 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLottery Jackpots Exist in Pre-trained Models
Apr 18, 2021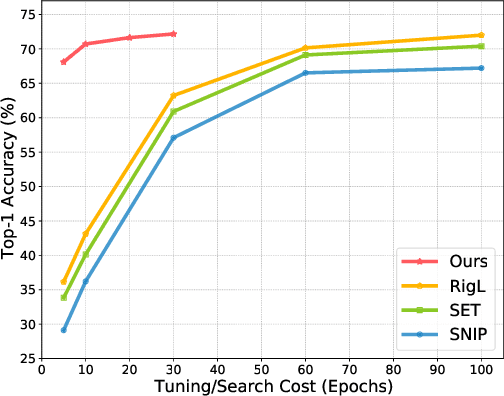
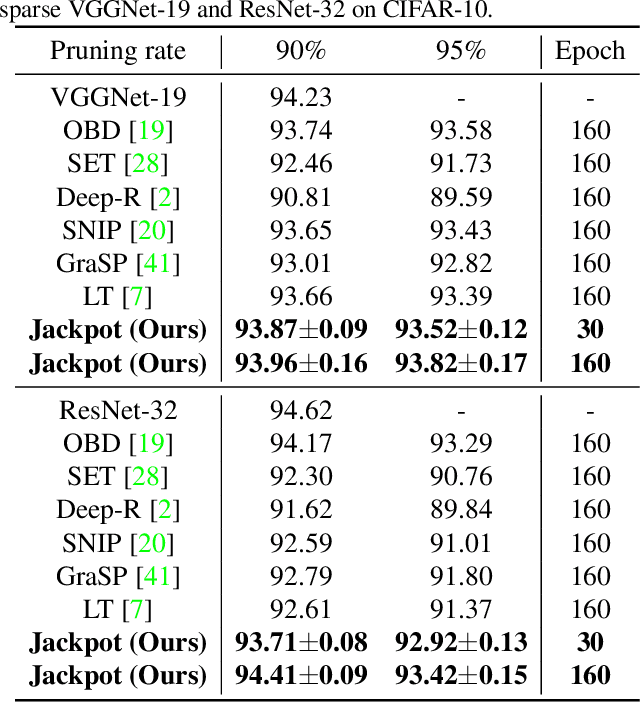
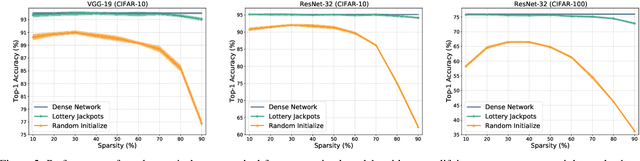
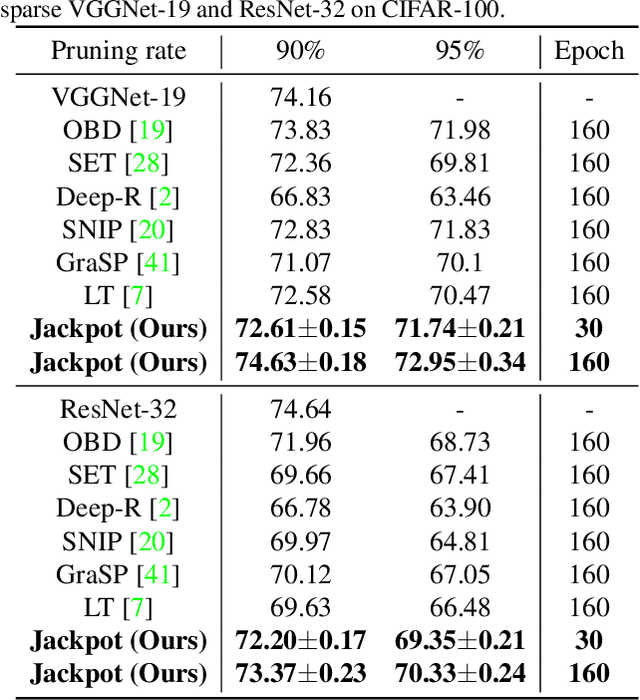
Network pruning is an effective approach to reduce network complexity without performance compromise. Existing studies achieve the sparsity of neural networks via time-consuming weight tuning or complex search on networks with expanded width, which greatly limits the applications of network pruning. In this paper, we show that high-performing and sparse sub-networks without the involvement of weight tuning, termed "lottery jackpots", exist in pre-trained models with unexpanded width. For example, we obtain a lottery jackpot that has only 10% parameters and still reaches the performance of the original dense VGGNet-19 without any modifications on the pre-trained weights. Furthermore, we observe that the sparse masks derived from many existing pruning criteria have a high overlap with the searched mask of our lottery jackpot, among which, the magnitude-based pruning results in the most similar mask with ours. Based on this insight, we initialize our sparse mask using the magnitude pruning, resulting in at least 3x cost reduction on the lottery jackpot search while achieves comparable or even better performance. Specifically, our magnitude-based lottery jackpot removes 90% weights in the ResNet-50, while easily obtains more than 70% top-1 accuracy using only 10 searching epochs on ImageNet.
