 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAGS: Open-Vocabulary 3D Scene Understanding with Context-Aware Gaussian Splatting
Apr 16, 2025Open-vocabulary 3D scene understanding is crucial for applications requiring natural language-driven spatial interpretation, such as robotics and augmented reality. While 3D Gaussian Splatting (3DGS) offers a powerful representation for scene reconstruction, integrating it with open-vocabulary frameworks reveals a key challenge: cross-view granularity inconsistency. This issue, stemming from 2D segmentation methods like SAM, results in inconsistent object segmentations across views (e.g., a "coffee set" segmented as a single entity in one view but as "cup + coffee + spoon" in another). Existing 3DGS-based methods often rely on isolated per-Gaussian feature learning, neglecting the spatial context needed for cohesive object reasoning, leading to fragmented representations. We propose Context-Aware Gaussian Splatting (CAGS), a novel framework that addresses this challenge by incorporating spatial context into 3DGS. CAGS constructs local graphs to propagate contextual features across Gaussians, reducing noise from inconsistent granularity, employs mask-centric contrastive learning to smooth SAM-derived features across views, and leverages a precomputation strategy to reduce computational cost by precomputing neighborhood relationships, enabling efficient training in large-scale scenes. By integrating spatial context, CAGS significantly improves 3D instance segmentation and reduces fragmentation errors on datasets like LERF-OVS and ScanNet, enabling robust language-guided 3D scene understanding.
RGL: A Graph-Centric, Modular Framework for Efficient Retrieval-Augmented Generation on Graphs
Mar 25, 2025Recent advances in graph learning have paved the way for innovative retrieval-augmented generation (RAG) systems that leverage the inherent relational structures in graph data. However, many existing approaches suffer from rigid, fixed settings and significant engineering overhead, limiting their adaptability and scalability. Additionally, the RAG community has largely overlooked the decades of research in the graph database community regarding the efficient retrieval of interesting substructures on large-scale graphs. In this work, we introduce the RAG-on-Graphs Library (RGL), a modular framework that seamlessly integrates the complete RAG pipeline-from efficient graph indexing and dynamic node retrieval to subgraph construction, tokenization, and final generation-into a unified system. RGL addresses key challenges by supporting a variety of graph formats and integrating optimized implementations for essential components, achieving speedups of up to 143x compared to conventional methods. Moreover, its flexible utilities, such as dynamic node filtering, allow for rapid extraction of pertinent subgraphs while reducing token consumption. Our extensive evaluations demonstrate that RGL not only accelerates the prototyping process but also enhances the performance and applicability of graph-based RAG systems across a range of tasks.
CADDreamer: CAD object Generation from Single-view Images
Feb 28, 2025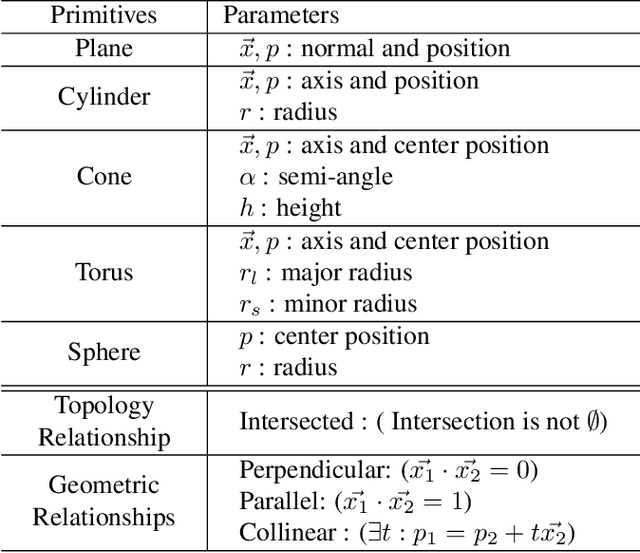
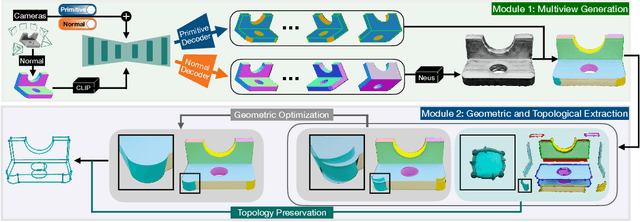

