 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast AdvProp
Apr 21, 2022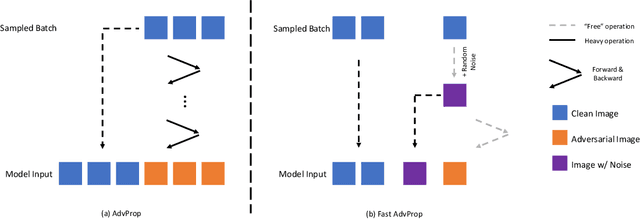


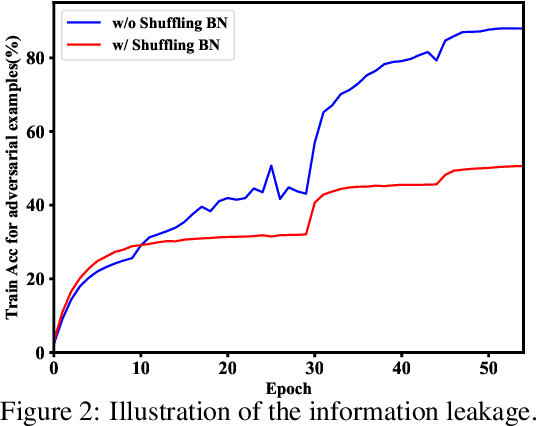
Adversarial Propagation (AdvProp) is an effective way to improve recognition models, leveraging adversarial examples. Nonetheless, AdvProp suffers from the extremely slow training speed, mainly because: a) extra forward and backward passes are required for generating adversarial examples; b) both original samples and their adversarial counterparts are used for training (i.e., 2$\times$ data). In this paper, we introduce Fast AdvProp, which aggressively revamps AdvProp's costly training components, rendering the method nearly as cheap as the vanilla training. Specifically, our modifications in Fast AdvProp are guided by the hypothesis that disentangled learning with adversarial examples is the key for performance improvements, while other training recipes (e.g., paired clean and adversarial training samples, multi-step adversarial attackers) could be largely simplified. Our empirical results show that, compared to the vanilla training baseline, Fast AdvProp is able to further model performance on a spectrum of visual benchmarks, without incurring extra training cost. Additionally, our ablations find Fast AdvProp scales better if larger models are used, is compatible with existing data augmentation methods (i.e., Mixup and CutMix), and can be easily adapted to other recognition tasks like object detection. The code is available here: https://github.com/meijieru/fast_advprop.
SwapMix: Diagnosing and Regularizing the Over-Reliance on Visual Context in Visual Question Answering
Apr 05, 2022

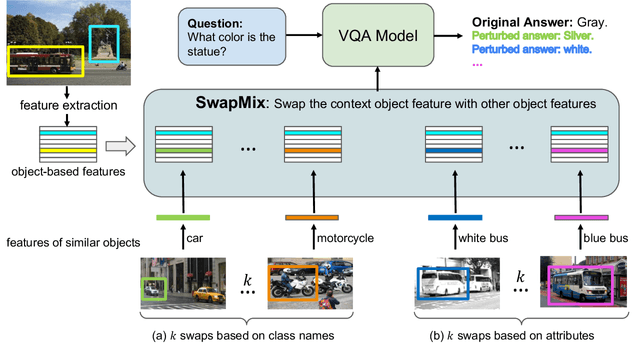
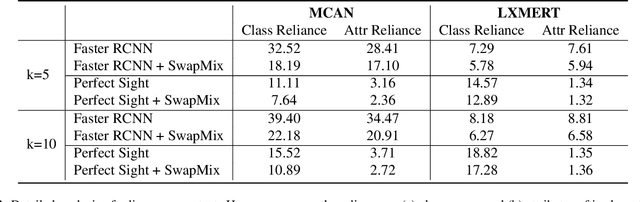
While Visual Question Answering (VQA) has progressed rapidly, previous works raise concerns about robustness of current VQA models. In this work, we study the robustness of VQA models from a novel perspective: visual context. We suggest that the models over-rely on the visual context, i.e., irrelevant objects in the image, to make predictions. To diagnose the model's reliance on visual context and measure their robustness, we propose a simple yet effective perturbation technique, SwapMix. SwapMix perturbs the visual context by swapping features of irrelevant context objects with features from other objects in the dataset. Using SwapMix we are able to change answers to more than 45 % of the questions