Distilling a Powerful Student Model via Online Knowledge Distillation
Mar 29, 2021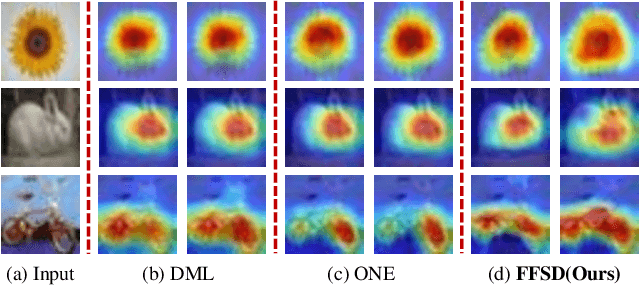
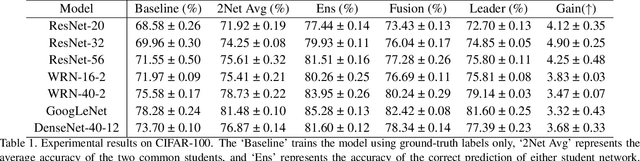
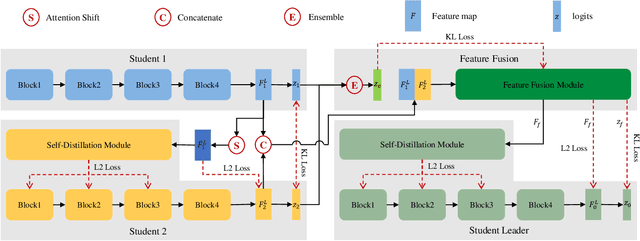
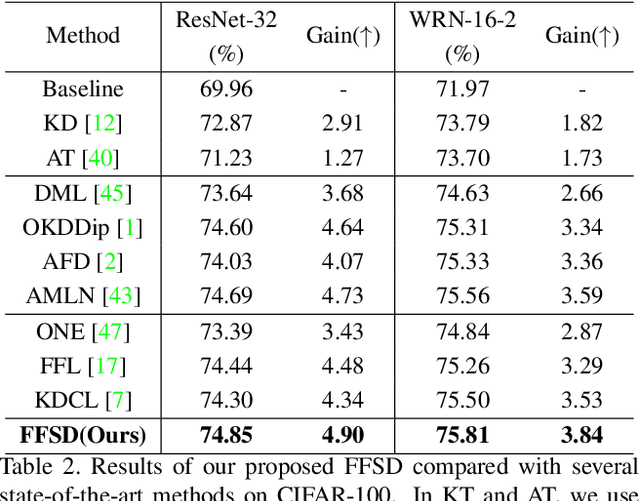
Existing online knowledge distillation approaches either adopt the student with the best performance or construct an ensemble model for better holistic performance. However, the former strategy ignores other students' information, while the latter increases the computational complexity. In this paper, we propose a novel method for online knowledge distillation, termed FFSD, which comprises two key components: Feature Fusion and Self-Distillation, towards solving the above problems in a unified framework. Different from previous works, where all students are treated equally, the proposed FFSD splits them into a student leader and a common student set. Then, the feature fusion module converts the concatenation of feature maps from all common students into a fused feature map. The fused representation is used to assist the learning of the student leader. To enable the student leader to absorb more diverse information, we design an enhancement strategy to increase the diversity among students. Besides, a self-distillation module is adopted to convert the feature map of deeper layers into a shallower one. Then, the shallower layers are encouraged to mimic the transformed feature maps of the deeper layers, which helps the students to generalize better. After training, we simply adopt the student leader, which achieves superior performance, over the common students, without increasing the storage or inference cost. Extensive experiments on CIFAR-100 and ImageNet demonstrate the superiority of our FFSD over existing works. The code is available at https://github.com/SJLeo/FFSD.
