 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Training Data Synthesis for Improving MLLM Chart Understanding
Aug 08, 2025Being able to effectively read scientific plots, or chart understanding, is a central part toward building effective agents for science. However, existing multimodal large language models (MLLMs), especially open-source ones, are still falling behind with a typical success rate of 30%-50% on challenging benchmarks. Previous studies on fine-tuning MLLMs with synthetic charts are often restricted by their inadequate similarity to the real charts, which could compromise model training and performance on complex real-world charts. In this study, we show that modularizing chart generation and diversifying visual details improves chart understanding capabilities. In particular, we design a five-step data synthesis pipeline, where we separate data and function creation for single plot generation, condition the generation of later subplots on earlier ones for multi-subplot figures, visually diversify the generated figures, filter out low quality data, and finally generate the question-answer (QA) pairs with GPT-4o. This approach allows us to streamline the generation of fine-tuning datasets and introduce the effective chart dataset (ECD), which contains 10k+ chart images and 300k+ QA pairs, covering 25 topics and featuring 250+ chart type combinations with high visual complexity. We show that ECD consistently improves the performance of various MLLMs on a range of real-world and synthetic test sets. Code, data and models are available at: https://github.com/yuweiyang-anu/ECD.
Reasoning-Enhanced Self-Training for Long-Form Personalized Text Generation
Jan 07, 2025Personalized text generation requires a unique ability of large language models (LLMs) to learn from context that they often do not encounter during their standard training. One way to encourage LLMs to better use personalized context for generating outputs that better align with the user's expectations is to instruct them to reason over the user's past preferences, background knowledge, or writing style. To achieve this, we propose Reasoning-Enhanced Self-Training for Personalized Text Generation (REST-PG), a framework that trains LLMs to reason over personal data during response generation. REST-PG first generates reasoning paths to train the LLM's reasoning abilities and then employs Expectation-Maximization Reinforced Self-Training to iteratively train the LLM based on its own high-reward outputs. We evaluate REST-PG on the LongLaMP benchmark, consisting of four diverse personalized long-form text generation tasks. Our experiments demonstrate that REST-PG achieves significant improvements over state-of-the-art baselines, with an average relative performance gain of 14.5% on the benchmark.
ExoViP: Step-by-step Verification and Exploration with Exoskeleton Modules for Compositional Visual Reasoning
Aug 05, 2024Compositional visual reasoning methods, which translate a complex query into a structured composition of feasible visual tasks, have exhibited a strong potential in complicated multi-modal tasks. Empowered by recent advances in large language models (LLMs), this multi-modal challenge has been brought to a new stage by treating LLMs as few-shot/zero-shot planners, i.e., vision-language (VL) programming. Such methods, despite their numerous merits, suffer from challenges due to LLM planning mistakes or inaccuracy of visual execution modules, lagging behind the non-compositional models. In this work, we devise a "plug-and-play" method, ExoViP, to correct errors in both the planning and execution stages through introspective verification. We employ verification modules as "exoskeletons" to enhance current VL programming schemes. Specifically, our proposed verification module utilizes a mixture of three sub-verifiers to validate predictions after each reasoning step, subsequently calibrating the visual module predictions and refining the reasoning trace planned by LLMs. Experimental results on two representative VL programming methods showcase consistent improvements on five compositional reasoning tasks on standard benchmarks. In light of this, we believe that ExoViP can foster better performance and generalization on open-domain multi-modal challenges.
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
Jul 23, 2024Retrieval Augmented Generation (RAG) has been a powerful tool for Large Language Models (LLMs) to efficiently process overly lengthy contexts. However, recent LLMs like Gemini-1.5 and GPT-4 show exceptional capabilities to understand long contexts directly. We conduct a comprehensive comparison between RAG and long-context (LC) LLMs, aiming to leverage the strengths of both. We benchmark RAG and LC across various public datasets using three latest LLMs. Results reveal that when resourced sufficiently, LC consistently outperforms RAG in terms of average performance. However, RAG's significantly lower cost remains a distinct advantage. Based on this observation, we propose Self-Route, a simple yet effective method that routes queries to RAG or LC based on model self-reflection. Self-Route significantly reduces the computation cost while maintaining a comparable performance to LC. Our findings provide a guideline for long-context applications of LLMs using RAG and LC.
Synthesize Step-by-Step: Tools, Templates and LLMs as Data Generators for Reasoning-Based Chart VQA
Mar 28, 2024