for a representative VQA model. Additionally, we train the models with perfect sight and find that the context over-reliance highly depends on the quality of visual representations. In addition to diagnosing, SwapMix can also be applied as a data augmentation strategy during training in order to regularize the context over-reliance. By swapping the context object features, the model reliance on context can be suppressed effectively. Two representative VQA models are studied using SwapMix: a co-attention model MCAN and a large-scale pretrained model LXMERT. Our experiments on the popular GQA dataset show the effectiveness of SwapMix for both diagnosing model robustness and regularizing the over-reliance on visual context. The code for our method is available at https://github.com/vipulgupta1011/swapmix
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
Mar 15, 2022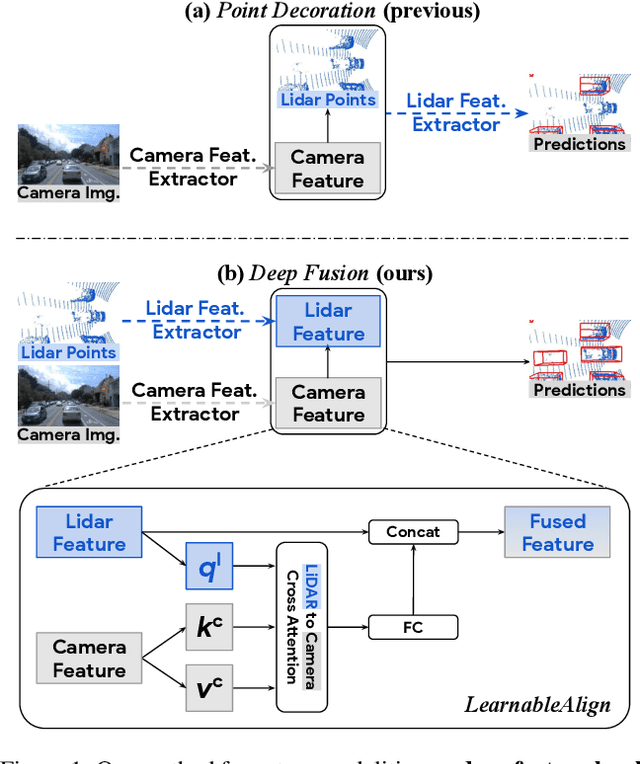
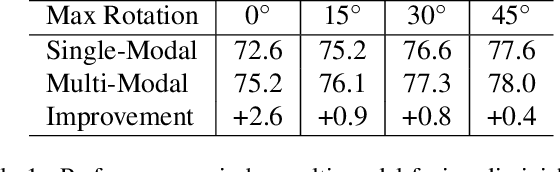
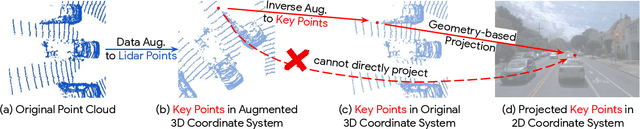
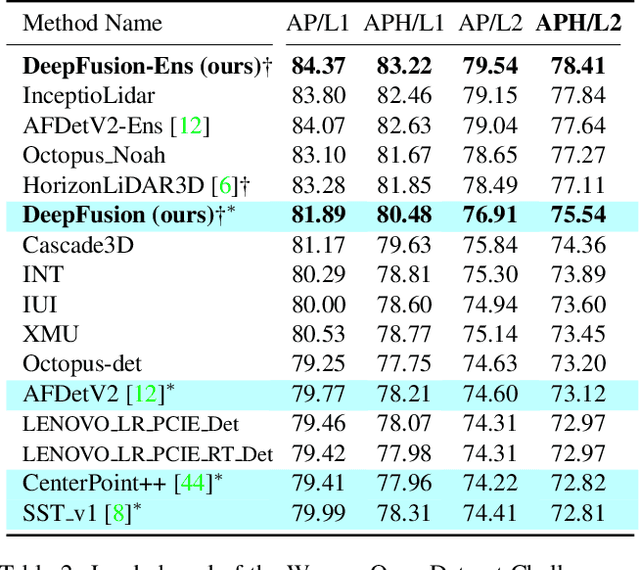
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While prevalent multi-modal methods simply decorate raw lidar point clouds with camera features and feed them directly to existing 3D detection models, our study shows that fusing camera features with deep lidar features instead of raw points, can lead to better performance. However, as those features are often augmented and aggregated, a key challenge in fusion is how to effectively align the transformed features from two modalities. In this paper, we propose two novel techniques: InverseAug that inverses geometric-related augmentations, e.g., rotation, to enable accurate geometric alignment between lidar points and image pixels, and LearnableAlign that leverages cross-attention to dynamically capture the correlations between image and lidar features during fusion. Based on InverseAug and LearnableAlign, we develop a family of generic multi-modal 3D detection models named DeepFusion, which is more accurate than previous methods. For example, DeepFusion improves PointPillars, CenterPoint, and 3D-MAN baselines on Pedestrian detection for 6.7, 8.9, and 6.2 LEVEL_2 APH, respectively. Notably, our models achieve state-of-the-art performance on Waymo Open Dataset, and show strong model robustness against input corruptions and out-of-distribution data. Code will be publicly available at https://github.com/tensorflow/lingvo/tree/master/lingvo/.
