 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving More with Less: Additive Prompt Tuning for Rehearsal-Free Class-Incremental Learning
Mar 11, 2025



Class-incremental learning (CIL) enables models to learn new classes progressively while preserving knowledge of previously learned ones. Recent advances in this field have shifted towards parameter-efficient fine-tuning techniques, with many approaches building upon the framework that maintains a pool of learnable prompts. Although effective, these methods introduce substantial computational overhead, primarily due to prompt pool querying and increased input sequence lengths from prompt concatenation. In this work, we present a novel prompt-based approach that addresses this limitation. Our method trains a single set of shared prompts across all tasks and, rather than concatenating prompts to the input, directly modifies the CLS token's attention computation by adding the prompts to it. This simple and lightweight design not only significantly reduces computational complexity-both in terms of inference costs and the number of trainable parameters-but also eliminates the need to optimize prompt lengths for different downstream tasks, offering a more efficient yet powerful solution for rehearsal-free class-incremental learning. Extensive experiments across a diverse range of CIL benchmarks demonstrate the effectiveness of our approach, highlighting its potential to establish a new prompt-based CIL paradigm. Furthermore, experiments on general recognition benchmarks beyond the CIL setting also show strong performance, positioning our method as a promising candidate for a general parameter-efficient fine-tuning approach.
AniGaussian: Animatable Gaussian Avatar with Pose-guided Deformation
Feb 24, 2025



Recent advancements in Gaussian-based human body reconstruction have achieved notable success in creating animatable avatars. However, there are ongoing challenges to fully exploit the SMPL model's prior knowledge and enhance the visual fidelity of these models to achieve more refined avatar reconstructions. In this paper, we introduce AniGaussian which addresses the above issues with two insights. First, we propose an innovative pose guided deformation strategy that effectively constrains the dynamic Gaussian avatar with SMPL pose guidance, ensuring that the reconstructed model not only captures the detailed surface nuances but also maintains anatomical correctness across a wide range of motions. Second, we tackle the expressiveness limitations of Gaussian models in representing dynamic human bodies. We incorporate rigid-based priors from previous works to enhance the dynamic transform capabilities of the Gaussian model. Furthermore, we introduce a split-with-scale strategy that significantly improves geometry quality. The ablative study experiment demonstrates the effectiveness of our innovative model design. Through extensive comparisons with existing methods, AniGaussian demonstrates superior performance in both qualitative result and quantitative metrics.
Human2Robot: Learning Robot Actions from Paired Human-Robot Videos
Feb 23, 2025



Distilling knowledge from human demonstrations is a promising way for robots to learn and act. Existing work often overlooks the differences between humans and robots, producing unsatisfactory results. In this paper, we study how perfectly aligned human-robot pairs benefit robot learning. Capitalizing on VR-based teleportation, we introduce H\&R, a third-person dataset with 2,600 episodes, each of which captures the fine-grained correspondence between human hands and robot gripper. Inspired by the recent success of diffusion models, we introduce Human2Robot, an end-to-end diffusion framework that formulates learning from human demonstrates as a generative task. Human2Robot fully explores temporal dynamics in human videos to generate robot videos and predict actions at the same time. Through comprehensive evaluations of 8 seen, changed and unseen tasks in real-world settings, we demonstrate that Human2Robot can not only generate high-quality robot videos but also excel in seen tasks and generalize to unseen objects, backgrounds and even new tasks effortlessly.
AIM: Additional Image Guided Generation of Transferable Adversarial Attacks
Jan 02, 2025Transferable adversarial examples highlight the vulnerability of deep neural networks (DNNs) to imperceptible perturbations across various real-world applications. While there have been notable advancements in untargeted transferable attacks, targeted transferable attacks remain a significant challenge. In this work, we focus on generative approaches for targeted transferable attacks. Current generative attacks focus on reducing overfitting to surrogate models and the source data domain, but they often overlook the importance of enhancing transferability through additional semantics. To address this issue, we introduce a novel plug-and-play module into the general generator architecture to enhance adversarial transferability. Specifically, we propose a \emph{Semantic Injection Module} (SIM) that utilizes the semantics contained in an additional guiding image to improve transferability. The guiding image provides a simple yet effective method to incorporate target semantics from the target class to create targeted and highly transferable attacks. Additionally, we propose new loss formulations that can integrate the semantic injection module more effectively for both targeted and untargeted attacks. We conduct comprehensive experiments under both targeted and untargeted attack settings to demonstrate the efficacy of our proposed approach.
DuMo: Dual Encoder Modulation Network for Precise Concept Erasure
Jan 02, 2025