Image-to-image Translation via Hierarchical Style Disentanglement
Mar 02, 2021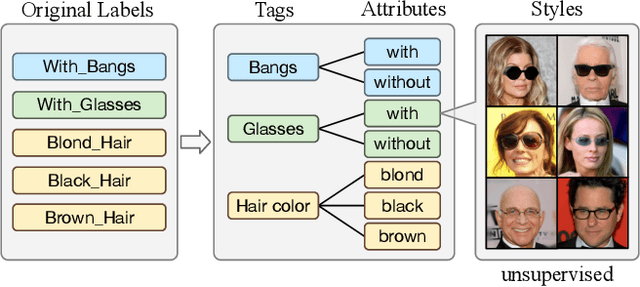


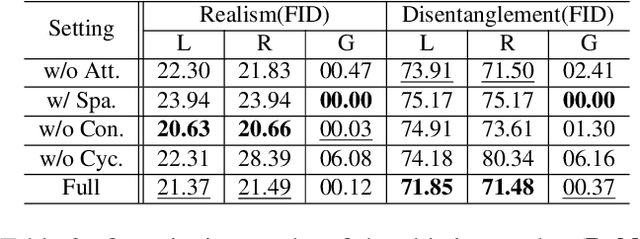
Recently, image-to-image translation has made significant progress in achieving both multi-label (\ie, translation conditioned on different labels) and multi-style (\ie, generation with diverse styles) tasks. However, due to the unexplored independence and exclusiveness in the labels, existing endeavors are defeated by involving uncontrolled manipulations to the translation results. In this paper, we propose Hierarchical Style Disentanglement (HiSD) to address this issue. Specifically, we organize the labels into a hierarchical tree structure, in which independent tags, exclusive attributes, and disentangled styles are allocated from top to bottom. Correspondingly, a new translation process is designed to adapt the above structure, in which the styles are identified for controllable translations. Both qualitative and quantitative results on the CelebA-HQ dataset verify the ability of the proposed HiSD. We hope our method will serve as a solid baseline and provide fresh insights with the hierarchically organized annotations for future research in image-to-image translation. The code has been released at https://github.com/imlixinyang/HiSD.
Non-Parametric Adaptive Network Pruning
Jan 25, 2021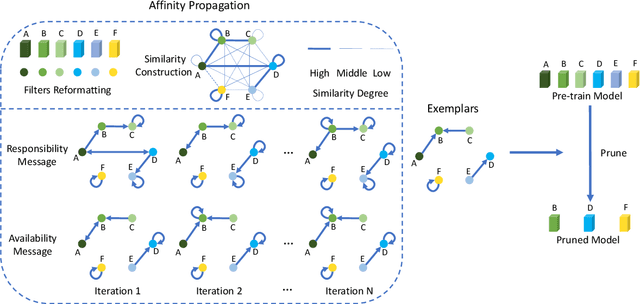
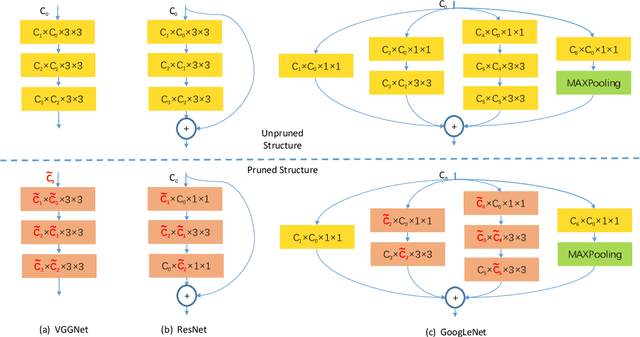
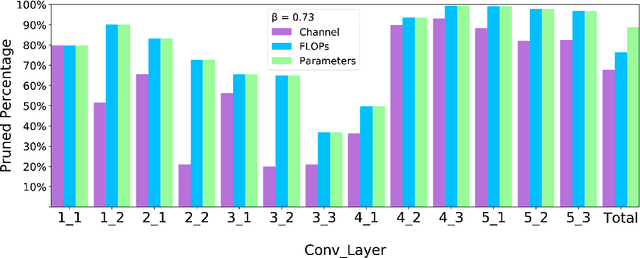
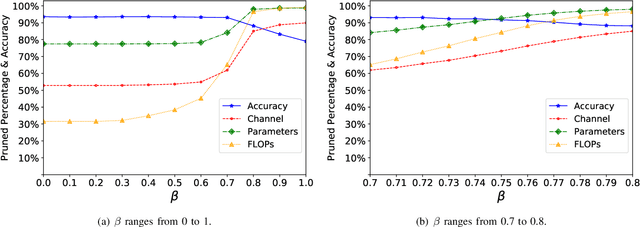
Popular network pruning algorithms reduce redundant information by optimizing hand-crafted parametric models, and may cause suboptimal performance and long time in selecting filters. We innovatively introduce non-parametric modeling to simplify the algorithm design, resulting in an automatic and efficient pruning approach called EPruner. Inspired by the face recognition community, we use a message passing algorithm Affinity Propagation on the weight matrices to obtain an adaptive number of exemplars, which then act as the preserved filters. EPruner breaks the dependency on