Learning from Temporal Gradient for Semi-supervised Action Recognition
Dec 06, 2021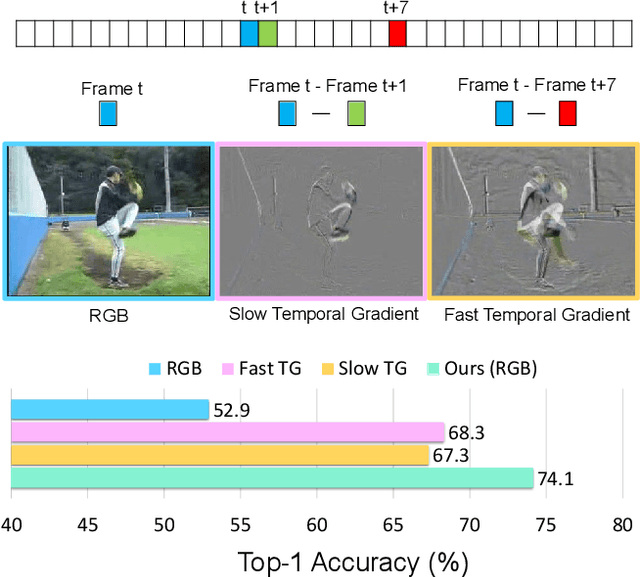
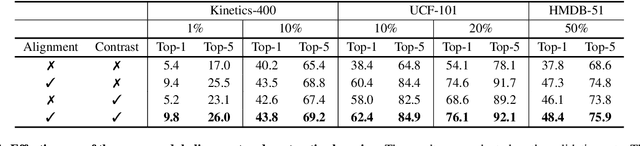
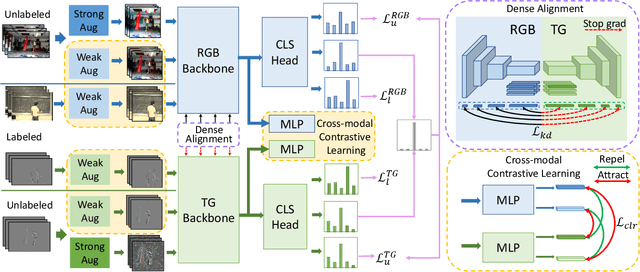
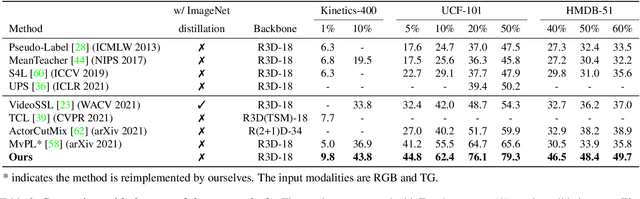
Semi-supervised video action recognition tends to enable deep neural networks to achieve remarkable performance even with very limited labeled data. However, existing methods are mainly transferred from current image-based methods (e.g., FixMatch). Without specifically utilizing the temporal dynamics and inherent multimodal attributes, their results could be suboptimal. To better leverage the encoded temporal information in videos, we introduce temporal gradient as an additional modality for more attentive feature extraction in this paper. To be specific, our method explicitly distills the fine-grained motion representations from temporal gradient (TG) and imposes consistency across different modalities (i.e., RGB and TG). The performance of semi-supervised action recognition is significantly improved without additional computation or parameters during inference. Our method achieves the state-of-the-art performance on three video action recognition benchmarks (i.e., Kinetics-400, UCF-101, and HMDB-51) under several typical semi-supervised settings (i.e., different ratios of labeled data).
