 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYong Chen
BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks
May 26, 2023
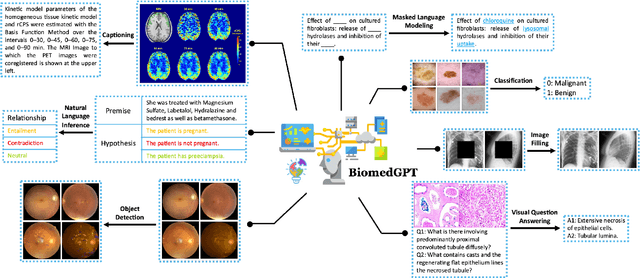
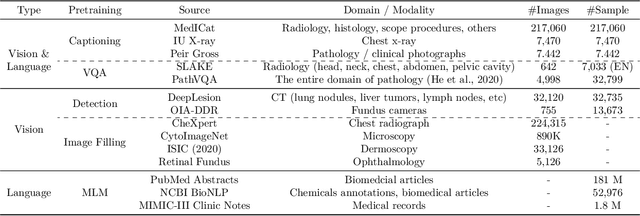
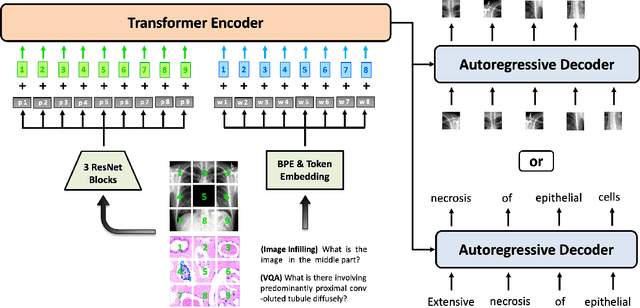

In this paper, we introduce a unified and generalist Biomedical Generative Pre-trained Transformer (BiomedGPT) model, which leverages self-supervision on large and diverse datasets to accept multi-modal inputs and perform a range of downstream tasks. Our experiments demonstrate that BiomedGPT delivers expansive and inclusive representations of biomedical data, outperforming the majority of preceding state-of-the-art models across five distinct tasks with 20 public datasets spanning over 15 unique biomedical modalities. Through the ablation study, we also showcase the efficacy of our multi-modal and multi-task pretraining approach in transferring knowledge to previously unseen data. Overall, our work presents a significant step forward in developing unified and generalist models for biomedicine, with far-reaching implications for improving healthcare outcomes.
Patchwork Learning: A Paradigm Towards Integrative Analysis across Diverse Biomedical Data Sources
May 13, 2023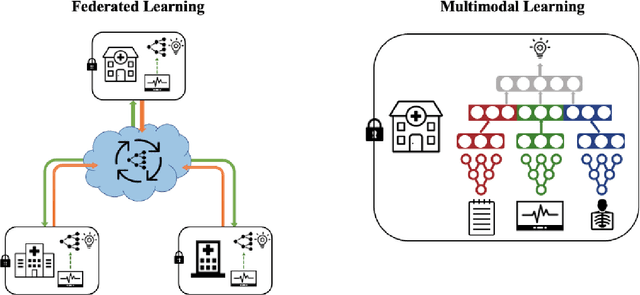
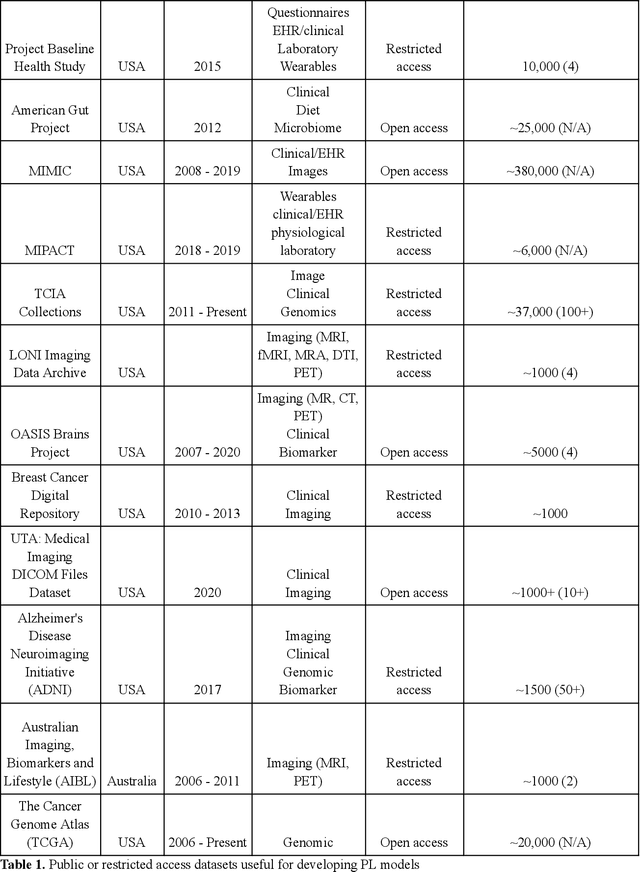


Machine learning (ML) in healthcare presents numerous opportunities for enhancing patient care, population health, and healthcare providers' workflows. However, the real-world clinical and cost benefits remain limited due to challenges in data privacy, heterogeneous data sources, and the inability to fully leverage multiple data modalities. In this perspective paper, we introduce "patchwork learning" (PL), a novel paradigm that addresses these limitations by integrating information from disparate datasets composed of different data modalities (e.g., clinical free-text, medical images, omics) and distributed across separate and secure sites. PL allows the simultaneous utilization of complementary data sources while preserving data privacy, enabling the development of more holistic and generalizable ML models. We present the concept