 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCTR: On Awakening the Local Continuity of Transformer for Weakly Supervised Object Localization
Dec 10, 2021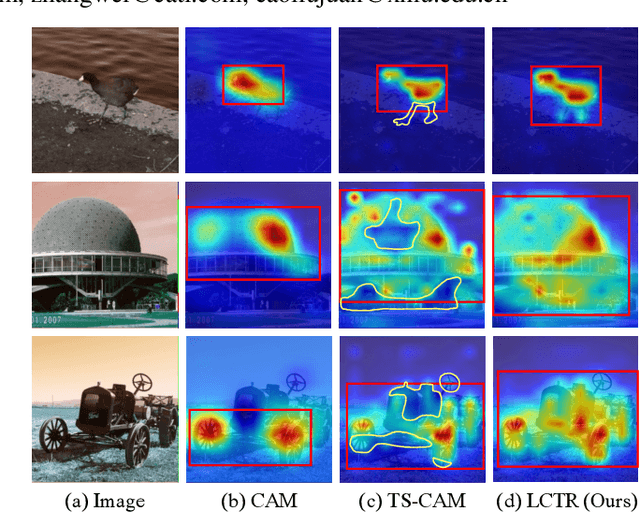
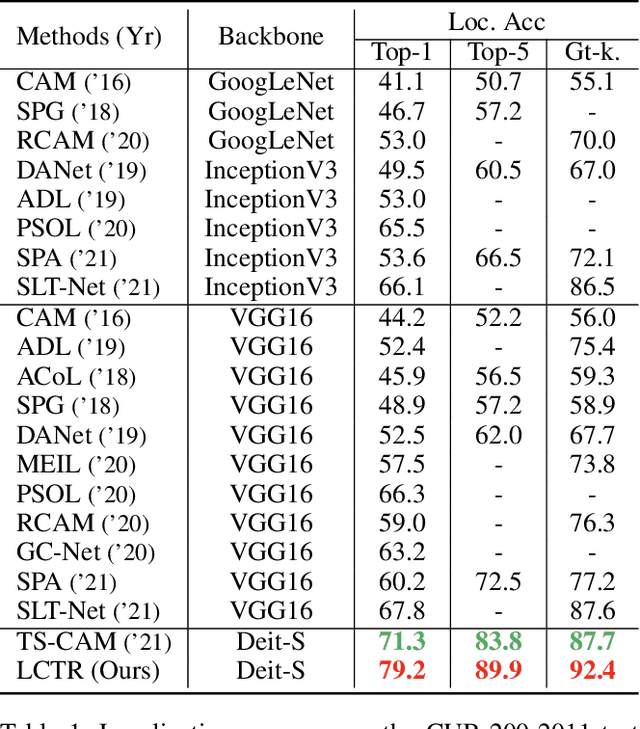
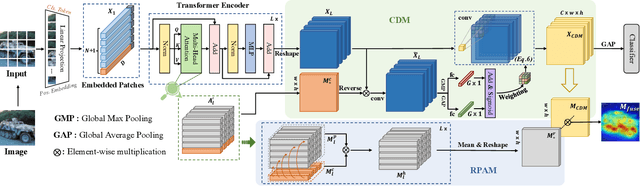
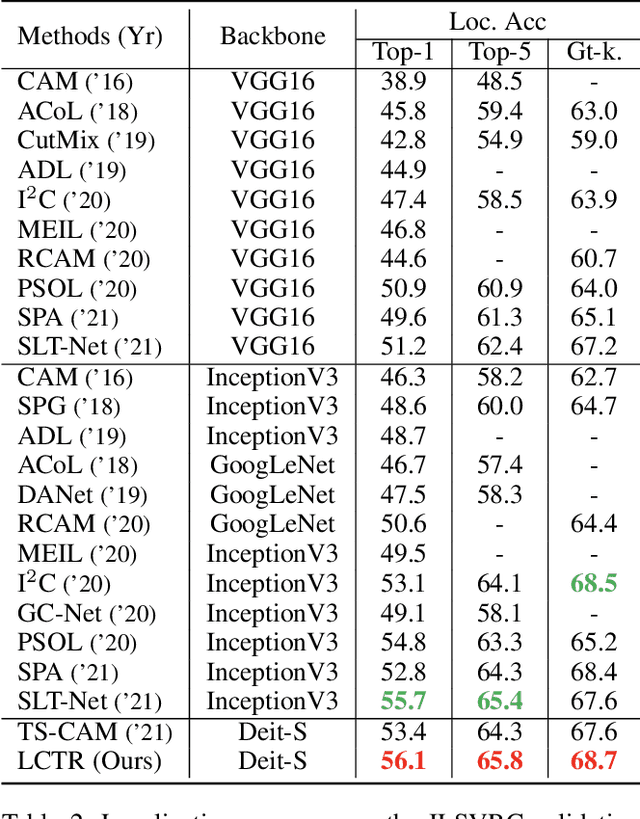
Weakly supervised object localization (WSOL) aims to learn object localizer solely by using image-level labels. The convolution neural network (CNN) based techniques often result in highlighting the most discriminative part of objects while ignoring the entire object extent. Recently, the transformer architecture has been deployed to WSOL to capture the long-range feature dependencies with self-attention mechanism and multilayer perceptron structure. Nevertheless, transformers lack the locality inductive bias inherent to CNNs and therefore may deteriorate local feature details in WSOL. In this paper, we propose a novel framework built upon the transformer, termed LCTR (Local Continuity TRansformer), which targets at enhancing the local perception capability of global features among long-range feature dependencies. To this end, we propose a relational patch-attention module (RPAM), which considers cross-patch information on a global basis. We further design a cue digging module (CDM), which utilizes local features to guide the learning trend of the model for highlighting the weak local responses. Finally, comprehensive experiments are carried out on two widely used datasets, ie, CUB-200-2011 and ILSVRC, to verify the effectiveness of our method.