the training data in determining the "important" filters and allows the CPU implementation in seconds, an order of magnitude faster than GPU based SOTAs. Moreover, we show that the weights of exemplars provide a better initialization for the fine-tuning. On VGGNet-16, EPruner achieves a 76.34%-FLOPs reduction by removing 88.80% parameters, with 0.06% accuracy improvement on CIFAR-10. In ResNet-152, EPruner achieves a 65.12%-FLOPs reduction by removing 64.18% parameters, with only 0.71% top-5 accuracy loss on ILSVRC-2012. Code can be available at https://github.com/lmbxmu/EPruner.
Dual-Level Collaborative Transformer for Image Captioning
Jan 16, 2021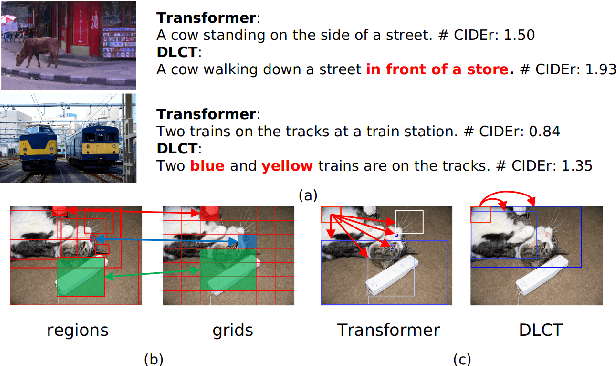
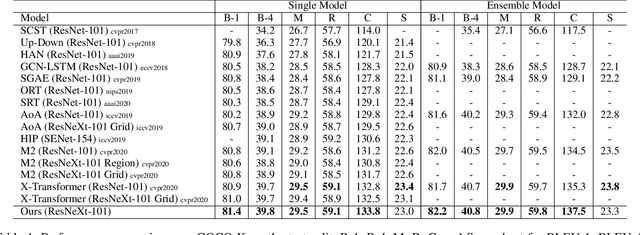
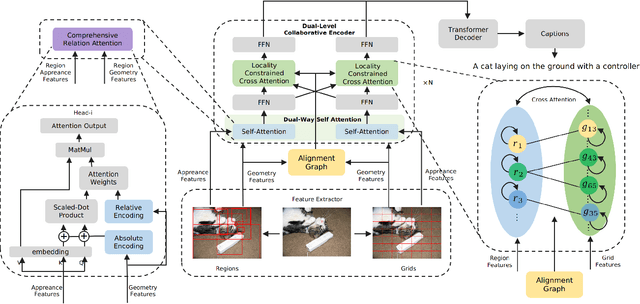
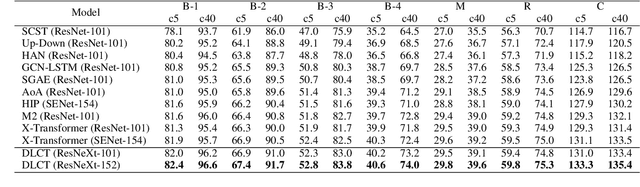
Descriptive region features extracted by object detection networks have played an important role in the recent advancements of image captioning. However, they are still criticized for the lack of contextual information and fine-grained details, which in contrast are the merits of traditional grid features. In this paper, we introduce a novel Dual-Level Collaborative Transformer (DLCT) network to realize the complementary advantages of the two features. Concretely, in DLCT, these two features are first processed by a novelDual-way Self Attenion (DWSA) to mine their intrinsic properties, where a Comprehensive Relation Attention component is also introduced to embed the geometric information. In addition, we propose a Locality-Constrained Cross Attention module to address the semantic noises caused by the direct fusion of these two features, where a geometric alignment graph is constructed to accurately align and reinforce region and grid features. To validate our model, we conduct extensive experiments on the highly competitive MS-COCO dataset, and achieve new state-of-the-art performance on both local and online test sets, i.e., 133.8% CIDEr-D on Karpathy split and 135.4% CIDEr on the official split. Code is available at https://github.com/luo3300612/image-captioning-DLCT.