of patchwork learning and its current implementations in healthcare, exploring the potential opportunities and applicable data sources for addressing various healthcare challenges. PL leverages bridging modalities or overlapping feature spaces across sites to facilitate information sharing and impute missing data, thereby addressing related prediction tasks. We discuss the challenges associated with PL, many of which are shared by federated and multimodal learning, and provide recommendations for future research in this field. By offering a more comprehensive approach to healthcare data integration, patchwork learning has the potential to revolutionize the clinical applicability of ML models. This paradigm promises to strike a balance between personalization and generalizability, ultimately enhancing patient experiences, improving population health, and optimizing healthcare providers' workflows.
PerCoNet: News Recommendation with Explicit Persona and Contrastive Learning
Apr 17, 2023
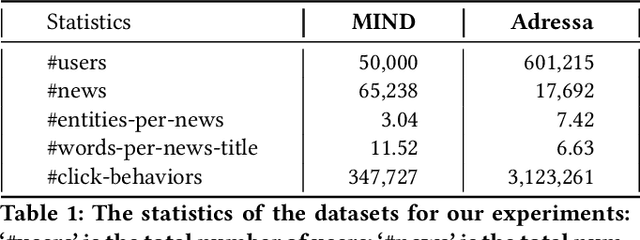
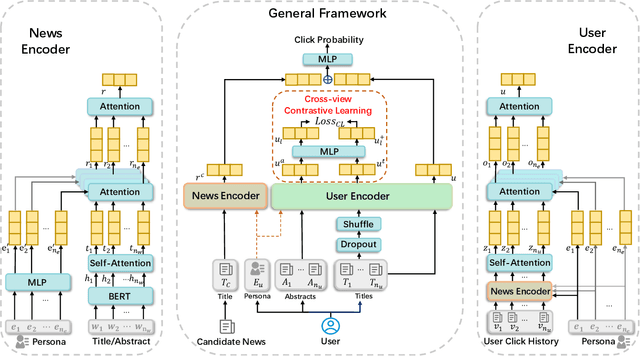
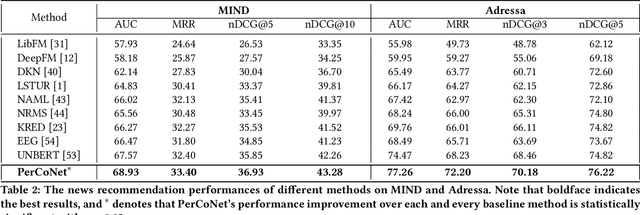
Personalized news recommender systems help users quickly find content of their interests from the sea of information. Today, the mainstream technology for personalized news recommendation is based on deep neural networks that can accurately model the semantic match between news items and users' interests. In this paper, we present \textbf{PerCoNet}, a novel deep learning approach to personalized news recommendation which features two new findings: (i) representing users through \emph{explicit persona analysis} based on the prominent entities in their recent news reading history could be more effective than latent persona analysis employed by most existing work, with a side benefit of enhanced explainability; (ii) utilizing the title and abstract of each news item via cross-view \emph{contrastive learning} would work better than just combining them directly. Extensive experiments on two real-world news datasets clearly show the superior performance of our proposed approach in comparison with current state-of-the-art techniques.
