 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoZone-Talker: Regional Semantic Control of Audio-Driven 3DGS Talking Heads via Facial Action Units
Jun 14, 20263D Gaussian Splatting (3DGS) has shown strong potential for high-fidelity talking head synthesis. However, enabling fine-grained, interpretable, and editable facial expression control remains fundamentally challenging due to intrinsic conflicts between speech-driven facial dynamics and explicit expression signals. Existing methods rely on implicit multimodal fusion, leading to spatial entanglement and temporal instability. We present EmoZone-Talker, a novel framework that reformulates audio-driven facial animation as a structured spatial-temporal coordination problem under cross-modal conflicts. Our approach introduces an explicit spatial disentanglement and temporal dynamics modeling of facial motion. Specifically, we propose Synergy Zones with Prioritized Attention Bias (SZ-PAB) to explicitly decouple modality contributions via region-wise constraints guided by anatomical priors, and a Channel-Independent Temporal AU Encoder (CIT-AE) to model temporally coherent AU dynamics. By integrating these representations into 3D Gaussian deformation, EmoZone-Talker enables precise and interpretable control over facial expressions. Extensive experiments demonstrate that our method improves expression controllability and realism, with notable gains in upper-face accuracy and temporal coherence, while preserving high rendering quality and accurate lip synchronization. Code will be publicly released to facilitate reproducibility and further research.
Astra: Activation-Space Tail-Eigenvector Low-Rank Adaptation of Large Language Models
Feb 22, 2026Parameter-Efficient Fine-Tuning (PEFT) methods, especially LoRA, are widely used for adapting pre-trained models to downstream tasks due to their computational and storage efficiency. However, in the context of LoRA and its variants, the potential of activation subspaces corresponding to tail eigenvectors remains substantially under-exploited, which may lead to suboptimal fine-tuning performance. In this work, we propose Astra (Activation-Space Tail-Eigenvector Low-Rank Adaptation), a novel PEFT method that leverages the tail eigenvectors of the model output activations-estimated from a small task-specific calibration set-to construct task-adaptive low-rank adapters. By constraining updates to the subspace spanned by these tail eigenvectors, Astra achieves faster convergence and improved downstream performance with a significantly reduced parameter budget. Extensive experiments across natural language understanding (NLU) and natural language generation (NLG) tasks demonstrate that Astra consistently outperforms existing PEFT baselines across 16 benchmarks and even surpasses full fine-tuning (FFT) in certain scenarios.
Rethinking LLM-as-a-Judge: Representation-as-a-Judge with Small Language Models via Semantic Capacity Asymmetry
Jan 30, 2026Large language models (LLMs) are widely used as reference-free evaluators via prompting, but this "LLM-as-a-Judge" paradigm is costly, opaque, and sensitive to prompt design. In this work, we investigate whether smaller models can serve as efficient evaluators by leveraging internal representations instead of surface generation. We uncover a consistent empirical pattern: small LMs, despite with weak generative ability, encode rich evaluative signals in their hidden states. This motivates us to propose the Semantic Capacity Asymmetry Hypothesis: evaluation requires significantly less semantic capacity than generation and can be grounded in intermediate representations, suggesting that evaluation does not necessarily need to rely on large-scale generative models but can instead leverage latent features from smaller ones. Our findings motivate a paradigm shift from LLM-as-a-Judge to Representation-as-a-Judge, a decoding-free evaluation strategy that probes internal model structure rather than relying on prompted output. We instantiate this paradigm through INSPECTOR, a probing-based framework that predicts aspect-level evaluation scores from small model representations. Experiments on reasoning benchmarks (GSM8K, MATH, GPQA) show that INSPECTOR substantially outperforms prompting-based small LMs and closely approximates full LLM judges, while offering a more efficient, reliable, and interpretable alternative for scalable evaluation.
Sentinel: Attention Probing of Proxy Models for LLM Context Compression with an Understanding Perspective
May 29, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) with external context, but retrieved passages are often lengthy, noisy, or exceed input limits. Existing compression methods typically require supervised training of dedicated compression models, increasing cost and reducing portability. We propose Sentinel, a lightweight sentence-level compression framework that reframes context filtering as an attention-based understanding task. Rather than training a compression model, Sentinel probes decoder attention from an off-the-shelf 0.5B proxy LLM using a lightweight classifier to identify sentence relevance. Empirically, we find that query-context relevance estimation is consistent across model scales, with 0.5B proxies closely matching the behaviors of larger models. On the LongBench benchmark, Sentinel achieves up to 5$\times$ compression while matching the QA performance of 7B-scale compression systems. Our results suggest that probing native attention signals enables fast, effective, and question-aware context compression. Code available at: https://github.com/yzhangchuck/Sentinel.