Improving Image Captioning by Leveraging Intra- and Inter-layer Global Representation in Transformer Network
Dec 13, 2020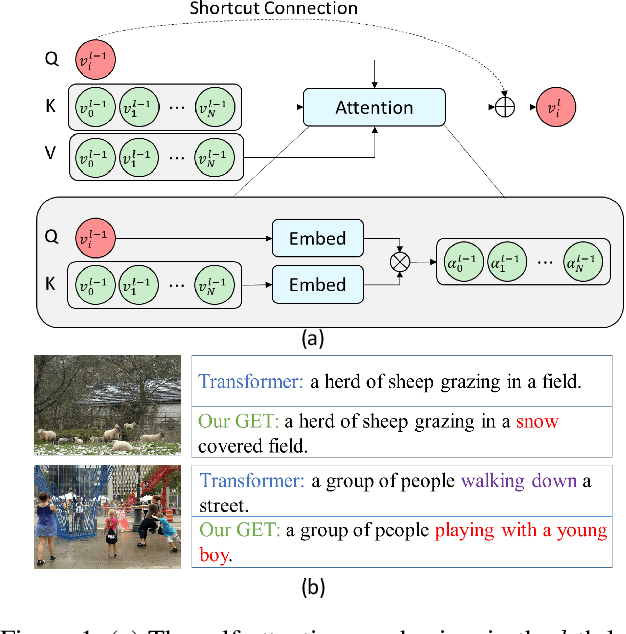
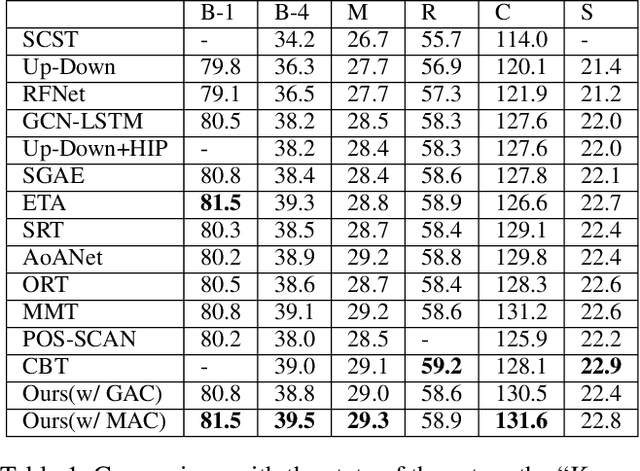
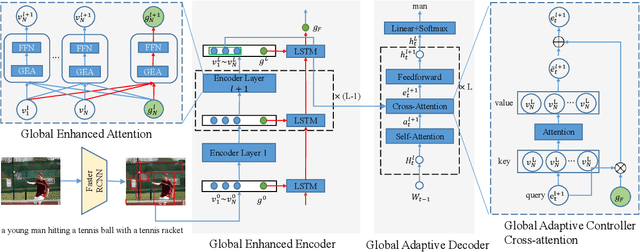
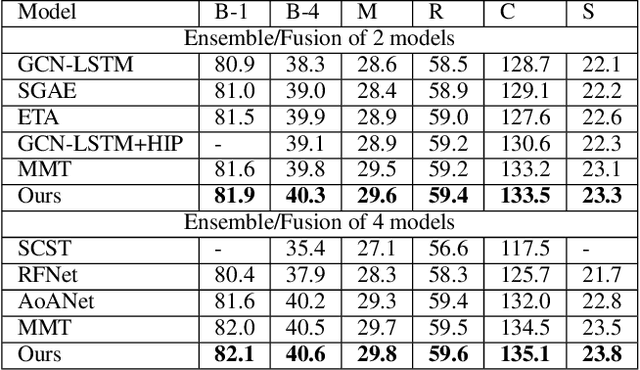
Transformer-based architectures have shown great success in image captioning, where object regions are encoded and then attended into the vectorial representations to guide the caption decoding. However, such vectorial representations only contain region-level information without considering the global information reflecting the entire image, which fails to expand the capability of complex multi-modal reasoning in image captioning. In this paper, we introduce a Global Enhanced Transformer (termed GET) to enable the extraction of a more comprehensive global representation, and then adaptively guide the decoder to generate high-quality captions. In GET, a Global Enhanced Encoder is designed for the embedding of the global feature, and a Global Adaptive Decoder are designed for the guidance of the caption generation. The former models intra- and inter-layer global representation by taking advantage of the proposed Global Enhanced Attention and a layer-wise fusion module. The latter contains a Global Adaptive Controller that can adaptively fuse the global information into the decoder to guide the caption generation. Extensive experiments on MS COCO dataset demonstrate the superiority of our GET over many state-of-the-arts.