Scene Graph Based Fusion Network For Image-Text Retrieval
Mar 20, 2023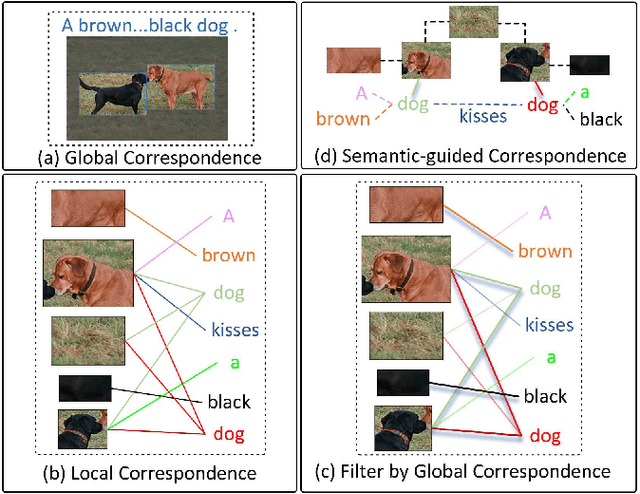
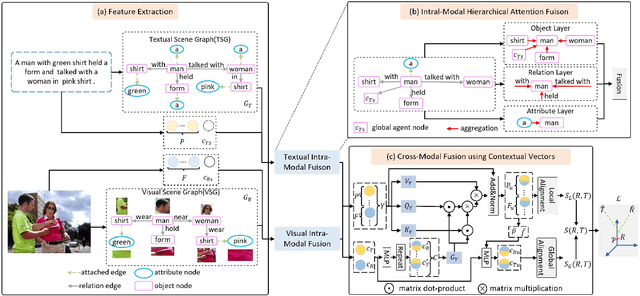

A critical challenge to image-text retrieval is how to learn accurate correspondences between images and texts. Most existing methods mainly focus on coarse-grained correspondences based on co-occurrences of semantic objects, while failing to distinguish the fine-grained local correspondences. In this paper, we propose a novel Scene Graph based Fusion Network (dubbed SGFN), which enhances the images'/texts' features through intra- and cross-modal fusion for image-text retrieval. To be specific, we design an intra-modal hierarchical attention fusion to incorporate semantic contexts, such as objects, attributes, and relationships, into images'/texts' feature vectors via scene graphs, and a cross-modal attention fusion to combine the contextual semantics and local fusion via contextual vectors. Extensive experiments on public datasets Flickr30K and MSCOCO show that our SGFN performs better than quite a few SOTA image-text retrieval methods.
