 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
CAMELTrack: Context-Aware Multi-cue ExpLoitation for Online Multi-Object Tracking
May 02, 2025Online multi-object tracking has been recently dominated by tracking-by-detection (TbD) methods, where recent advances rely on increasingly sophisticated heuristics for tracklet representation, feature fusion, and multi-stage matching. The key strength of TbD lies in its modular design, enabling the integration of specialized off-the-shelf models like motion predictors and re-identification. However, the extensive usage of human-crafted rules for temporal associations makes these methods inherently limited in their ability to capture the complex interplay between various tracking cues. In this work, we introduce CAMEL, a novel association module for Context-Aware Multi-Cue ExpLoitation, that learns resilient association strategies directly from data, breaking free from hand-crafted heuristics while maintaining TbD's valuable modularity. At its core, CAMEL employs two transformer-based modules and relies on a novel association-centric training scheme to effectively model the complex interactions between tracked targets and their various association cues. Unlike end-to-end detection-by-tracking approaches, our method remains lightweight and fast to train while being able to leverage external off-the-shelf models. Our proposed online tracking pipeline, CAMELTrack, achieves state-of-the-art performance on multiple tracking benchmarks. Our code is available at https://github.com/TrackingLaboratory/CAMELTrack.
SoccerNet 2024 Challenges Results
Sep 16, 2024



The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap
Apr 17, 2024



Tracking and identifying athletes on the pitch holds a central role in collecting essential insights from the game, such as estimating the total distance covered by players or understanding team tactics. This tracking and identification process is crucial for reconstructing the game state, defined by the athletes' positions and identities on a 2D top-view of the pitch, (i.e. a minimap). However, reconstructing the game state from videos captured by a single camera is challenging. It requires understanding the position of the athletes and the viewpoint of the camera to localize and identify players within the field. In this work, we formalize the task of Game State Reconstruction and introduce SoccerNet-GSR, a novel Game State Reconstruction dataset focusing on football videos. SoccerNet-GSR is composed of 200 video sequences of 30 seconds, annotated with 9.37 million line points for pitch localization and camera calibration, as well as over 2.36 million athlete positions on the pitch with their respective role, team, and jersey number. Furthermore, we introduce GS-HOTA, a novel metric to evaluate game state reconstruction methods. Finally, we propose and release an end-to-end baseline for game state reconstruction, bootstrapping the research on this task. Our experiments show that GSR is a challenging novel task, which opens the field for future research. Our dataset and codebase are publicly available at https://github.com/SoccerNet/sn-gamestate.
How semantic and geometric information mutually reinforce each other in ToF object localization
Aug 27, 2020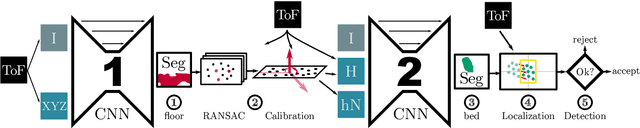

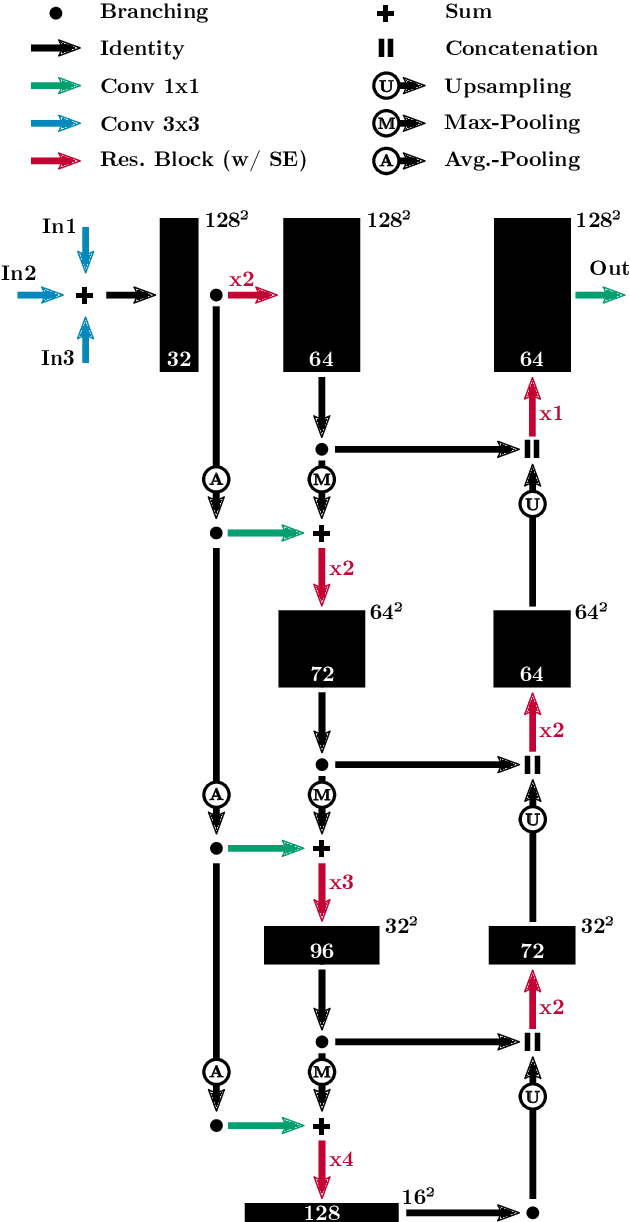
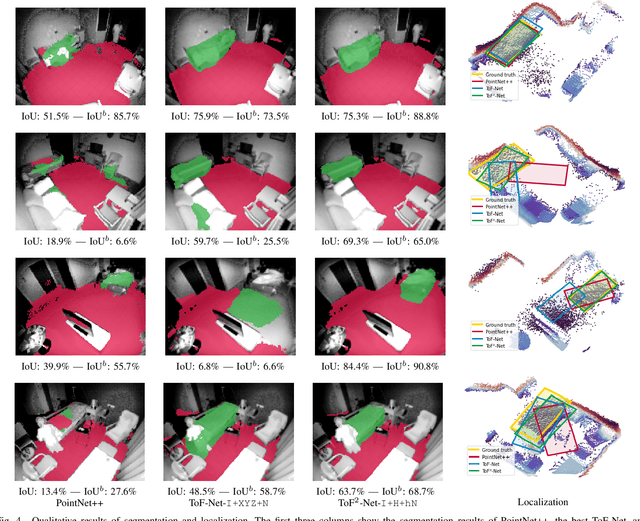
We propose a novel approach to localize a 3D object from the intensity and depth information images provided by a Time-of-Flight (ToF) sensor. Our method uses two CNNs. The first one uses raw depth and intensity images as input, to segment the floor pixels, from which the extrinsic parameters of the camera are estimated. The second CNN is in charge of segmenting the object-of-interest. As a main innovation, it exploits the calibration estimated from the prediction of the first CNN to represent the geometric depth information in a coordinate system that is attached to the ground, and is thus independent of the camera elevation. In practice, both the height of pixels with respect to the ground, and the orientation of normals to the point cloud are provided as input to the second CNN. Given the segmentation predicted by the second CNN, the object is localized based on point cloud alignment with a reference model. Our experiments demonstrate that our proposed two-step approach improves segmentation and localization accuracy by a significant margin compared to a conventional CNN architecture, ignoring calibration and height maps, but also compared to PointNet++.