 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUMPL: Ray-Based Transformers for Universal Multi-View 2D to 3D Human Pose Lifting
Dec 17, 2025Estimating 3D human poses from 2D images remains challenging due to occlusions and projective ambiguity. Multi-view learning-based approaches mitigate these issues but often fail to generalize to real-world scenarios, as large-scale multi-view datasets with 3D ground truth are scarce and captured under constrained conditions. To overcome this limitation, recent methods rely on 2D pose estimation combined with 2D-to-3D pose lifting trained on synthetic data. Building on our previous MPL framework, we propose RUMPL, a transformer-based 3D pose lifter that introduces a 3D ray-based representation of 2D keypoints. This formulation makes the model independent of camera calibration and the number of views, enabling universal deployment across arbitrary multi-view configurations without retraining or fine-tuning. A new View Fusion Transformer leverages learned fused-ray tokens to aggregate information along rays, further improving multi-view consistency. Extensive experiments demonstrate that RUMPL reduces MPJPE by up to 53% compared to triangulation and over 60% compared to transformer-based image-representation baselines. Results on new benchmarks, including in-the-wild multi-view and multi-person datasets, confirm its robustness and scalability. The framework's source code is available at https://github.com/aghasemzadeh/OpenRUMPL
SoccerNet 2024 Challenges Results
Sep 16, 2024



The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
MPL: Lifting 3D Human Pose from Multi-view 2D Poses
Aug 20, 2024Estimating 3D human poses from 2D images is challenging due to occlusions and projective acquisition. Learning-based approaches have been largely studied to address this challenge, both in single and multi-view setups. These solutions however fail to generalize to real-world cases due to the lack of (multi-view) 'in-the-wild' images paired with 3D poses for training. For this reason, we propose combining 2D pose estimation, for which large and rich training datasets exist, and 2D-to-3D pose lifting, using a transformer-based network that can be trained from synthetic 2D-3D pose pairs. Our experiments demonstrate decreases up to 45% in MPJPE errors compared to the 3D pose obtained by triangulating the 2D poses. The framework's source code is available at https://github.com/aghasemzadeh/OpenMPL .
Self-Avatar Animation in Virtual Reality: Impact of Motion Signals Artifacts on the Full-Body Pose Reconstruction
Apr 29, 2024



Virtual Reality (VR) applications have revolutionized user experiences by immersing individuals in interactive 3D environments. These environments find applications in numerous fields, including healthcare, education, or architecture. A significant aspect of VR is the inclusion of self-avatars, representing users within the virtual world, which enhances interaction and embodiment. However, generating lifelike full-body self-avatar animations remains challenging, particularly in consumer-grade VR systems, where lower-body tracking is often absent. One method to tackle this problem is by providing an external source of motion information that includes lower body information such as full Cartesian positions estimated from RGB(D) cameras. Nevertheless, the limitations of these systems are multiples: the desynchronization between the two motion sources and occlusions are examples of significant issues that hinder the implementations of such systems. In this paper, we aim to measure the impact on the reconstruction of the articulated self-avatar's full-body pose of (1) the latency between the VR motion features and estimated positions, (2) the data acquisition rate, (3) occlusions, and (4) the inaccuracy of the position estimation algorithm. In addition, we analyze the motion reconstruction errors using ground truth and 3D Cartesian coordinates estimated from \textit{YOLOv8} pose estimation. These analyzes show that the studied methods are significantly sensitive to any degradation tested, especially regarding the velocity reconstruction error.
SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap
Apr 17, 2024