FedScore: A privacy-preserving framework for federated scoring system development
Mar 01, 2023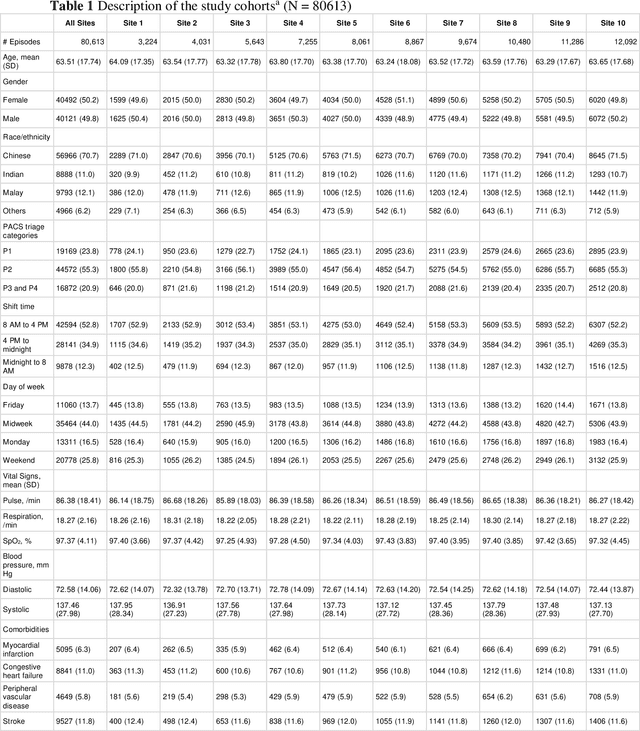
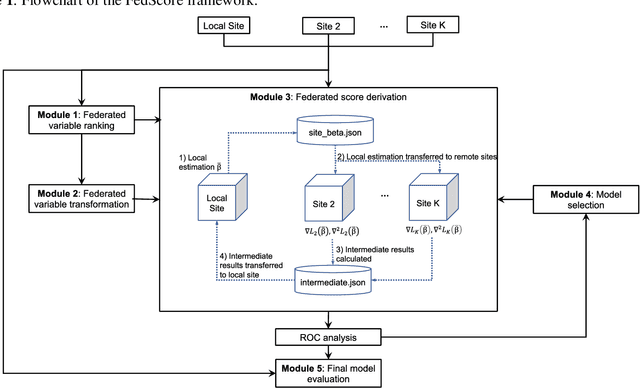

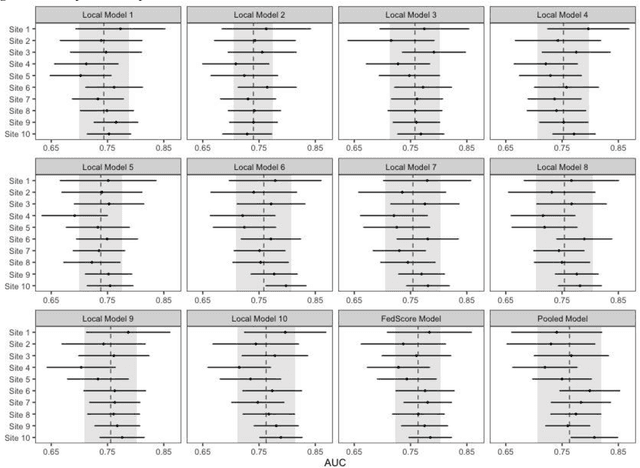
We propose FedScore, a privacy-preserving federated learning framework for scoring system generation across multiple sites to facilitate cross-institutional collaborations. The FedScore framework includes five modules: federated variable ranking, federated variable transformation, federated score derivation, federated model selection and federated model evaluation. To illustrate usage and assess FedScore's performance, we built a hypothetical global scoring system for mortality prediction within 30 days after a visit to an emergency department using 10 simulated sites divided from a tertiary hospital in Singapore. We employed a pre-existing score generator to construct 10 local scoring systems independently at each site and we also developed a scoring system using centralized data for comparison. We compared the acquired FedScore model's performance with that of other scoring models using the receiver operating characteristic (ROC) analysis. The FedScore model achieved an average area under the curve (AUC) value of 0.763 across all sites, with a standard deviation (SD) of 0.020. We also calculated the average AUC values and SDs for each local model, and the FedScore model showed promising accuracy and stability with a high average AUC value which was closest to the one of the pooled model and SD which was lower than that of most local models. This study demonstrates that FedScore is a privacy-preserving scoring system generator with potentially good generalizability.
