 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of the Removability of Speaker-Adversarial Perturbations
Oct 10, 2025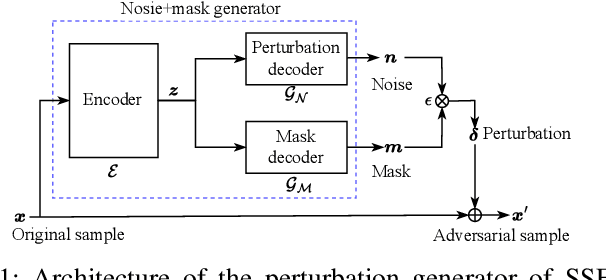

Recent advancements in adversarial attacks have demonstrated their effectiveness in misleading speaker recognition models, making wrong predictions about speaker identities. On the other hand, defense techniques against speaker-adversarial attacks focus on reducing the effects of speaker-adversarial perturbations on speaker attribute extraction. These techniques do not seek to fully remove the perturbations and restore the original speech. To this end, this paper studies the removability of speaker-adversarial perturbations. Specifically, the investigation is conducted assuming various degrees of awareness of the perturbation generator across three scenarios: ignorant, semi-informed, and well-informed. Besides, we consider both the optimization-based and feedforward perturbation generation methods. Experiments conducted on the LibriSpeech dataset demonstrated that: 1) in the ignorant scenario, speaker-adversarial perturbations cannot be eliminated, although their impact on speaker attribute extraction is reduced, 2) in the semi-informed scenario, the speaker-adversarial perturbations cannot be fully removed, while those generated by the feedforward model can be considerably reduced, and 3) in the well-informed scenario, speaker-adversarial perturbations are nearly eliminated, allowing for the restoration of the original speech. Audio samples can be found in https://voiceprivacy.github.io/Perturbation-Generation-Removal/.
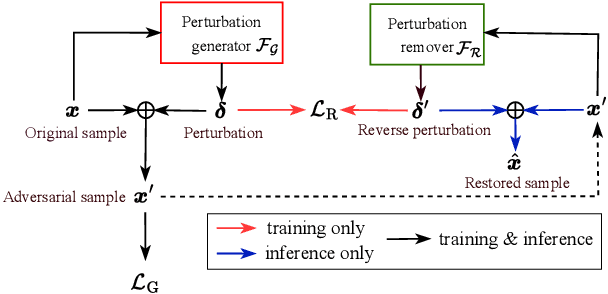
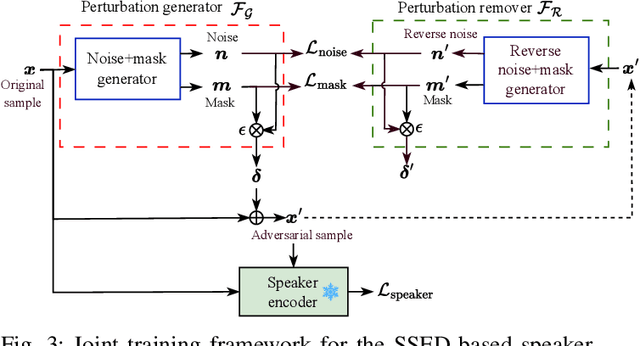
On the Generation and Removal of Speaker Adversarial Perturbation for Voice-Privacy Protection
Dec 12, 2024



Neural networks are commonly known to be vulnerable to adversarial attacks mounted through subtle perturbation on the input data. Recent development in voice-privacy protection has shown the positive use cases of the same technique to conceal speaker's voice attribute with additive perturbation signal generated by an adversarial network. This paper examines the reversibility property where an entity generating the adversarial perturbations is authorized to remove them and restore original speech (e.g., the speaker him/herself). A similar technique could also be used by an investigator to deanonymize a voice-protected speech to restore criminals' identities in security and forensic analysis. In this setting, the perturbation generative module is assumed to be known in the removal process. To this end, a joint training of perturbation generation and removal modules is proposed. Experimental results on the LibriSpeech dataset demonstrated that the subtle perturbations added to the original speech can be predicted from the anonymized speech while achieving the goal of privacy protection. By removing these perturbations from the anonymized sample, the original speech can be restored. Audio samples can be found in \url{https://voiceprivacy.github.io/Perturbation-Generation-Removal/}.
* 6 pages, 3 figures, published to IEEE SLT Workshop 2024
Towards Scalable Distributed Training of Deep Learning on Public Cloud Clusters
Oct 20, 2020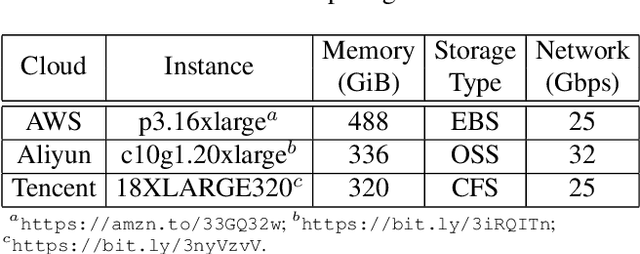
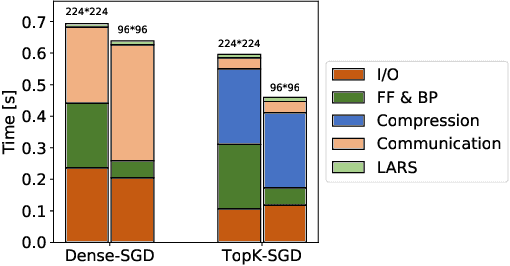
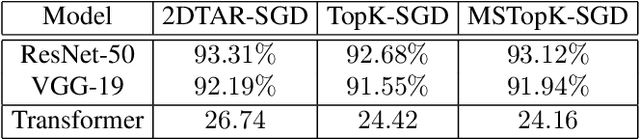
Distributed training techniques have been widely deployed in large-scale deep neural networks (DNNs) training on dense-GPU clusters. However, on public cloud clusters, due to the moderate inter-connection bandwidth between instances, traditional state-of-the-art distributed training systems cannot scale well in training large-scale models. In this paper, we propose a new computing and communication efficient top-k sparsification communication library for distributed training. To further improve the system scalability, we optimize I/O by proposing a simple yet efficient multi-level data caching mechanism and optimize the update operation by introducing a novel parallel tensor operator. Experimental results on a 16-node Tencent Cloud cluster (each node with 8 Nvidia Tesla V100 GPUs) show that our system achieves 25%-40% faster than existing state-of-the-art systems on CNNs and Transformer. We finally break the record on DAWNBench on training ResNet-50 to 93% top-5 accuracy on ImageNet.