Searching for TrioNet: Combining Convolution with Local and Global Self-Attention
Nov 15, 2021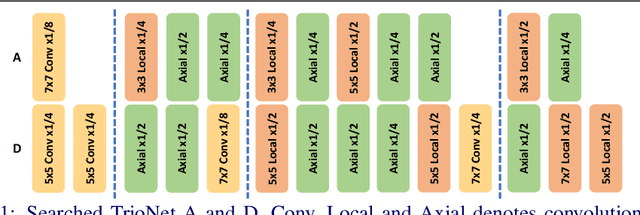
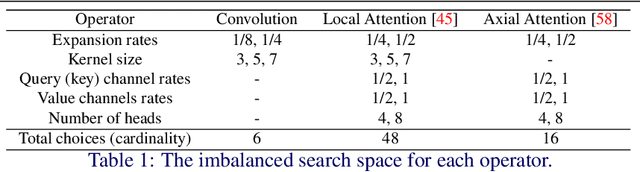
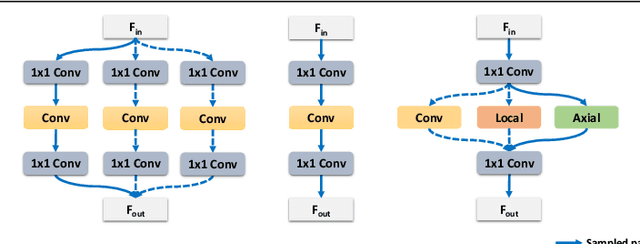
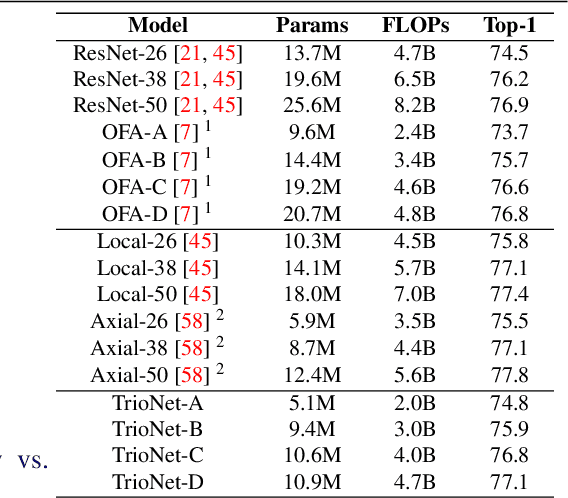
Recently, self-attention operators have shown superior performance as a stand-alone building block for vision models. However, existing self-attention models are often hand-designed, modified from CNNs, and obtained by stacking one operator only. A wider range of architecture space which combines different self-attention operators and convolution is rarely explored. In this paper, we explore this novel architecture space with weight-sharing Neural Architecture Search (NAS) algorithms. The result architecture is named TrioNet for combining convolution, local self-attention, and global (axial) self-attention operators. In order to effectively search in this huge architecture space, we propose Hierarchical Sampling for better training of the supernet. In addition, we propose a novel weight-sharing strategy, Multi-head Sharing, specifically for multi-head self-attention operators. Our searched TrioNet that combines self-attention and convolution outperforms all stand-alone models with fewer FLOPs on ImageNet classification where self-attention performs better than convolution. Furthermore, on various small datasets, we observe inferior performance for self-attention models, but our TrioNet is still able to match the best operator, convolution in this case. Our code is available at https://github.com/phj128/TrioNet.
