integrity, and inadequacy in ensuring mapping accuracy. To resolve these issues, we proposed frequency-aware perturbation and selection (FPS), comprising Wasserstein distance-modulated frequency-aware perturbation (WDFP) and hierarchical frequency-aware selection network (HFSNet), which integrates frequency-aware adaptive selection (FAS), compact FAS (cFAS) and feature-aware architecture integration (FAI). Specifically, perturbation activates domain-invariant feature learning within uncertainty, while selection refines optimal solutions within perturbation, establishing a robust and closed-loop learning pathway. Extensive experiments on synthetic data, along with diverse real clinical cases from 5 healthy volunteers, 94 ischemic stroke patients, and 46 meningioma patients, demonstrate the superiority and clinical applicability of FPS. Furthermore, FPS is applied to diffusion tensor imaging (DTI), underscoring its versatility and potential for broader medical applications. The code is available at https://github.com/flyannie/FPS.