Fully Context-Aware Image Inpainting with a Learned Semantic Pyramid
Dec 08, 2021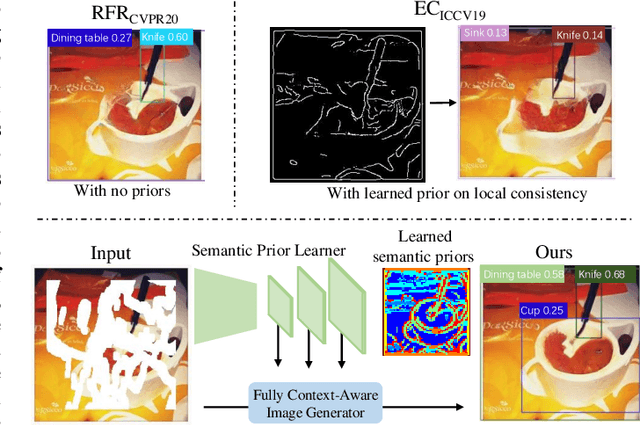

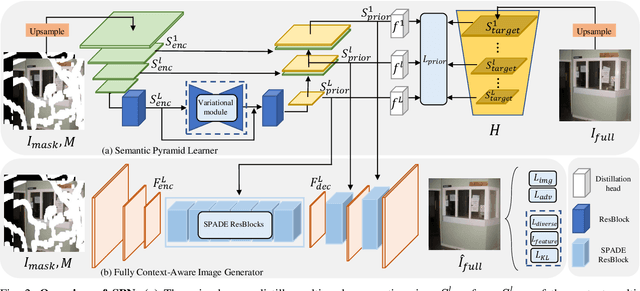
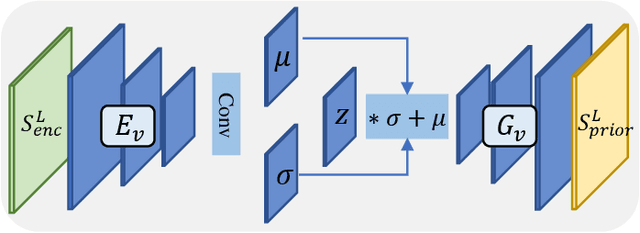
Restoring reasonable and realistic content for arbitrary missing regions in images is an important yet challenging task. Although recent image inpainting models have made significant progress in generating vivid visual details, they can still lead to texture blurring or structural distortions due to contextual ambiguity when dealing with more complex scenes. To address this issue, we propose the Semantic Pyramid Network (SPN) motivated by the idea that learning multi-scale semantic priors from specific pretext tasks can greatly benefit the recovery of locally missing content in images. SPN consists of two components. First, it distills semantic priors from a pretext model into a multi-scale feature pyramid, achieving a consistent understanding of the global context and local structures. Within the prior learner, we present an optional module for variational inference to realize probabilistic image inpainting driven by various learned priors. The second component of SPN is a fully context-aware image generator, which adaptively and progressively refines low-level visual representations at multiple scales with the (stochastic) prior pyramid. We train the prior learner and the image generator as a unified model without any post-processing. Our approach achieves the state of the art on multiple datasets, including Places2, Paris StreetView, CelebA, and CelebA-HQ, under both deterministic and probabilistic inpainting setups.
