 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Video-Avatar 1.5 Technical Report
May 26, 2026Despite advances in audio-driven video generation, achieving commercial-grade stability remains challenging. We present LongCat-Video-Avatar 1.5, an upgraded open-source framework prioritizing systematic engineering and production-readiness over architectural novelty. By upgrading the audio encoder to Whisper Large and meticulously scaling our training recipes, v1.5 achieves accurate lip-synchronization, full-body temporal stability, and robust long-video generation with strict identity consistency. Through rigorous data curation and RLHF Training, the model readily generalizes to stylized domains such as anime and animals, and natively handles complex real-world conditions, such as multi-person interactions and object handling. Furthermore, addressing the practical demands of industrial deployment, we employ advanced step distillation to accelerate inference to an optimal 8 NFE, achieving a favorable trade-off between serving efficiency and visual fidelity. The superiority of our approach is validated through extensive quantitative metrics and a rigorous human evaluation conducted on a comprehensive benchmark of over 500 diverse test cases. Results show that v1.5 achieves competitive or superior performance compared to leading closed-source systems (e.g., HeyGen, OmniHuman 1.5, Kling Avatar 2.0) across human-likeness ratings and expert-level quality assessments on our benchmark. With its open-source release, LongCat-Video-Avatar 1.5 narrows the gap between academic research prototypes and commercial-grade deployment.
Infinite-World: Scaling Interactive World Models to 1000-Frame Horizons via Pose-Free Hierarchical Memory
Feb 03, 2026We propose Infinite-World, a robust interactive world model capable of maintaining coherent visual memory over 1000+ frames in complex real-world environments. While existing world models can be efficiently optimized on synthetic data with perfect ground-truth, they lack an effective training paradigm for real-world videos due to noisy pose estimations and the scarcity of viewpoint revisits. To bridge this gap, we first introduce a Hierarchical Pose-free Memory Compressor (HPMC) that recursively distills historical latents into a fixed-budget representation. By jointly optimizing the compressor with the generative backbone, HPMC enables the model to autonomously anchor generations in the distant past with bounded computational cost, eliminating the need for explicit geometric priors. Second, we propose an Uncertainty-aware Action Labeling module that discretizes continuous motion into a tri-state logic. This strategy maximizes the utilization of raw video data while shielding the deterministic action space from being corrupted by noisy trajectories, ensuring robust action-response learning. Furthermore, guided by insights from a pilot toy study, we employ a Revisit-Dense Finetuning Strategy using a compact, 30-minute dataset to efficiently activate the model's long-range loop-closure capabilities. Extensive experiments, including objective metrics and user studies, demonstrate that Infinite-World achieves superior performance in visual quality, action controllability, and spatial consistency.
InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Aug 19, 2025



Recent breakthroughs in video AIGC have ushered in a transformative era for audio-driven human animation. However, conventional video dubbing techniques remain constrained to mouth region editing, resulting in discordant facial expressions and body gestures that compromise viewer immersion. To overcome this limitation, we introduce sparse-frame video dubbing, a novel paradigm that strategically preserves reference keyframes to maintain identity, iconic gestures, and camera trajectories while enabling holistic, audio-synchronized full-body motion editing. Through critical analysis, we identify why naive image-to-video models fail in this task, particularly their inability to achieve adaptive conditioning. Addressing this, we propose InfiniteTalk, a streaming audio-driven generator designed for infinite-length long sequence dubbing. This architecture leverages temporal context frames for seamless inter-chunk transitions and incorporates a simple yet effective sampling strategy that optimizes control strength via fine-grained reference frame positioning. Comprehensive evaluations on HDTF, CelebV-HQ, and EMTD datasets demonstrate state-of-the-art performance. Quantitative metrics confirm superior visual realism, emotional coherence, and full-body motion synchronization.
LLIA -- Enabling Low-Latency Interactive Avatars: Real-Time Audio-Driven Portrait Video Generation with Diffusion Models
Jun 06, 2025Diffusion-based models have gained wide adoption in the virtual human generation due to their outstanding expressiveness. However, their substantial computational requirements have constrained their deployment in real-time interactive avatar applications, where stringent speed, latency, and duration requirements are paramount. We present a novel audio-driven portrait video generation framework based on the diffusion model to address these challenges. Firstly, we propose robust variable-length video generation to reduce the minimum time required to generate the initial video clip or state transitions, which significantly enhances the user experience. Secondly, we propose a consistency model training strategy for Audio-Image-to-Video to ensure real-time performance, enabling a fast few-step generation. Model quantization and pipeline parallelism are further employed to accelerate the inference speed. To mitigate the stability loss incurred by the diffusion process and model quantization, we introduce a new inference strategy tailored for long-duration video generation. These methods ensure real-time performance and low latency while maintaining high-fidelity output. Thirdly, we incorporate class labels as a conditional input to seamlessly switch between speaking, listening, and idle states. Lastly, we design a novel mechanism for fine-grained facial expression control to exploit our model's inherent capacity. Extensive experiments demonstrate that our approach achieves low-latency, fluid, and authentic two-way communication. On an NVIDIA RTX 4090D, our model achieves a maximum of 78 FPS at a resolution of 384x384 and 45 FPS at a resolution of 512x512, with an initial video generation latency of 140 ms and 215 ms, respectively.