Understanding data visualizations like charts and plots requires reasoning about both visual elements and numerics. Although strong in extractive questions, current chart visual question answering (chart VQA) models suffer on complex reasoning questions. In this work, we address the lack of reasoning ability by data augmentation. We leverage Large Language Models (LLMs), which have shown to have strong reasoning ability, as an automatic data annotator that generates question-answer annotations for chart images. The key innovation in our method lies in the Synthesize Step-by-Step strategy: our LLM-based data generator learns to decompose the complex question into step-by-step sub-questions (rationales), which are then used to derive the final answer using external tools, i.e. Python. This step-wise generation procedure is trained on synthetic data generated using a template-based QA generation pipeline. Experimental results highlight the significance of the proposed step-by-step generation. By training with the LLM-augmented data (LAMENDA), we significantly enhance the chart VQA models, achieving the state-of-the-art accuracy on the ChartQA and PlotQA datasets. In particular, our approach improves the accuracy of the previous state-of-the-art approach from 38% to 54% on the human-written questions in the ChartQA dataset, which needs strong reasoning. We hope our work underscores the potential of synthetic data and encourages further exploration of data augmentation using LLMs for reasoning-heavy tasks.
Causal-CoG: A Causal-Effect Look at Context Generation for Boosting Multi-modal Language Models
Dec 09, 2023



While Multi-modal Language Models (MLMs) demonstrate impressive multimodal ability, they still struggle on providing factual and precise responses for tasks like visual question answering (VQA). In this paper, we address this challenge from the perspective of contextual information. We propose Causal Context Generation, Causal-CoG, which is a prompting strategy that engages contextual information to enhance precise VQA during inference. Specifically, we prompt MLMs to generate contexts, i.e, text description of an image, and engage the generated contexts for question answering. Moreover, we investigate the advantage of contexts on VQA from a causality perspective, introducing causality filtering to select samples for which contextual information is helpful. To show the effectiveness of Causal-CoG, we run extensive experiments on 10 multimodal benchmarks and show consistent improvements, e.g., +6.30% on POPE, +13.69% on Vizwiz and +6.43% on VQAv2 compared to direct decoding, surpassing existing methods. We hope Casual-CoG inspires explorations of context knowledge in multimodal models, and serves as a plug-and-play strategy for MLM decoding.
3D-Aware Visual Question Answering about Parts, Poses and Occlusions
Oct 27, 2023



Despite rapid progress in Visual question answering (VQA), existing datasets and models mainly focus on testing reasoning in 2D. However, it is important that VQA models also understand the 3D structure of visual scenes, for example to support tasks like navigation or manipulation. This includes an understanding of the 3D object pose, their parts and occlusions. In this work, we introduce the task of 3D-aware VQA, which focuses on challenging questions that require a compositional reasoning over the 3D structure of visual scenes. We address 3D-aware VQA from both the dataset and the model perspective. First, we introduce Super-CLEVR-3D, a compositional reasoning dataset that contains questions about object parts, their 3D poses, and occlusions. Second, we propose PO3D-VQA, a 3D-aware VQA model that marries two powerful ideas: probabilistic neural symbolic program execution for reasoning and deep neural networks with 3D generative representations of objects for robust visual recognition. Our experimental results show our model PO3D-VQA outperforms existing methods significantly, but we still observe a significant performance gap compared to 2D VQA benchmarks, indicating that 3D-aware VQA remains an important open research area.
Localization vs. Semantics: How Can Language Benefit Visual Representation Learning?
Dec 01, 2022