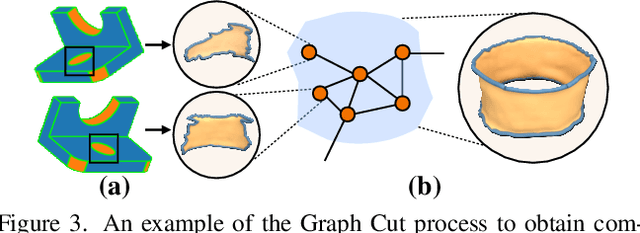
Diffusion-based 3D generation has made remarkable progress in recent years. However, existing 3D generative models often produce overly dense and unstructured meshes, which stand in stark contrast to the compact, structured, and sharply-edged Computer-Aided Design (CAD) models crafted by human designers. To address this gap, we introduce CADDreamer, a novel approach for generating boundary representations (B-rep) of CAD objects from a single image. CADDreamer employs a primitive-aware multi-view diffusion model that captures both local geometric details and high-level structural semantics during the generation process. By encoding primitive semantics into the color domain, the method leverages the strong priors of pre-trained diffusion models to align with well-defined primitives. This enables the inference of multi-view normal maps and semantic maps from a single image, facilitating the reconstruction of a mesh with primitive labels. Furthermore, we introduce geometric optimization techniques and topology-preserving extraction methods to mitigate noise and distortion in the generated primitives. These enhancements result in a complete and seamless B-rep of the CAD model. Experimental results demonstrate that our method effectively recovers high-quality CAD objects from single-view images. Compared to existing 3D generation techniques, the B-rep models produced by CADDreamer are compact in representation, clear in structure, sharp in edges, and watertight in topology.
Self-adaptive vision-language model for 3D segmentation of pulmonary artery and vein
Jan 07, 2025Accurate segmentation of pulmonary structures iscrucial in clinical diagnosis, disease study, and treatment planning. Significant progress has been made in deep learning-based segmentation techniques, but most require much labeled data for training. Consequently, developing precise segmentation methods that demand fewer labeled datasets is paramount in medical image analysis. The emergence of pre-trained vision-language foundation models, such as CLIP, recently opened the door for universal computer vision tasks. Exploiting the generalization ability of these pre-trained foundation models on downstream tasks, such as segmentation, leads to unexpected performance with a relatively small amount of labeled data. However, exploring these models for pulmonary artery-vein segmentation is still limited. This paper proposes a novel framework called Language-guided self-adaptive Cross-Attention Fusion Framework. Our method adopts pre-trained CLIP as a strong feature extractor for generating the segmentation of 3D CT scans, while adaptively aggregating the cross-modality of text and image representations. We propose a s pecially designed adapter module to fine-tune pre-trained CLIP with a self-adaptive learning strategy to effectively fuse the two modalities of embeddings. We extensively validate our method on a local dataset, which is the largest pulmonary artery-vein CT dataset to date and consists of 718 labeled data in total. The experiments show that our method outperformed other state-of-the-art methods by a large margin. Our data and code will be made publicly available upon acceptance.
Distilling Desired Comments for Enhanced Code Review with Large Language Models
Dec 29, 2024There has been a growing interest in using Large Language Models (LLMs) for code review thanks to their proven proficiency in code comprehension. The primary objective of most review scenarios is to generate desired review comments (DRCs) that explicitly identify issues to trigger code fixes. However, existing LLM-based solutions are not so effective in generating DRCs for various reasons such as hallucination. To enhance their code review ability, they need to be fine-tuned with a customized dataset that is ideally full of DRCs. Nevertheless, such a dataset is not yet available, while manual annotation of DRCs is too laborious to be practical. In this paper, we propose a dataset distillation method, Desiview, which can automatically construct a distilled dataset by identifying DRCs from a code review dataset. Experiments on the CodeReviewer dataset comprising more than 150K review entries show that Desiview achieves an impressive performance of 88.93%, 80.37%, 86.67%, and 84.44% in terms of Precision, Recall, Accuracy, and F1, respectively, surpassing state-of-the-art methods. To validate the effect of such a distilled dataset on enhancing LLMs' code review ability, we first fine-tune the latest LLaMA series (i.e., LLaMA 3 and LLaMA 3.1) to build model Desiview4FT. We then enhance the model training effect through KTO alignment by feeding those review comments identified as non-DRCs to the LLMs, resulting in model Desiview4FA. Verification results indicate that Desiview4FA slightly outperforms Desiview4FT, while both models have significantly improved against the base models in terms of generating DRCs. Human evaluation confirms that both models identify issues more accurately and tend to generate review comments that better describe the issues contained in the code than the base LLMs do.
VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
Dec 24, 2024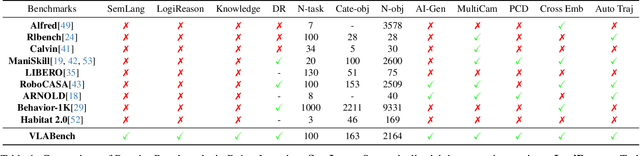
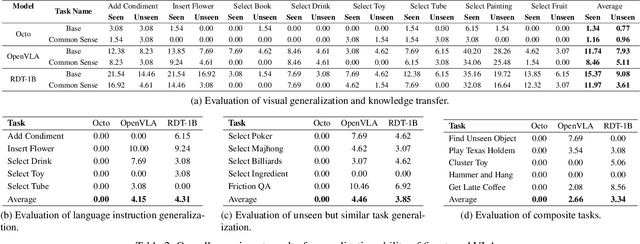