YOLOv6 v3.0: A Full-Scale Reloading
Jan 13, 2023



The YOLO community has been in high spirits since our first two releases! By the advent of Chinese New Year 2023, which sees the Year of the Rabbit, we refurnish YOLOv6 with numerous novel enhancements on the network architecture and the training scheme. This release is identified as YOLOv6 v3.0. For a glimpse of performance, our YOLOv6-N hits 37.5% AP on the COCO dataset at a throughput of 1187 FPS tested with an NVIDIA Tesla T4 GPU. YOLOv6-S strikes 45.0% AP at 484 FPS, outperforming other mainstream detectors at the same scale (YOLOv5-S, YOLOv8-S, YOLOX-S and PPYOLOE-S). Whereas, YOLOv6-M/L also achieve better accuracy performance (50.0%/52.8% respectively) than other detectors at a similar inference speed. Additionally, with an extended backbone and neck design, our YOLOv6-L6 achieves the state-of-the-art accuracy in real-time. Extensive experiments are carefully conducted to validate the effectiveness of each improving component. Our code is made available at https://github.com/meituan/YOLOv6.
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
Sep 07, 2022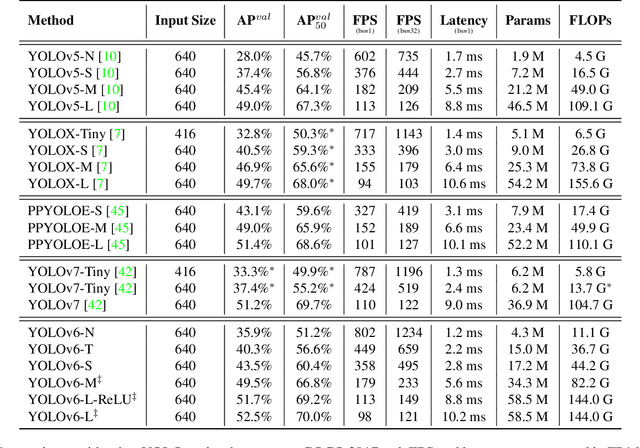
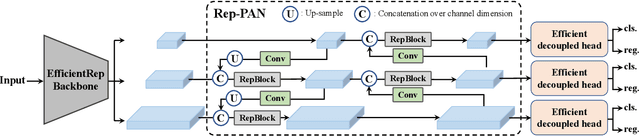
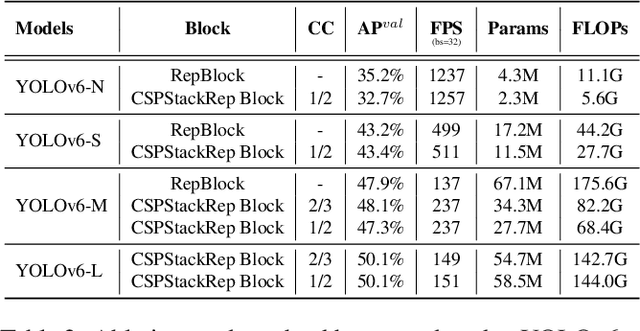
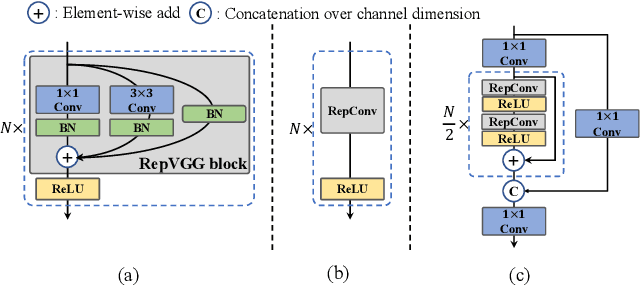
For years, the YOLO series has been the de facto industry-level standard for efficient object detection. The YOLO community has prospered overwhelmingly to enrich its use in a multitude of hardware platforms and abundant scenarios. In this technical report, we strive to push its limits to the next level, stepping forward with an unwavering mindset for industry application. Considering the diverse requirements for speed and accuracy in the real environment, we extensively examine the up-to-date object detection advancements either from industry or academia. Specifically, we heavily assimilate ideas from recent network design, training strategies, testing techniques, quantization, and optimization methods. On top of this, we integrate our thoughts and practice to build a suite of deployment-ready networks at various scales to accommodate diversified use cases. With the generous permission of YOLO authors, we name it YOLOv6. We also express our warm welcome to users and contributors for further enhancement. For a glimpse of performance, our YOLOv6-N hits 35.9% AP on the COCO dataset at a throughput of 1234 FPS on an NVIDIA Tesla T4 GPU. YOLOv6-S strikes 43.5% AP at 495 FPS, outperforming other mainstream detectors at the same scale~(YOLOv5-S, YOLOX-S, and PPYOLOE-S). Our quantized version of YOLOv6-S even brings a new state-of-the-art 43.3% AP at 869 FPS. Furthermore, YOLOv6-M/L also achieves better accuracy performance (i.e., 49.5%/52.3%) than other detectors with a similar inference speed. We carefully conducted experiments to validate the effectiveness of each component. Our code is made available at https://github.com/meituan/YOLOv6.