Tracking and identifying athletes on the pitch holds a central role in collecting essential insights from the game, such as estimating the total distance covered by players or understanding team tactics. This tracking and identification process is crucial for reconstructing the game state, defined by the athletes' positions and identities on a 2D top-view of the pitch, (i.e. a minimap). However, reconstructing the game state from videos captured by a single camera is challenging. It requires understanding the position of the athletes and the viewpoint of the camera to localize and identify players within the field. In this work, we formalize the task of Game State Reconstruction and introduce SoccerNet-GSR, a novel Game State Reconstruction dataset focusing on football videos. SoccerNet-GSR is composed of 200 video sequences of 30 seconds, annotated with 9.37 million line points for pitch localization and camera calibration, as well as over 2.36 million athlete positions on the pitch with their respective role, team, and jersey number. Furthermore, we introduce GS-HOTA, a novel metric to evaluate game state reconstruction methods. Finally, we propose and release an end-to-end baseline for game state reconstruction, bootstrapping the research on this task. Our experiments show that GSR is a challenging novel task, which opens the field for future research. Our dataset and codebase are publicly available at https://github.com/SoccerNet/sn-gamestate.
DeepSportLab: a Unified Framework for Ball Detection, Player Instance Segmentation and Pose Estimation in Team Sports Scenes
Dec 01, 2021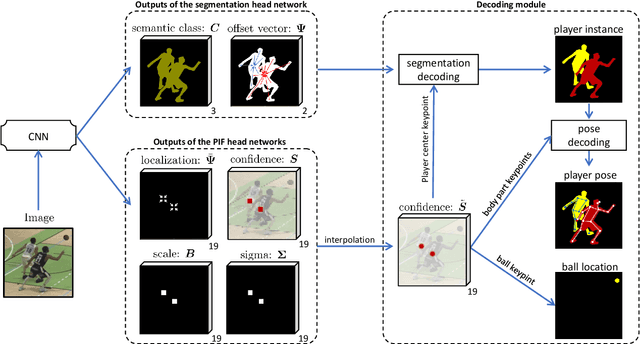
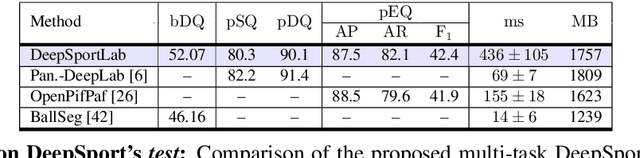
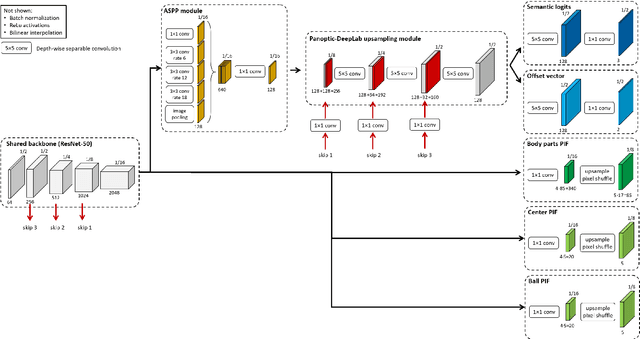
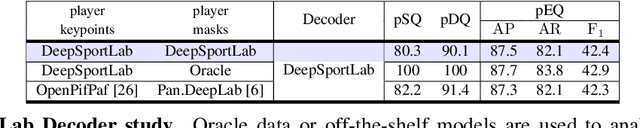
This paper presents a unified framework to (i) locate the ball, (ii) predict the pose, and (iii) segment the instance mask of players in team sports scenes. Those problems are of high interest in automated sports analytics, production, and broadcast. A common practice is to individually solve each problem by exploiting universal state-of-the-art models, \eg, Panoptic-DeepLab for player segmentation. In addition to the increased complexity resulting from the multiplication of single-task models, the use of the off-the-shelf models also impedes the performance due to the complexity and specificity of the team sports scenes, such as strong occlusion and motion blur. To circumvent those limitations, our paper proposes to train a single model that simultaneously predicts the ball and the player mask and pose by combining the part intensity fields and the spatial embeddings principles. Part intensity fields provide the ball and player location, as well as player joints location. Spatial embeddings are then exploited to associate player instance pixels to their respective player center, but also to group player joints into skeletons. We demonstrate the effectiveness of the proposed model on the DeepSport basketball dataset, achieving comparable performance to the SoA models addressing each individual task separately.
BRDS: An FPGA-based LSTM Accelerator with Row-Balanced Dual-Ratio Sparsification
Jan 07, 2021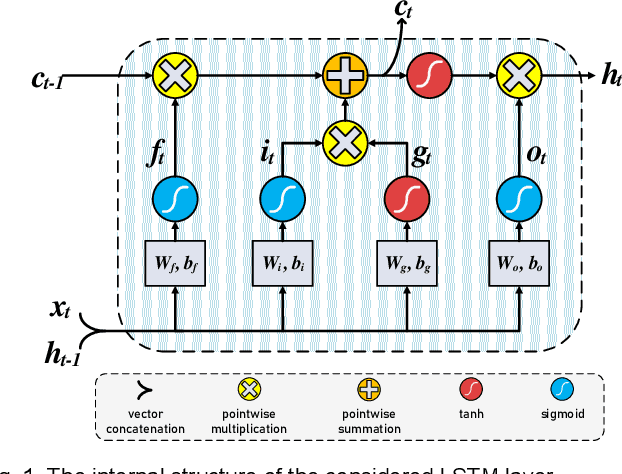

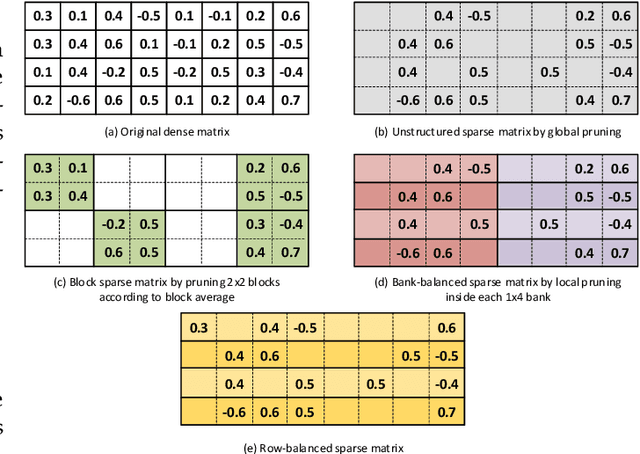
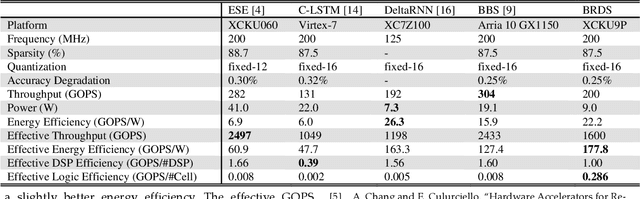
In this paper, first, a hardware-friendly pruning algorithm for reducing energy consumption and improving the speed of Long Short-Term Memory (LSTM) neural network accelerators is presented. Next, an FPGA-based platform for efficient execution of the pruned networks based on the proposed algorithm is introduced. By considering the sensitivity of two weight matrices of the LSTM models in pruning, different sparsity ratios (i.e., dual-ratio sparsity) are applied to these weight matrices. To reduce memory accesses, a row-wise sparsity pattern is adopted. The proposed hardware architecture makes use of computation overlapping and pipelining to achieve low-power and high-speed. The effectiveness of the proposed pruning algorithm and accelerator is assessed under some benchmarks for natural language processing, binary sentiment classification, and speech recognition. Results show that, e.g., compared to a recently published work in this field, the proposed accelerator could provide up to 272% higher effective GOPS/W and the perplexity error is reduced by up to 1.4% for the PTB dataset.