General-purposed embodied agents are designed to understand the users' natural instructions or intentions and act precisely to complete universal tasks. Recently, methods based on foundation models especially Vision-Language-Action models (VLAs) have shown a substantial potential to solve language-conditioned manipulation (LCM) tasks well. However, existing benchmarks do not adequately meet the needs of VLAs and relative algorithms. To better define such general-purpose tasks in the context of LLMs and advance the research in VLAs, we present VLABench, an open-source benchmark for evaluating universal LCM task learning. VLABench provides 100 carefully designed categories of tasks, with strong randomization in each category of task and a total of 2000+ objects. VLABench stands out from previous benchmarks in four key aspects: 1) tasks requiring world knowledge and common sense transfer, 2) natural language instructions with implicit human intentions rather than templates, 3) long-horizon tasks demanding multi-step reasoning, and 4) evaluation of both action policies and language model capabilities. The benchmark assesses multiple competencies including understanding of mesh\&texture, spatial relationship, semantic instruction, physical laws, knowledge transfer and reasoning, etc. To support the downstream finetuning, we provide high-quality training data collected via an automated framework incorporating heuristic skills and prior information. The experimental results indicate that both the current state-of-the-art pretrained VLAs and the workflow based on VLMs face challenges in our tasks.
IMNet: Interference-Aware Channel Knowledge Map Construction and Localization
Dec 02, 2024



This paper presents a novel two-stage method for constructing channel knowledge maps (CKMs) specifically for A2G (Aerial-to-Ground) channels in the presence of non-cooperative interfering nodes (INs). We first estimate the interfering signal strength (ISS) at sampling locations based on total received signal strength measurements and the desired communication signal strength (DSS) map constructed with environmental topology. Next, an ISS map construction network (IMNet) is proposed, where a negative value correction module is included to enable precise reconstruction. Subsequently, we further execute signal-to-interference-plus-noise ratio map construction and IN localization. Simulation results demonstrate lower construction error of the proposed IMNet compared to baselines in the presence of interference.
VLMimic: Vision Language Models are Visual Imitation Learner for Fine-grained Actions
Oct 29, 2024



Visual imitation learning (VIL) provides an efficient and intuitive strategy for robotic systems to acquire novel skills. Recent advancements in Vision Language Models (VLMs) have demonstrated remarkable performance in vision and language reasoning capabilities for VIL tasks. Despite the progress, current VIL methods naively employ VLMs to learn high-level plans from human videos, relying on pre-defined motion primitives for executing physical interactions, which remains a major bottleneck. In this work, we present VLMimic, a novel paradigm that harnesses VLMs to directly learn even fine-grained action levels, only given a limited number of human videos. Specifically, VLMimic first grounds object-centric movements from human videos, and learns skills using hierarchical constraint representations, facilitating the derivation of skills with fine-grained action levels from limited human videos. These skills are refined and updated through an iterative comparison strategy, enabling efficient adaptation to unseen environments. Our extensive experiments exhibit that our VLMimic, using only 5 human videos, yields significant improvements of over 27% and 21% in RLBench and real-world manipulation tasks, and surpasses baselines by over 37% in long-horizon tasks.
FedGraph: A Research Library and Benchmark for Federated Graph Learning
Oct 08, 2024



Federated graph learning is an emerging field with significant practical challenges. While many algorithms have been proposed to enhance model accuracy, their system performance, crucial for real-world deployment, is often overlooked. To address this gap, we present FedGraph, a research library designed for practical distributed deployment and benchmarking in federated graph learning. FedGraph supports a range of state-of-the-art methods and includes profiling tools for system performance evaluation, focusing on communication and computation costs during training. FedGraph can then facilitate the development of practical applications and guide the design of future algorithms.
SoccerNet 2024 Challenges Results
Sep 16, 2024



The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.