Harnessing Perceptual Adversarial Patches for Crowd Counting
Sep 16, 2021
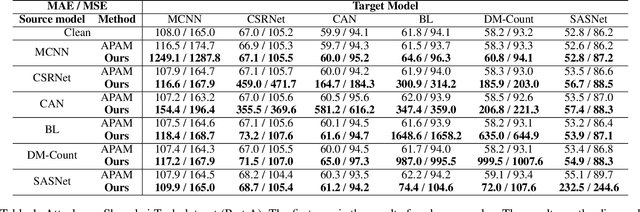
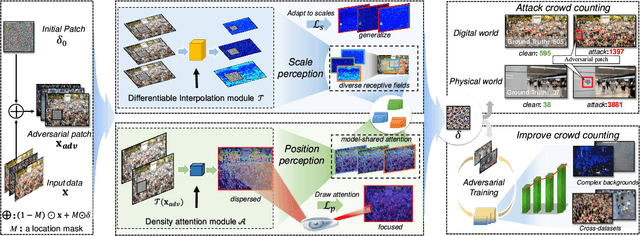
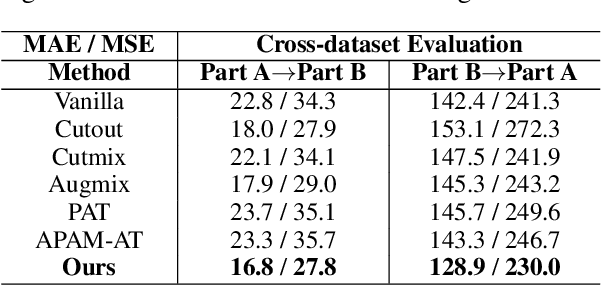
Crowd counting, which is significantly important for estimating the number of people in safety-critical scenes, has been shown to be vulnerable to adversarial examples in the physical world (e.g., adversarial patches). Though harmful, adversarial examples are also valuable for assessing and better understanding model robustness. However, existing adversarial example generation methods in crowd counting scenarios lack strong transferability among different black-box models. Motivated by the fact that transferability is positively correlated to the model-invariant characteristics, this paper proposes the Perceptual Adversarial Patch (PAP) generation framework to learn the shared perceptual features between models by exploiting both the model scale perception and position perception. Specifically, PAP exploits differentiable interpolation and density attention to help learn the invariance between models during training, leading to better transferability. In addition, we surprisingly found that our adversarial patches could also be utilized to benefit the performance of vanilla models for alleviating several challenges including cross datasets and complex backgrounds. Extensive experiments under both digital and physical world scenarios demonstrate the effectiveness of our PAP.
Volumetric Medical Image Segmentation: A 3D Deep Coarse-to-fine Framework and Its Adversarial Examples
Oct 29, 2020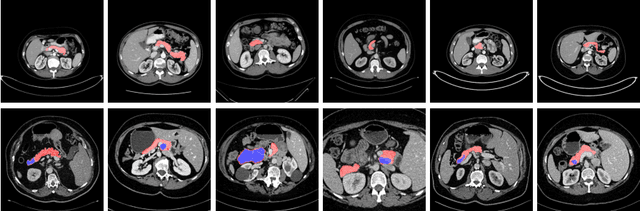
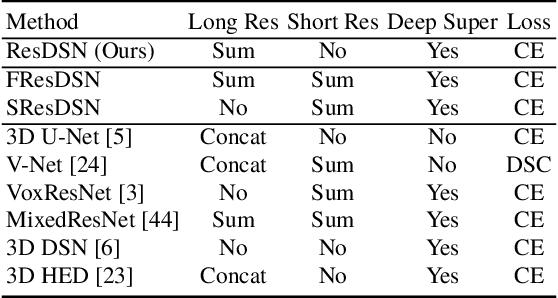

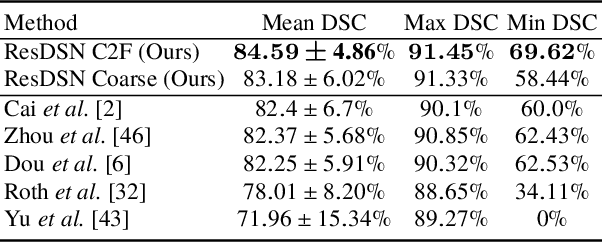
Although deep neural networks have been a dominant method for many 2D vision tasks, it is still challenging to apply them to 3D tasks, such as medical image segmentation, due to the limited amount of annotated 3D data and limited computational resources. In this chapter, by rethinking the strategy to apply 3D Convolutional Neural Networks to segment medical images, we propose a novel 3D-based coarse-to-fine framework to efficiently tackle these challenges. The proposed 3D-based framework outperforms their 2D counterparts by a large margin since it can leverage the rich spatial information along all three axes. We further analyze the threat of adversarial attacks on the proposed framework and show how to defense against the attack. We conduct experiments on three datasets, the NIH pancreas dataset, the JHMI pancreas dataset and the JHMI pathological cyst dataset, where the first two and the last one contain healthy and pathological pancreases respectively, and achieve the current state-of-the-art in terms of Dice-Sorensen Coefficient (DSC) on all of them. Especially, on the NIH pancreas segmentation dataset, we outperform the previous best by an average of over $2\%$, and the worst case is improved by $7\%$ to reach almost $70\%$, which indicates the reliability of our framework in clinical applications.