Beyond Graph Convolutional Network: An Interpretable Regularizer-centered Optimization Framework
Jan 11, 2023
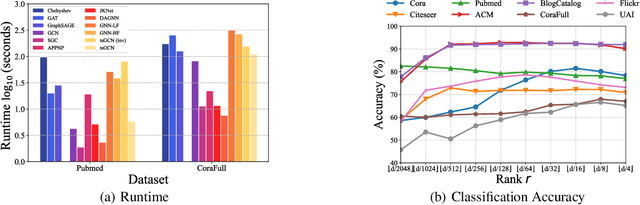
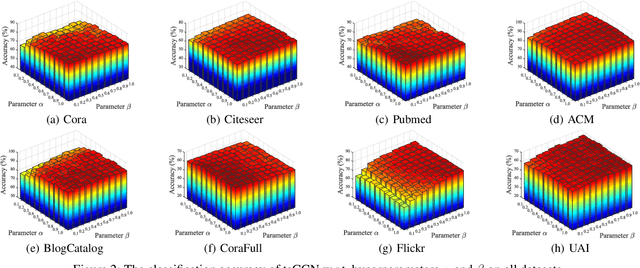
Graph convolutional networks (GCNs) have been attracting widespread attentions due to their encouraging performance and powerful generalizations. However, few work provide a general view to interpret various GCNs and guide GCNs' designs. In this paper, by revisiting the original GCN, we induce an interpretable regularizer-centerd optimization framework, in which by building appropriate regularizers we can interpret most GCNs, such as APPNP, JKNet, DAGNN, and GNN-LF/HF. Further, under the proposed framework, we devise a dual-regularizer graph convolutional network (dubbed tsGCN) to capture topological and semantic structures from graph data. Since the derived learning rule for tsGCN contains an inverse of a large matrix and thus is time-consuming, we leverage the Woodbury matrix identity and low-rank approximation tricks to successfully decrease the high computational complexity of computing infinite-order graph convolutions. Extensive experiments on eight public datasets demonstrate that tsGCN achieves superior performance against quite a few state-of-the-art competitors w.r.t. classification tasks.
TegFormer: Topic-to-Essay Generation with Good Topic Coverage and High Text Coherence
Dec 27, 2022
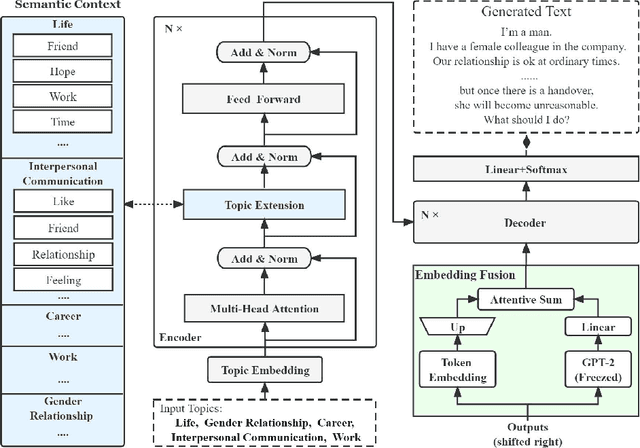
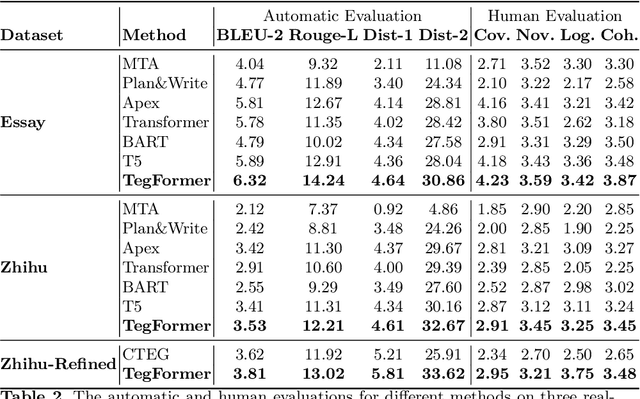
Creating an essay based on a few given topics is a challenging NLP task. Although several effective methods for this problem, topic-to-essay generation, have appeared recently, there is still much room for improvement, especially in terms of the coverage of the given topics and the coherence of the generated text. In this paper, we propose a novel approach called TegFormer which utilizes the Transformer architecture where the encoder is enriched with domain-specific contexts while the decoder is enhanced by a large-scale pre-trained language model. Specifically, a \emph{Topic-Extension} layer capturing the interaction between the given topics and their domain-specific contexts is plugged into the encoder. Since the given topics are usually concise and sparse, such an additional layer can bring more topic-related semantics in to facilitate the subsequent natural language generation. Moreover, an \emph{Embedding-Fusion} module that combines the domain-specific word embeddings learnt from the given corpus and the general-purpose word embeddings provided by a GPT-2 model pre-trained on massive text data is integrated into the decoder. Since GPT-2 is at a much larger scale, it contains a lot more implicit linguistic knowledge which would help the decoder to produce more grammatical and readable text. Extensive experiments have shown that the pieces of text generated by TegFormer have better topic coverage and higher text coherence than those from SOTA topic-to-essay techniques, according to automatic and human evaluations. As revealed by ablation studies, both the Topic-Extension layer and the Embedding-Fusion module contribute substantially to TegFormer's performance advantage.
