 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEPIC: Memory Efficient Position Independent Caching for LLM Serving
Dec 18, 2025Modern LLM applications such as deep-research assistants, coding agents, and Retrieval-Augmented Generation (RAG) systems, repeatedly process long prompt histories containing shared document or code chunks, creating significant pressure on the Key Value (KV) cache, which must operate within limited memory while sustaining high throughput and low latency. Prefix caching partially alleviates some of these costs by reusing KV cache for previously processed tokens, but limited by strict prefix matching. Position-independent caching (PIC) enables chunk-level reuse at arbitrary positions, but requires selective recomputation and positional-encoding (PE) adjustments. However, because these operations vary across queries, KV for the same chunk diverges across requests. Moreover, without page alignment, chunk KV layouts diverge in memory, preventing page sharing. These issues result in only modest HBM savings even when many requests reuse the same content. We present MEPIC, a memory-efficient PIC system that enables chunk KV reuse across positions, requests, and batches. MEPIC aligns chunk KV to paged storage, shifts recomputation from token- to block-level so only the first block is request-specific, removes positional encodings via Rotary Position Embedding (RoPE) fusion in the attention kernel, and makes remaining blocks fully shareable. These techniques eliminate most duplicate chunk KV in HBM, reducing usage by up to 2x over state-of-the-art PIC at comparable latency and accuracy, and up to 5x for long prompts, without any model changes.
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025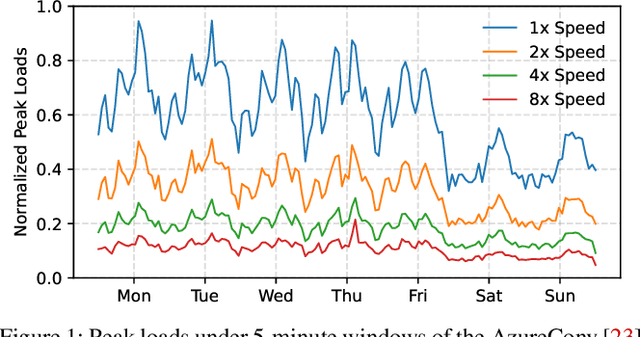
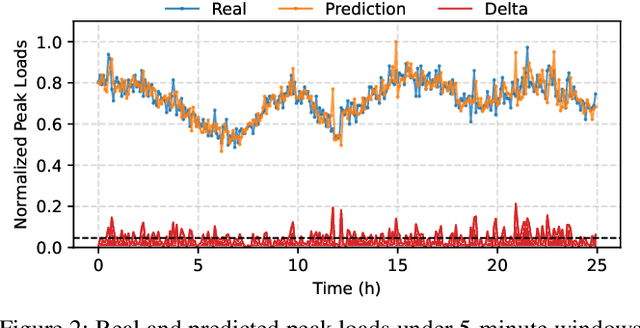
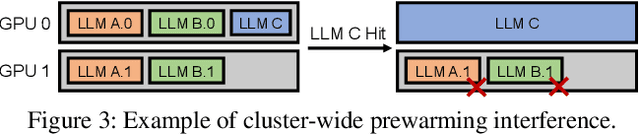
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.
Rethinking Schema Linking: A Context-Aware Bidirectional Retrieval Approach for Text-to-SQL
Oct 16, 2025



Schema linking -- the process of aligning natural language questions with database schema elements -- is a critical yet underexplored component of Text-to-SQL systems. While recent methods have focused primarily on improving SQL generation, they often neglect the retrieval of relevant schema elements, which can lead to hallucinations and execution failures. In this work, we propose a context-aware bidirectional schema retrieval framework that treats schema linking as a standalone problem. Our approach combines two complementary strategies: table-first retrieval followed by column selection, and column-first retrieval followed by table selection. It is further augmented with techniques such as question decomposition, keyword extraction, and keyphrase extraction. Through comprehensive evaluations on challenging benchmarks such as BIRD and Spider, we demonstrate that our method significantly improves schema recall while reducing false positives. Moreover, SQL generation using our retrieved schema consistently outperforms full-schema baselines and closely approaches oracle performance, all without requiring query refinement. Notably, our method narrows the performance gap between full and perfect schema settings by 50\%. Our findings highlight schema linking as a powerful lever for enhancing Text-to-SQL accuracy and efficiency.
Cross-attention Secretly Performs Orthogonal Alignment in Recommendation Models
Oct 10, 2025Cross-domain sequential recommendation (CDSR) aims to align heterogeneous user behavior sequences collected from different domains. While cross-attention is widely used to enhance alignment and improve recommendation performance, its underlying mechanism is not fully understood. Most researchers interpret cross-attention as residual alignment, where the output is generated by removing redundant and preserving non-redundant information from the query input by referencing another domain data which is input key and value. Beyond the prevailing view, we introduce Orthogonal Alignment, a phenomenon in which cross-attention discovers novel information that is not present in the query input, and further argue that those two contrasting alignment mechanisms can co-exist in recommendation models We find that when the query input and output of cross-attention are orthogonal, model performance improves over 300 experiments. Notably, Orthogonal Alignment emerges naturally, without any explicit orthogonality constraints. Our key insight is that Orthogonal Alignment emerges naturally because it improves scaling law. We show that baselines additionally incorporating cross-attention module outperform parameter-matched baselines, achieving a superior accuracy-per-model parameter. We hope these findings offer new directions for parameter-efficient scaling in multi-modal research.
Do LLMs Align with My Task? Evaluating Text-to-SQL via Dataset Alignment
Oct 06, 2025