Learning Efficient GANs using Differentiable Masks and co-Attention Distillation
Nov 21, 2020
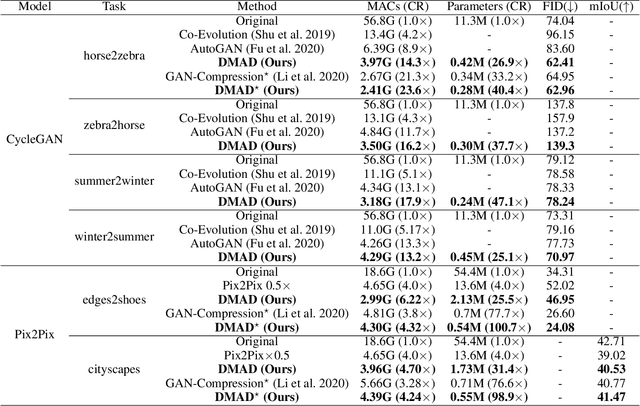
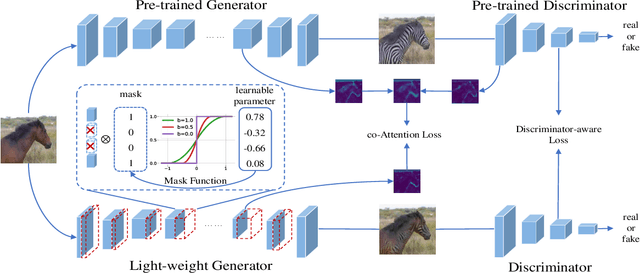
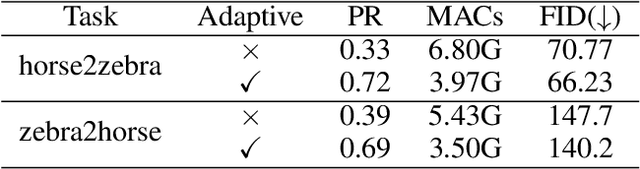
Generative Adversarial Networks (GANs) have been widely-used in image translation, but their high computational and storage costs impede the deployment on mobile devices. Prevalent methods for CNN compression cannot be directly applied to GANs due to the complicated generator architecture and the unstable adversarial training. To solve these, in this paper, we introduce a novel GAN compression method, termed DMAD, by proposing a Differentiable Mask and a co-Attention Distillation. The former searches for a light-weight generator architecture in a training-adaptive manner. To overcome channel inconsistency when pruning the residual connections, an adaptive cross-block group sparsity is further incorporated. The latter simultaneously distills informative attention maps from both the generator and discriminator of a pre-trained model to the searched generator, effectively stabilizing the adversarial training of our light-weight model. Experiments show that DMAD can reduce the Multiply Accumulate Operations (MACs) of CycleGAN by 13x and that of Pix2Pix by 4x while retaining a comparable performance against the full model. Code is available at https://github.com/SJLeo/DMAD.