Despite the superior performance brought by vision-and-language pretraining, it remains unclear whether learning with multi-modal data can help understand each individual modality. In this work, we investigate how language can help with visual representation learning from a probing perspective. Specifically, we compare vision-and-language and vision-only models by probing their visual representations on a broad range of tasks, in order to assess the quality of the learned representations in a fine-grained manner. Interestingly, our probing results suggest that vision-and-language models are better at label prediction tasks like object and attribute prediction, while vision-only models are stronger at dense prediction tasks that require more localized information. With further analysis using detailed metrics, our study suggests that language helps vision models learn better semantics, but not localization. Code is released at https://github.com/Lizw14/visual_probing.
Super-CLEVR: A Virtual Benchmark to Diagnose Domain Robustness in Visual Reasoning
Dec 01, 2022
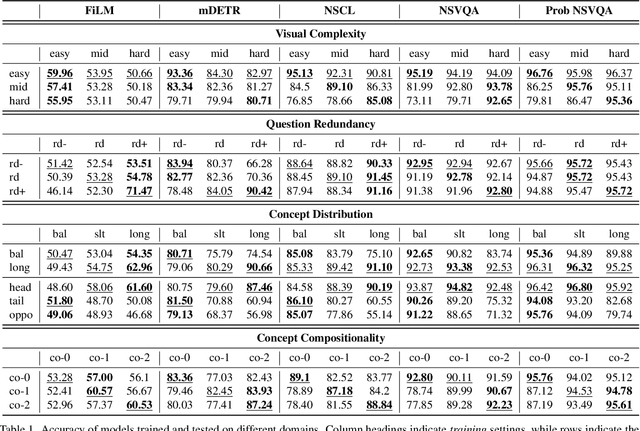
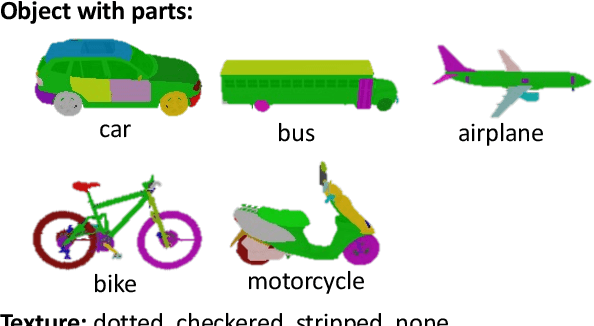
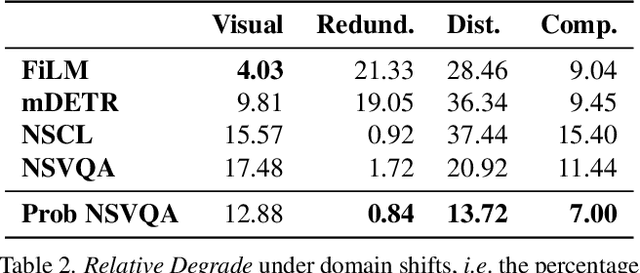
Visual Question Answering (VQA) models often perform poorly on out-of-distribution data and struggle on domain generalization. Due to the multi-modal nature of this task, multiple factors of variation are intertwined, making generalization difficult to analyze. This motivates us to introduce a virtual benchmark, Super-CLEVR, where different factors in VQA domain shifts can be isolated in order that their effects can be studied independently. Four factors are considered: visual complexity, question redundancy, concept distribution and concept compositionality. With controllably generated data, Super-CLEVR enables us to test VQA methods in situations where the test data differs from the training data along each of these axes. We study four existing methods, including two neural symbolic methods NSCL and NSVQA, and two non-symbolic methods FiLM and mDETR; and our proposed method, probabilistic NSVQA (P-NSVQA), which extends NSVQA with uncertainty reasoning. P-NSVQA outperforms other methods on three of the four domain shift factors. Our results suggest that disentangling reasoning and perception, combined with probabilistic uncertainty, form a strong VQA model that is more robust to domain shifts. The dataset and code are released at https://github.com/Lizw14/Super-CLEVR.
Visual Commonsense in Pretrained Unimodal and Multimodal Models
May 04, 2022



Our commonsense knowledge about objects includes their typical visual attributes; we know that bananas are typically yellow or green, and not purple. Text and image corpora, being subject to reporting bias, represent this world-knowledge to varying degrees of faithfulness. In this paper, we investigate to what degree unimodal (language-only) and multimodal (image and language) models capture a broad range of visually salient attributes. To that end, we create the Visual Commonsense Tests (ViComTe) dataset covering 5 property types (color, shape, material, size, and visual co-occurrence) for over 5000 subjects. We validate this dataset by showing that our grounded color data correlates much better than ungrounded text-only data with crowdsourced color judgments provided by Paik et al. (2021). We then use our dataset to evaluate pretrained unimodal models and multimodal models. Our results indicate that multimodal models better reconstruct attribute distributions, but are still subject to reporting bias. Moreover, increasing model size does not enhance performance, suggesting that the key to visual commonsense lies in the data.