Shape-Texture Debiased Neural Network Training
Oct 12, 2020

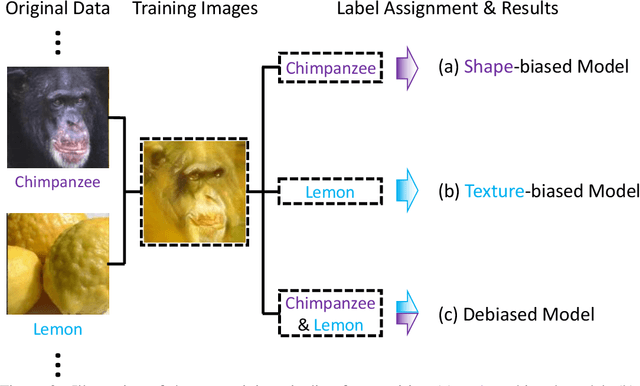
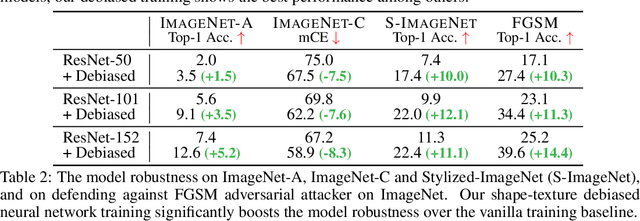
Shape and texture are two prominent and complementary cues for recognizing objects. Nonetheless, Convolutional Neural Networks are often biased towards either texture or shape, depending on the training dataset. Our ablation shows that such bias degenerates model performance. Motivated by this observation, we develop a simple algorithm for shape-texture debiased learning. To prevent models from exclusively attending on a single cue in representation learning, we augment training data with images with conflicting shape and texture information (e.g., an image of chimpanzee shape but with lemon texture) and, most importantly, provide the corresponding supervisions from shape and texture simultaneously. Experiments show that our method successfully improves model performance on several image recognition benchmarks and adversarial robustness. For example, by training on ImageNet, it helps ResNet-152 achieve substantial improvements on ImageNet (+1.2%), ImageNet-A (+5.2%), ImageNet-C (+8.3%) and Stylized-ImageNet (+11.1%), and on defending against FGSM adversarial attacker on ImageNet (+14.4%). Our method also claims to be compatible to other advanced data augmentation strategies, e.g., Mixup and CutMix. The code is available here: https://github.com/LiYingwei/ShapeTextureDebiasedTraining.
Neural Architecture Search for Lightweight Non-Local Networks
Apr 04, 2020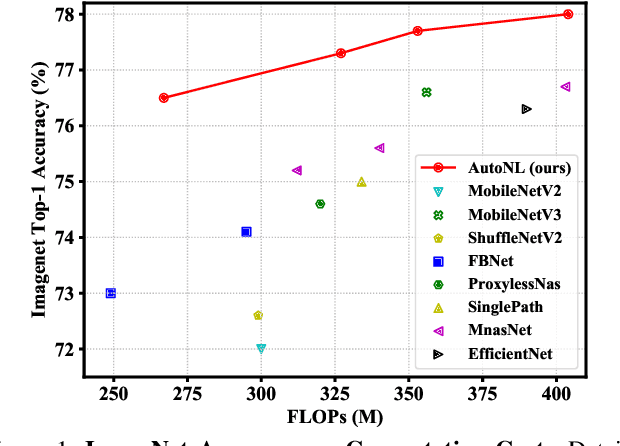

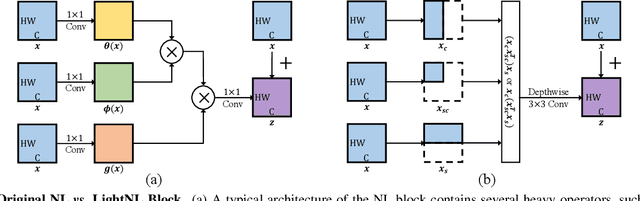

Non-Local (NL) blocks have been widely studied in various vision tasks. However, it has been rarely explored to embed the NL blocks in mobile neural networks, mainly due to the following challenges: 1) NL blocks generally have heavy computation cost which makes it difficult to be applied in applications where computational resources are limited, and 2) it is an open problem to discover an optimal configuration to embed NL blocks into mobile neural networks. We propose AutoNL to overcome the above two obstacles. Firstly, we propose a Lightweight Non-Local (LightNL) block by squeezing the transformation operations and incorporating compact features. With the novel design choices, the proposed LightNL block is 400x computationally cheaper} than its conventional counterpart without sacrificing the performance. Secondly, by relaxing the structure of the LightNL block to be differentiable during training, we propose an efficient neural architecture search algorithm to learn an optimal configuration of LightNL blocks in an end-to-end manner. Notably, using only 32 GPU hours, the searched AutoNL model achieves 77.7% top-1 accuracy on ImageNet under a typical mobile setting (350M FLOPs), significantly outperforming previous mobile models including MobileNetV2 (+5.7%), FBNet (+2.8%) and MnasNet (+2.1%). Code and models are available at https://github.com/LiYingwei/AutoNL.