Rotated Binary Neural Network
Oct 22, 2020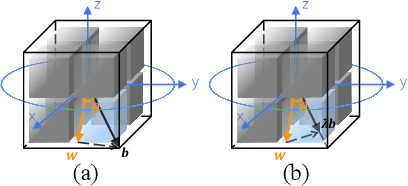
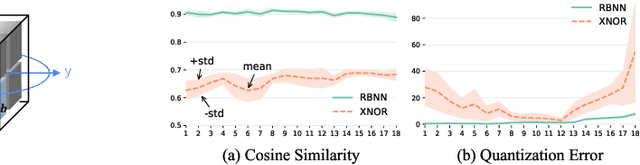
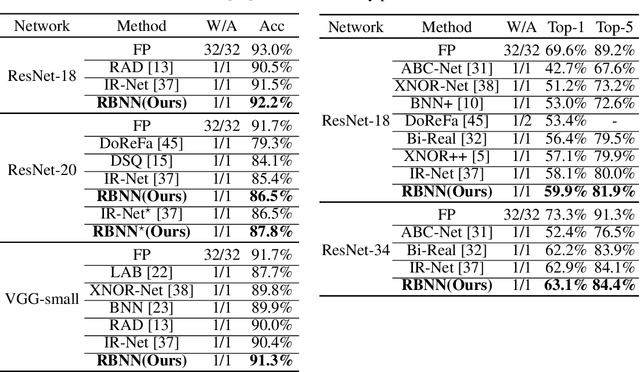
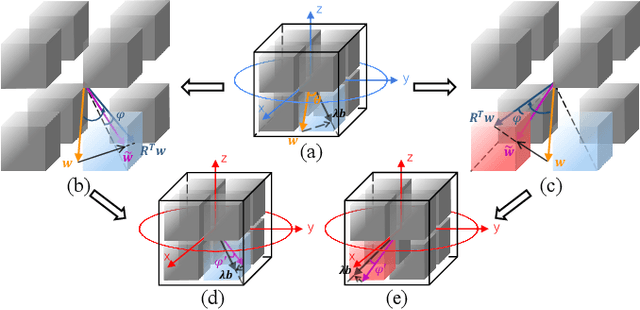
Binary Neural Network (BNN) shows its predominance in reducing the complexity of deep neural networks. However, it suffers severe performance degradation. One of the major impediments is the large quantization error between the full-precision weight vector and its binary vector. Previous works focus on compensating for the norm gap while leaving the angular bias hardly touched. In this paper, for the first time, we explore the influence of angular bias on the quantization error and then introduce a Rotated Binary Neural Network (RBNN), which considers the angle alignment between the full-precision weight vector and its binarized version. At the beginning of each training epoch, we propose to rotate the full-precision weight vector to its binary vector to reduce the angular bias. To avoid the high complexity of learning a large rotation matrix, we further introduce a bi-rotation formulation that learns two smaller rotation matrices. In the training stage, we devise an adjustable rotated weight vector for binarization to escape the potential local optimum. Our rotation leads to around 50% weight flips which maximize the information gain. Finally, we propose a training-aware approximation of the sign function for the gradient backward. Experiments on CIFAR-10 and ImageNet demonstrate the superiorities of RBNN over many state-of-the-arts. Our source code, experimental settings, training logs and binary models are available at https://github.com/lmbxmu/RBNN.
Towards Scalable Distributed Training of Deep Learning on Public Cloud Clusters
Oct 20, 2020
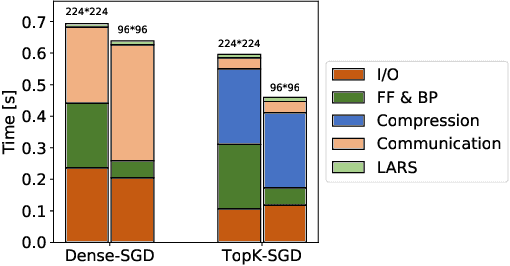
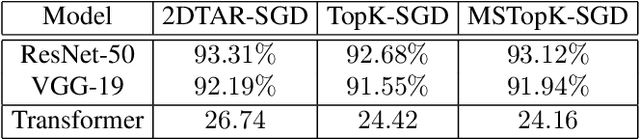
Distributed training techniques have been widely deployed in large-scale deep neural networks (DNNs) training on dense-GPU clusters. However, on public cloud clusters, due to the moderate inter-connection bandwidth between instances, traditional state-of-the-art distributed training systems cannot scale well in training large-scale models. In this paper, we propose a new computing and communication efficient top-k sparsification communication library for distributed training. To further improve the system scalability, we optimize I/O by proposing a simple yet efficient multi-level data caching mechanism and optimize the update operation by introducing a novel parallel tensor operator. Experimental results on a 16-node Tencent Cloud cluster (each node with 8 Nvidia Tesla V100 GPUs) show that our system achieves 25%-40% faster than existing state-of-the-art systems on CNNs and Transformer. We finally break the record on DAWNBench on training ResNet-50 to 93% top-5 accuracy on ImageNet.