A Survey on Knowledge-Enhanced Pre-trained Language Models
Dec 27, 2022
Natural Language Processing (NLP) has been revolutionized by the use of Pre-trained Language Models (PLMs) such as BERT. Despite setting new records in nearly every NLP task, PLMs still face a number of challenges including poor interpretability, weak reasoning capability, and the need for a lot of expensive annotated data when applied to downstream tasks. By integrating external knowledge into PLMs, \textit{\underline{K}nowledge-\underline{E}nhanced \underline{P}re-trained \underline{L}anguage \underline{M}odels} (KEPLMs) have the potential to overcome the above-mentioned limitations. In this paper, we examine KEPLMs systematically through a series of studies. Specifically, we outline the common types and different formats of knowledge to be integrated into KEPLMs, detail the existing methods for building and evaluating KEPLMS, present the applications of KEPLMs in downstream tasks, and discuss the future research directions. Researchers will benefit from this survey by gaining a quick and comprehensive overview of the latest developments in this field.
Mining On Alzheimer's Diseases Related Knowledge Graph to Identity Potential AD-related Semantic Triples for Drug Repurposing
Feb 17, 2022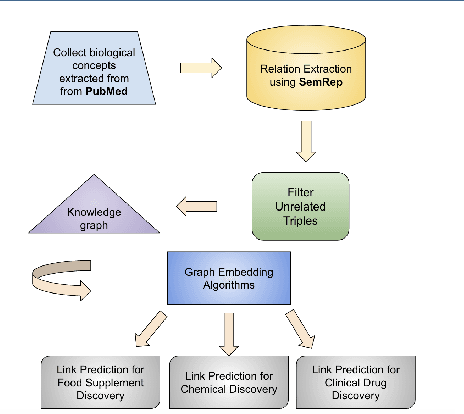

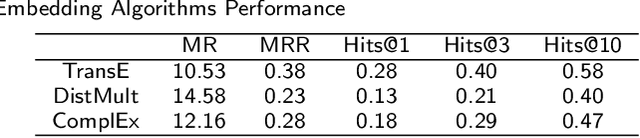
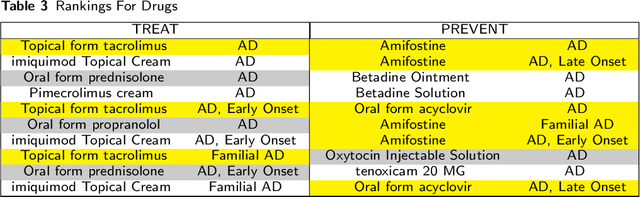
To date, there are no effective treatments for most neurodegenerative diseases. Knowledge graphs can provide comprehensive and semantic representation for heterogeneous data, and have been successfully leveraged in many biomedical applications including drug repurposing. Our objective is to construct a knowledge graph from literature to study relations between Alzheimer's disease (AD) and chemicals, drugs and dietary supplements in order to identify opportunities to prevent or delay neurodegenerative progression. We collected biomedical annotations and extracted their relations using SemRep via SemMedDB. We used both a BERT-based classifier and rule-based methods during data preprocessing to exclude noise while preserving most AD-related semantic triples. The 1,672,110 filtered triples were used to train with knowledge graph completion algorithms (i.e., TransE, DistMult, and ComplEx) to predict candidates that might be helpful for AD treatment or prevention. Among three knowledge graph completion models, TransE outperformed the other two (MR = 13.45, Hits@1 = 0.306). We leveraged the time-slicing technique to further evaluate the prediction results. We found supporting evidence for most highly ranked candidates predicted by our model which indicates that our approach can inform reliable new knowledge. This paper shows that our graph mining model can predict reliable new relationships between AD and other entities (i.e., dietary supplements, chemicals, and drugs). The knowledge graph constructed can facilitate data-driven knowledge discoveries and the generation of novel hypotheses.