CHOrD: Generation of Collision-Free, House-Scale, and Organized Digital Twins for 3D Indoor Scenes with Controllable Floor Plans and Optimal Layouts
Mar 15, 2025We introduce CHOrD, a novel framework for scalable synthesis of 3D indoor scenes, designed to create house-scale, collision-free, and hierarchically structured indoor digital twins. In contrast to existing methods that directly synthesize the scene layout as a scene graph or object list, CHOrD incorporates a 2D image-based intermediate layout representation, enabling effective prevention of collision artifacts by successfully capturing them as out-of-distribution (OOD) scenarios during generation. Furthermore, unlike existing methods, CHOrD is capable of generating scene layouts that adhere to complex floor plans with multi-modal controls, enabling the creation of coherent, house-wide layouts robust to both geometric and semantic variations in room structures. Additionally, we propose a novel dataset with expanded coverage of household items and room configurations, as well as significantly improved data quality. CHOrD demonstrates state-of-the-art performance on both the 3D-FRONT and our proposed datasets, delivering photorealistic, spatially coherent indoor scene synthesis adaptable to arbitrary floor plan variations.
Self-Enhanced Reasoning Training: Activating Latent Reasoning in Small Models for Enhanced Reasoning Distillation
Feb 18, 2025



The rapid advancement of large language models (LLMs) has significantly enhanced their reasoning abilities, enabling increasingly complex tasks. However, these capabilities often diminish in smaller, more computationally efficient models like GPT-2. Recent research shows that reasoning distillation can help small models acquire reasoning capabilities, but most existing methods focus primarily on improving teacher-generated reasoning paths. Our observations reveal that small models can generate high-quality reasoning paths during sampling, even without chain-of-thought prompting, though these paths are often latent due to their low probability under standard decoding strategies. To address this, we propose Self-Enhanced Reasoning Training (SERT), which activates and leverages latent reasoning capabilities in small models through self-training on filtered, self-generated reasoning paths under zero-shot conditions. Experiments using OpenAI's GPT-3.5 as the teacher model and GPT-2 models as the student models demonstrate that SERT enhances the reasoning abilities of small models, improving their performance in reasoning distillation.
Dynamic Attention-Guided Context Decoding for Mitigating Context Faithfulness Hallucinations in Large Language Models
Jan 02, 2025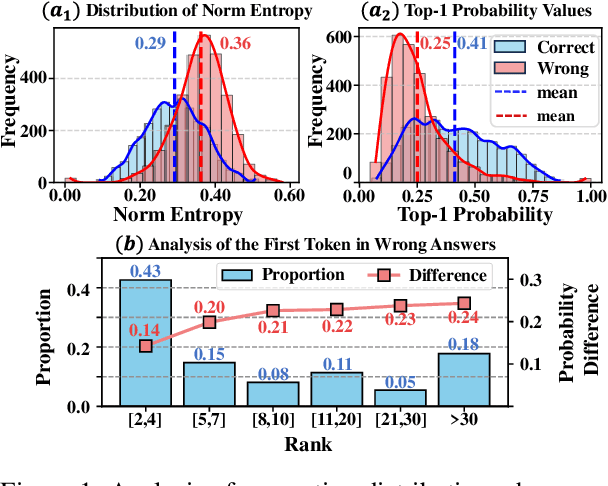
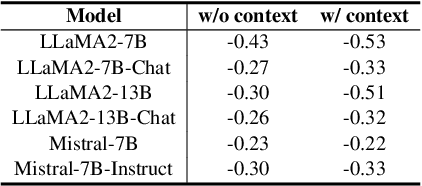
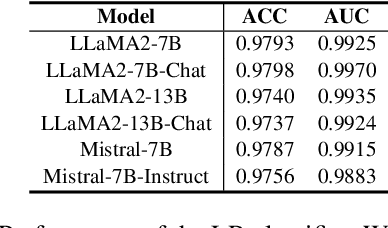
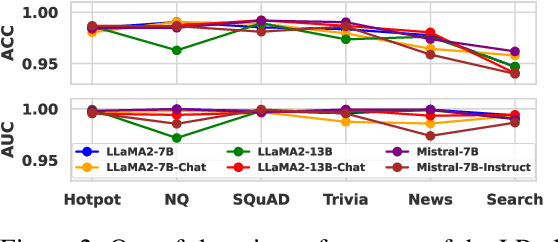
Large language models (LLMs) often suffer from context faithfulness hallucinations, where outputs deviate from retrieved information due to insufficient context utilization and high output uncertainty. Our uncertainty evaluation experiments reveal a strong correlation between high uncertainty and hallucinations. We hypothesize that attention mechanisms encode signals indicative of contextual utilization, validated through probing analysis. Based on these insights, we propose Dynamic Attention-Guided Context Decoding (DAGCD), a lightweight framework that integrates attention distributions and uncertainty signals in a single-pass decoding process. Experiments across QA datasets demonstrate DAGCD's effectiveness, achieving significant improvements in faithfulness and robustness while maintaining computational efficiency.