Channel Pruning via Automatic Structure Search
Jan 23, 2020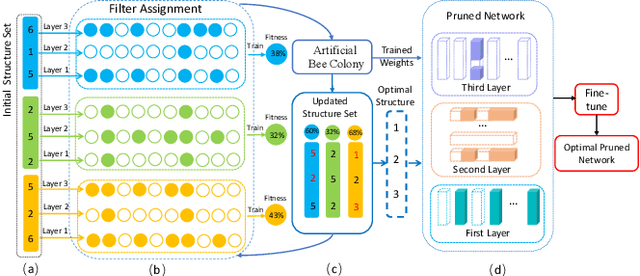
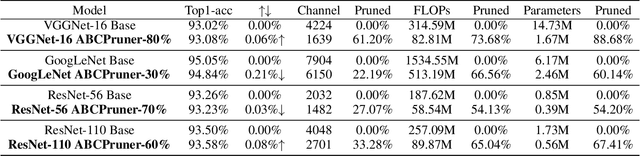
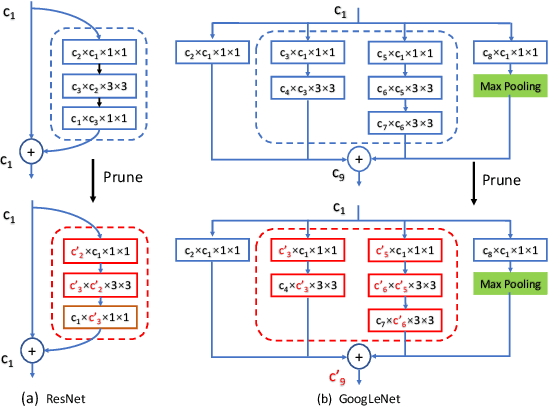
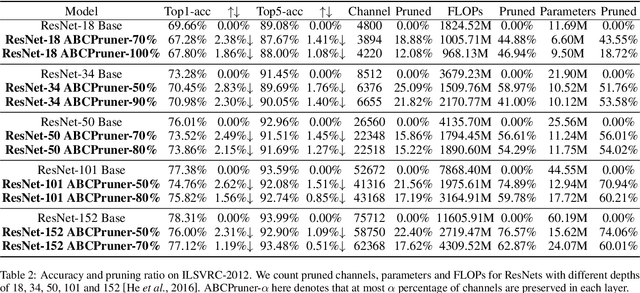
Channel pruning is among the predominant approaches to compress deep neural networks. To this end, most existing pruning methods focus on selecting channels (filters) by importance/optimization or regularization based on rule-of-thumb designs, which defects in sub-optimal pruning. In this paper, we propose a new channel pruning method based on artificial bee colony algorithm (ABC), dubbed as ABCPruner, which aims to efficiently find optimal pruned structure, i.e., channel number in each layer, rather than selecting "important" channels as previous works did. To solve the intractably huge combinations of pruned structure for deep networks, we first propose to shrink the combinations where the preserved channels are limited to a specific space, thus the combinations of pruned structure can be significantly reduced. And then, we formulate the search of optimal pruned structure as an optimization problem and integrate the ABC algorithm to solve it in an automatic manner to lessen human interference. ABCPruner has been demonstrated to be more effective, which also enables the fine-tuning to be conducted efficiently in an end-to-end manner. Experiments on CIFAR-10 show that ABCPruner reduces 73.68\% of FLOPs and 88.68\% of parameters with even 0.06\% accuracy improvement for VGGNet-16. On ILSVRC-2012, it achieves a reduction of 62.87\% FLOPs and removes 60.01\% of parameters with negligible accuracy cost for ResNet-152. The source codes can be available at https://github.com/lmbxmu/ABCPruner.