The exceptional generative capability of text-to-image models has raised substantial safety concerns regarding the generation of Not-Safe-For-Work (NSFW) content and potential copyright infringement. To address these concerns, previous methods safeguard the models by eliminating inappropriate concepts. Nonetheless, these models alter the parameters of the backbone network and exert considerable influences on the structural (low-frequency) components of the image, which undermines the model's ability to retain non-target concepts. In this work, we propose our Dual encoder Modulation network (DuMo), which achieves precise erasure of inappropriate target concepts with minimum impairment to non-target concepts. In contrast to previous methods, DuMo employs the Eraser with PRior Knowledge (EPR) module which modifies the skip connection features of the U-NET and primarily achieves concept erasure on details (high-frequency) components of the image. To minimize the damage to non-target concepts during erasure, the parameters of the backbone U-NET are frozen and the prior knowledge from the original skip connection features is introduced to the erasure process. Meanwhile, the phenomenon is observed that distinct erasing preferences for the image structure and details are demonstrated by the EPR at different timesteps and layers. Therefore, we adopt a novel Time-Layer MOdulation process (TLMO) that adjusts the erasure scale of EPR module's outputs across different layers and timesteps, automatically balancing the erasure effects and model's generative ability. Our method achieves state-of-the-art performance on Explicit Content Erasure, Cartoon Concept Removal and Artistic Style Erasure, clearly outperforming alternative methods. Code is available at https://github.com/Maplebb/DuMo
4D Gaussian Splatting: Modeling Dynamic Scenes with Native 4D Primitives
Dec 30, 2024



Dynamic 3D scene representation and novel view synthesis from captured videos are crucial for enabling immersive experiences required by AR/VR and metaverse applications. However, this task is challenging due to the complexity of unconstrained real-world scenes and their temporal dynamics. In this paper, we frame dynamic scenes as a spatio-temporal 4D volume learning problem, offering a native explicit reformulation with minimal assumptions about motion, which serves as a versatile dynamic scene learning framework. Specifically, we represent a target dynamic scene using a collection of 4D Gaussian primitives with explicit geometry and appearance features, dubbed as 4D Gaussian splatting (4DGS). This approach can capture relevant information in space and time by fitting the underlying spatio-temporal volume. Modeling the spacetime as a whole with 4D Gaussians parameterized by anisotropic ellipses that can rotate arbitrarily in space and time, our model can naturally learn view-dependent and time-evolved appearance with 4D spherindrical harmonics. Notably, our 4DGS model is the first solution that supports real-time rendering of high-resolution, photorealistic novel views for complex dynamic scenes. To enhance efficiency, we derive several compact variants that effectively reduce memory footprint and mitigate the risk of overfitting. Extensive experiments validate the superiority of 4DGS in terms of visual quality and efficiency across a range of dynamic scene-related tasks (e.g., novel view synthesis, 4D generation, scene understanding) and scenarios (e.g., single object, indoor scenes, driving environments, synthetic and real data).
STNMamba: Mamba-based Spatial-Temporal Normality Learning for Video Anomaly Detection
Dec 28, 2024Video anomaly detection (VAD) has been extensively researched due to its potential for intelligent video systems. However, most existing methods based on CNNs and transformers still suffer from substantial computational burdens and have room for improvement in learning spatial-temporal normality. Recently, Mamba has shown great potential for modeling long-range dependencies with linear complexity, providing an effective solution to the above dilemma. To this end, we propose a lightweight and effective Mamba-based network named STNMamba, which incorporates carefully designed Mamba modules to enhance the learning of spatial-temporal normality. Firstly, we develop a dual-encoder architecture, where the spatial encoder equipped with Multi-Scale Vision Space State Blocks (MS-VSSB) extracts multi-scale appearance features, and the temporal encoder employs Channel-Aware Vision Space State Blocks (CA-VSSB) to capture significant motion patterns. Secondly, a Spatial-Temporal Interaction Module (STIM) is introduced to integrate spatial and temporal information across multiple levels, enabling effective modeling of intrinsic spatial-temporal consistency. Within this module, the Spatial-Temporal Fusion Block (STFB) is proposed to fuse the spatial and temporal features into a unified feature space, and the memory bank is utilized to store spatial-temporal prototypes of normal patterns, restricting the model's ability to represent anomalies. Extensive experiments on three benchmark datasets demonstrate that our STNMamba achieves competitive performance with fewer parameters and lower computational costs than existing methods.
VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
Dec 24, 2024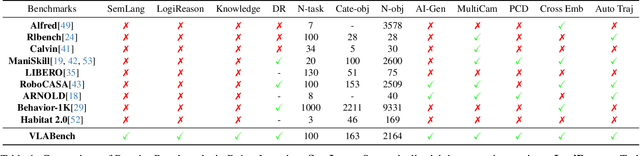
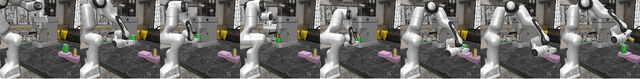