Federated Learning Algorithms for Generalized Mixed-effects Model (GLMM) on Horizontally Partitioned Data from Distributed Sources
Sep 28, 2021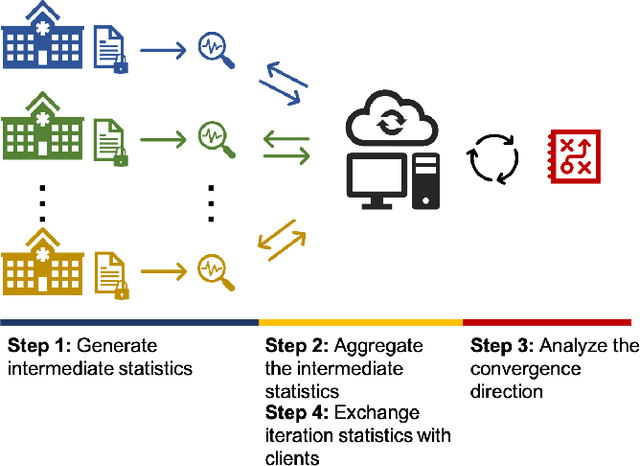
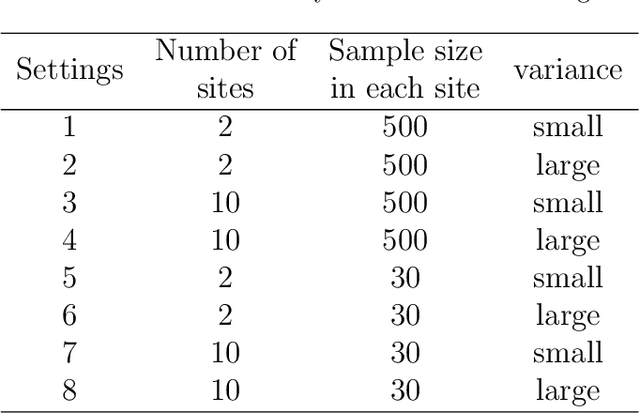
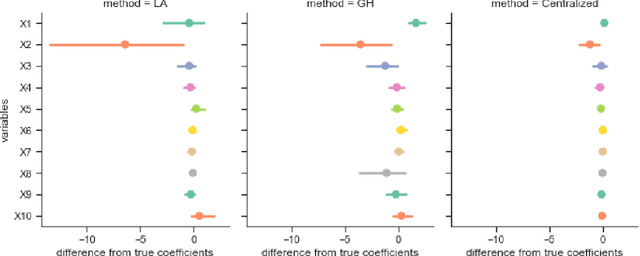
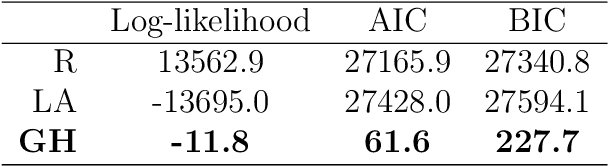
Objectives: This paper develops two algorithms to achieve federated generalized linear mixed effect models (GLMM), and compares the developed model's outcomes with each other, as well as that from the standard R package (`lme4'). Methods: The log-likelihood function of GLMM is approximated by two numerical methods (Laplace approximation and Gaussian Hermite approximation), which supports federated decomposition of GLMM to bring computation to data. Results: Our developed method can handle GLMM to accommodate hierarchical data with multiple non-independent levels of observations in a federated setting. The experiment results demonstrate comparable (Laplace) and superior (Gaussian-Hermite) performances with simulated and real-world data. Conclusion: We developed and compared federated GLMMs with different approximations, which can support researchers in analyzing biomedical data to accommodate mixed effects and address non-independence due to hierarchical structures (i.e., institutes, region, country, etc.).