CAKES: Channel-wise Automatic KErnel Shrinking for Efficient 3D Network
Mar 28, 2020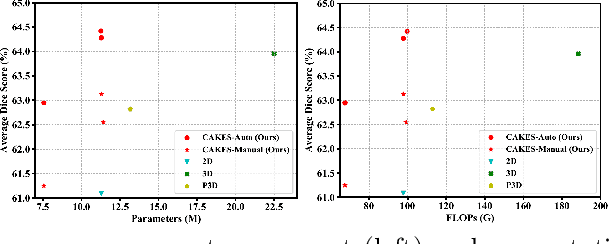
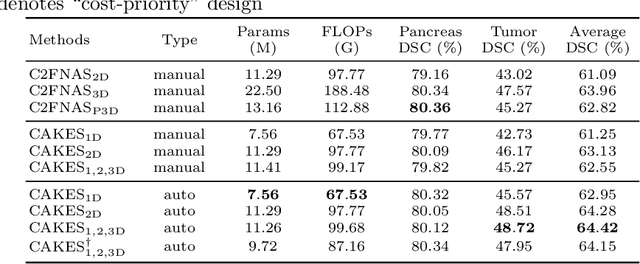
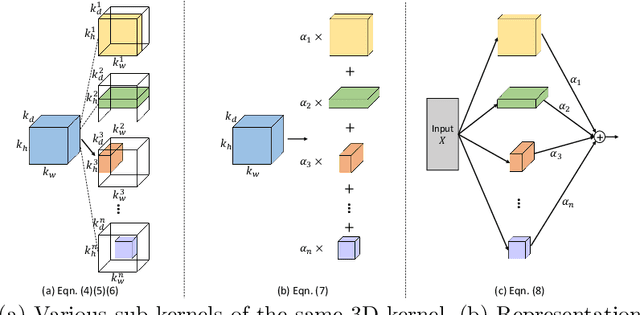
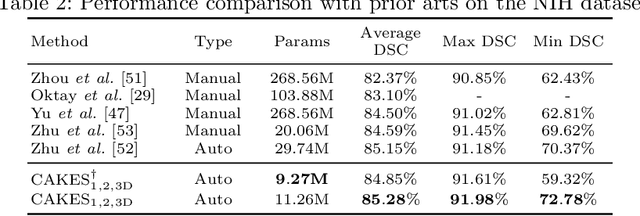
3D Convolution Neural Networks (CNNs) have been widely applied to 3D scene understanding, such as video analysis and volumetric image recognition. However, 3D networks can easily lead to over-parameterization which incurs expensive computation cost. In this paper, we propose Channel-wise Automatic KErnel Shrinking (CAKES), to enable efficient 3D learning by shrinking standard 3D convolutions into a set of economic operations (e.g., 1D, 2D convolutions). Unlike previous methods, our proposed CAKES performs channel-wise kernel shrinkage, which enjoys the following benefits: 1) encouraging operations deployed in every layer to be heterogeneous, so that they can extract diverse and complementary information to benefit the learning process; and 2) allowing for an efficient and flexible replacement design, which can be generalized to both spatial-temporal and volumetric data. Together with a neural architecture search framework, by applying CAKES to 3D C2FNAS and ResNet50, we achieve the state-of-the-art performance with much fewer parameters and computational costs on both 3D medical imaging segmentation and video action recognition.