Rethinking Layer Removal: Preserving Critical Components with Task-Aware Singular Value Decomposition
Dec 31, 2024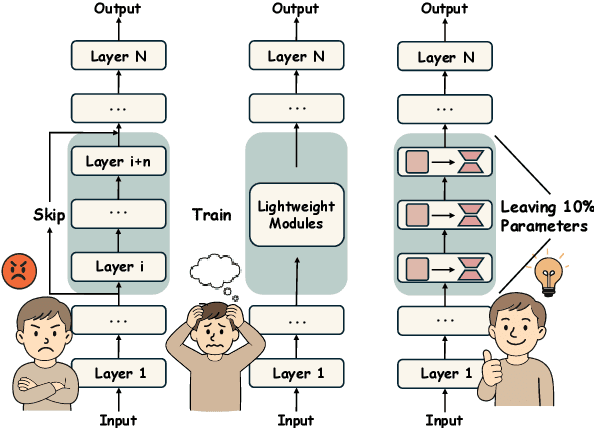



Layer removal has emerged as a promising approach for compressing large language models (LLMs) by leveraging redundancy within layers to reduce model size and accelerate inference. However, this technique often compromises internal consistency, leading to performance degradation and instability, with varying impacts across different model architectures. In this work, we propose Taco-SVD, a task-aware framework that retains task-critical singular value directions, preserving internal consistency while enabling efficient compression. Unlike direct layer removal, Taco-SVD preserves task-critical transformations to mitigate performance degradation. By leveraging gradient-based attribution methods, Taco-SVD aligns singular values with downstream task objectives. Extensive evaluations demonstrate that Taco-SVD outperforms existing methods in perplexity and task performance across different architectures while ensuring minimal computational overhead.
Learning to Adapt to Low-Resource Paraphrase Generation
Dec 22, 2024Paraphrase generation is a longstanding NLP task and achieves great success with the aid of large corpora. However, transferring a paraphrasing model to another domain encounters the problem of domain shifting especially when the data is sparse. At the same time, widely using large pre-trained language models (PLMs) faces the overfitting problem when training on scarce labeled data. To mitigate these two issues, we propose, LAPA, an effective adapter for PLMs optimized by meta-learning. LAPA has three-stage training on three types of related resources to solve this problem: 1. pre-training PLMs on unsupervised corpora, 2. inserting an adapter layer and meta-training on source domain labeled data, and 3. fine-tuning adapters on a small amount of target domain labeled data. This method enables paraphrase generation models to learn basic language knowledge first, then learn the paraphrasing task itself later, and finally adapt to the target task. Our experimental results demonstrate that LAPA achieves state-of-the-art in supervised, unsupervised, and low-resource settings on three benchmark datasets. With only 2\% of trainable parameters and 1\% labeled data of the target task, our approach can achieve a competitive performance with previous work.
Planning with Large Language Models for Conversational Agents
Jul 04, 2024Controllability and proactivity are crucial properties of autonomous conversational agents (CAs). Controllability requires the CAs to follow the standard operating procedures (SOPs), such as verifying identity before activating credit cards. Proactivity requires the CAs to guide the conversation towards the goal during user uncooperation, such as persuasive dialogue. Existing research cannot be unified with controllability, proactivity, and low manual annotation. To bridge this gap, we propose a new framework for planning-based conversational agents (PCA) powered by large language models (LLMs), which only requires humans to define tasks and goals for the LLMs. Before conversation, LLM plans the core and necessary SOP for dialogue offline. During the conversation, LLM plans the best action path online referring to the SOP, and generates responses to achieve process controllability. Subsequently, we propose a semi-automatic dialogue data creation framework and curate a high-quality dialogue dataset (PCA-D). Meanwhile, we develop multiple variants and evaluation metrics for PCA, e.g., planning with Monte Carlo Tree Search (PCA-M), which searches for the optimal dialogue action while satisfying SOP constraints and achieving the proactive of the dialogue. Experiment results show that LLMs finetuned on PCA-D can significantly improve the performance and generalize to unseen domains. PCA-M outperforms other CoT and ToT baselines in terms of conversation controllability, proactivity, task success rate, and overall logical coherence, and is applicable in industry dialogue scenarios. The dataset and codes are available at XXXX.