Supervised Fine-Tuning (SFT) is an effective method for adapting Large Language Models (LLMs) on downstream tasks. However, variability in training data can hinder a model's ability to generalize across domains. This paper studies the problem of dataset alignment for Natural Language to SQL (NL2SQL or text to SQL), examining how well SFT training data matches the structural characteristics of target queries and how this alignment impacts model performance. We hypothesize that alignment can be accurately estimated by comparing the distributions of structural SQL features across the training set, target data, and the model's predictions prior to SFT. Through comprehensive experiments on three large cross-domain NL2SQL benchmarks and multiple model families, we show that structural alignment is a strong predictor of fine-tuning success. When alignment is high, SFT yields substantial gains in accuracy and SQL generation quality; when alignment is low, improvements are marginal or absent. These findings highlight the importance of alignment-aware data selection for effective fine-tuning and generalization in NL2SQL tasks.
InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Aug 19, 2025



Recent breakthroughs in video AIGC have ushered in a transformative era for audio-driven human animation. However, conventional video dubbing techniques remain constrained to mouth region editing, resulting in discordant facial expressions and body gestures that compromise viewer immersion. To overcome this limitation, we introduce sparse-frame video dubbing, a novel paradigm that strategically preserves reference keyframes to maintain identity, iconic gestures, and camera trajectories while enabling holistic, audio-synchronized full-body motion editing. Through critical analysis, we identify why naive image-to-video models fail in this task, particularly their inability to achieve adaptive conditioning. Addressing this, we propose InfiniteTalk, a streaming audio-driven generator designed for infinite-length long sequence dubbing. This architecture leverages temporal context frames for seamless inter-chunk transitions and incorporates a simple yet effective sampling strategy that optimizes control strength via fine-grained reference frame positioning. Comprehensive evaluations on HDTF, CelebV-HQ, and EMTD datasets demonstrate state-of-the-art performance. Quantitative metrics confirm superior visual realism, emotional coherence, and full-body motion synchronization.
SMARTAPS: Tool-augmented LLMs for Operations Management
Jul 23, 2025Large language models (LLMs) present intriguing opportunities to enhance user interaction with traditional algorithms and tools in real-world applications. An advanced planning system (APS) is a sophisticated software that leverages optimization to help operations planners create, interpret, and modify an operational plan. While highly beneficial, many customers are priced out of using an APS due to the ongoing costs of consultants responsible for customization and maintenance. To address the need for a more accessible APS expressed by supply chain planners, we present SmartAPS, a conversational system built on a tool-augmented LLM. Our system provides operations planners with an intuitive natural language chat interface, allowing them to query information, perform counterfactual reasoning, receive recommendations, and execute scenario analysis to better manage their operation. A short video demonstrating the system has been released: https://youtu.be/KtIrJjlDbyw
DAM-VSR: Disentanglement of Appearance and Motion for Video Super-Resolution
Jul 01, 2025



Real-world video super-resolution (VSR) presents significant challenges due to complex and unpredictable degradations. Although some recent methods utilize image diffusion models for VSR and have shown improved detail generation capabilities, they still struggle to produce temporally consistent frames. We attempt to use Stable Video Diffusion (SVD) combined with ControlNet to address this issue. However, due to the intrinsic image-animation characteristics of SVD, it is challenging to generate fine details using only low-quality videos. To tackle this problem, we propose DAM-VSR, an appearance and motion disentanglement framework for VSR. This framework disentangles VSR into appearance enhancement and motion control problems. Specifically, appearance enhancement is achieved through reference image super-resolution, while motion control is achieved through video ControlNet. This disentanglement fully leverages the generative prior of video diffusion models and the detail generation capabilities of image super-resolution models. Furthermore, equipped with the proposed motion-aligned bidirectional sampling strategy, DAM-VSR can conduct VSR on longer input videos. DAM-VSR achieves state-of-the-art performance on real-world data and AIGC data, demonstrating its powerful detail generation capabilities.
Sentinel: Attention Probing of Proxy Models for LLM Context Compression with an Understanding Perspective
May 29, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) with external context, but retrieved passages are often lengthy, noisy, or exceed input limits. Existing compression methods typically require supervised training of dedicated compression models, increasing cost and reducing portability. We propose Sentinel, a lightweight sentence-level compression framework that reframes context filtering as an attention-based understanding task. Rather than training a compression model, Sentinel probes decoder attention from an off-the-shelf 0.5B proxy LLM using a lightweight classifier to identify sentence relevance. Empirically, we find that query-context relevance estimation is consistent across model scales, with 0.5B proxies closely matching the behaviors of larger models. On the LongBench benchmark, Sentinel achieves up to 5$\times$ compression while matching the QA performance of 7B-scale compression systems. Our results suggest that probing native attention signals enables fast, effective, and question-aware context compression. Code available at: https://github.com/yzhangchuck/Sentinel.
Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
May 28, 2025



Audio-driven human animation methods, such as talking head and talking body generation, have made remarkable progress in generating synchronized facial movements and appealing visual quality videos. However, existing methods primarily focus on single human animation and struggle with multi-stream audio inputs, facing incorrect binding problems between audio and persons. Additionally, they exhibit limitations in instruction-following capabilities. To solve this problem, in this paper, we propose a novel task: Multi-Person Conversational Video Generation, and introduce a new framework, MultiTalk, to address the challenges during multi-person generation. Specifically, for audio injection, we investigate several schemes and propose the Label Rotary Position Embedding (L-RoPE) method to resolve the audio and person binding problem. Furthermore, during training, we observe that partial parameter training and multi-task training are crucial for preserving the instruction-following ability of the base model. MultiTalk achieves superior performance compared to other methods on several datasets, including talking head, talking body, and multi-person datasets, demonstrating the powerful generation capabilities of our approach.