General-purposed embodied agents are designed to understand the users' natural instructions or intentions and act precisely to complete universal tasks. Recently, methods based on foundation models especially Vision-Language-Action models (VLAs) have shown a substantial potential to solve language-conditioned manipulation (LCM) tasks well. However, existing benchmarks do not adequately meet the needs of VLAs and relative algorithms. To better define such general-purpose tasks in the context of LLMs and advance the research in VLAs, we present VLABench, an open-source benchmark for evaluating universal LCM task learning. VLABench provides 100 carefully designed categories of tasks, with strong randomization in each category of task and a total of 2000+ objects. VLABench stands out from previous benchmarks in four key aspects: 1) tasks requiring world knowledge and common sense transfer, 2) natural language instructions with implicit human intentions rather than templates, 3) long-horizon tasks demanding multi-step reasoning, and 4) evaluation of both action policies and language model capabilities. The benchmark assesses multiple competencies including understanding of mesh\&texture, spatial relationship, semantic instruction, physical laws, knowledge transfer and reasoning, etc. To support the downstream finetuning, we provide high-quality training data collected via an automated framework incorporating heuristic skills and prior information. The experimental results indicate that both the current state-of-the-art pretrained VLAs and the workflow based on VLMs face challenges in our tasks.
Comprehensive Multi-Modal Prototypes are Simple and Effective Classifiers for Vast-Vocabulary Object Detection
Dec 23, 2024



Enabling models to recognize vast open-world categories has been a longstanding pursuit in object detection. By leveraging the generalization capabilities of vision-language models, current open-world detectors can recognize a broader range of vocabularies, despite being trained on limited categories. However, when the scale of the category vocabularies during training expands to a real-world level, previous classifiers aligned with coarse class names significantly reduce the recognition performance of these detectors. In this paper, we introduce Prova, a multi-modal prototype classifier for vast-vocabulary object detection. Prova extracts comprehensive multi-modal prototypes as initialization of alignment classifiers to tackle the vast-vocabulary object recognition failure problem. On V3Det, this simple method greatly enhances the performance among one-stage, two-stage, and DETR-based detectors with only additional projection layers in both supervised and open-vocabulary settings. In particular, Prova improves Faster R-CNN, FCOS, and DINO by 3.3, 6.2, and 2.9 AP respectively in the supervised setting of V3Det. For the open-vocabulary setting, Prova achieves a new state-of-the-art performance with 32.8 base AP and 11.0 novel AP, which is of 2.6 and 4.3 gain over the previous methods.
CreatiLayout: Siamese Multimodal Diffusion Transformer for Creative Layout-to-Image Generation
Dec 05, 2024



Diffusion models have been recognized for their ability to generate images that are not only visually appealing but also of high artistic quality. As a result, Layout-to-Image (L2I) generation has been proposed to leverage region-specific positions and descriptions to enable more precise and controllable generation. However, previous methods primarily focus on UNet-based models (e.g., SD1.5 and SDXL), and limited effort has explored Multimodal Diffusion Transformers (MM-DiTs), which have demonstrated powerful image generation capabilities. Enabling MM-DiT for layout-to-image generation seems straightforward but is challenging due to the complexity of how layout is introduced, integrated, and balanced among multiple modalities. To this end, we explore various network variants to efficiently incorporate layout guidance into MM-DiT, and ultimately present SiamLayout. To Inherit the advantages of MM-DiT, we use a separate set of network weights to process the layout, treating it as equally important as the image and text modalities. Meanwhile, to alleviate the competition among modalities, we decouple the image-layout interaction into a siamese branch alongside the image-text one and fuse them in the later stage. Moreover, we contribute a large-scale layout dataset, named LayoutSAM, which includes 2.7 million image-text pairs and 10.7 million entities. Each entity is annotated with a bounding box and a detailed description. We further construct the LayoutSAM-Eval benchmark as a comprehensive tool for evaluating the L2I generation quality. Finally, we introduce the Layout Designer, which taps into the potential of large language models in layout planning, transforming them into experts in layout generation and optimization. Our code, model, and dataset will be available at https://creatilayout.github.io.