Spectrum-to-Kernel Translation for Accurate Blind Image Super-Resolution
Oct 23, 2021
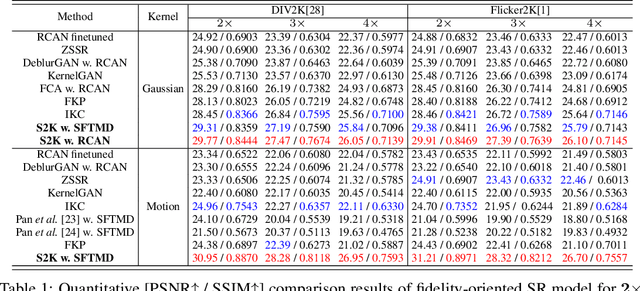
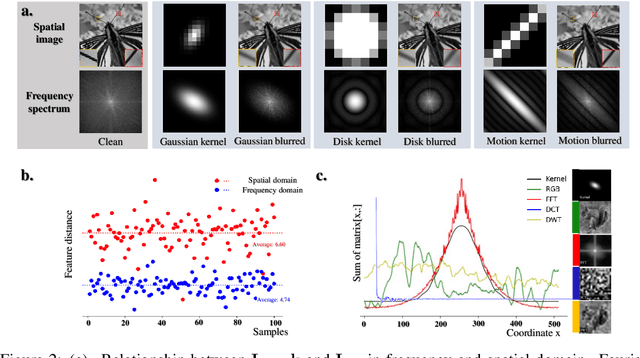
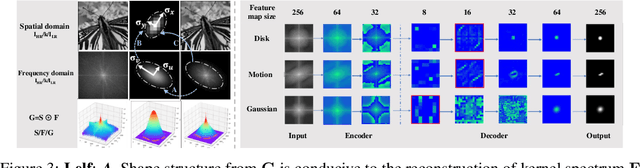
Deep-learning based Super-Resolution (SR) methods have exhibited promising performance under non-blind setting where blur kernel is known. However, blur kernels of Low-Resolution (LR) images in different practical applications are usually unknown. It may lead to significant performance drop when degradation process of training images deviates from that of real images. In this paper, we propose a novel blind SR framework to super-resolve LR images degraded by arbitrary blur kernel with accurate kernel estimation in frequency domain. To our best knowledge, this is the first deep learning method which conducts blur kernel estimation in frequency domain. Specifically, we first demonstrate that feature representation in frequency domain is more conducive for blur kernel reconstruction than in spatial domain. Next, we present a Spectrum-to-Kernel (S$2$K) network to estimate general blur kernels in diverse forms. We use a Conditional GAN (CGAN) combined with SR-oriented optimization target to learn the end-to-end translation from degraded images' spectra to unknown kernels. Extensive experiments on both synthetic and real-world images demonstrate that our proposed method sufficiently reduces blur kernel estimation error, thus enables the off-the-shelf non-blind SR methods to work under blind setting effectively, and achieves superior performance over state-of-the-art blind SR methods, averagely by 1.39dB, 0.48dB on commom blind SR setting (with Gaussian kernels) for scales $2\times$ and $4\times$, respectively.
Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework
Aug 07, 2021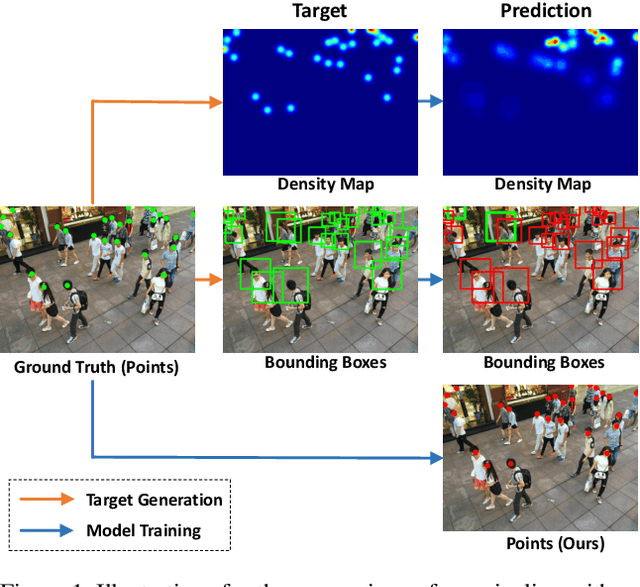
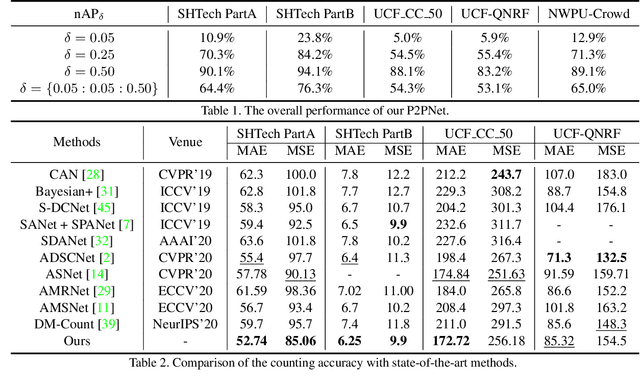
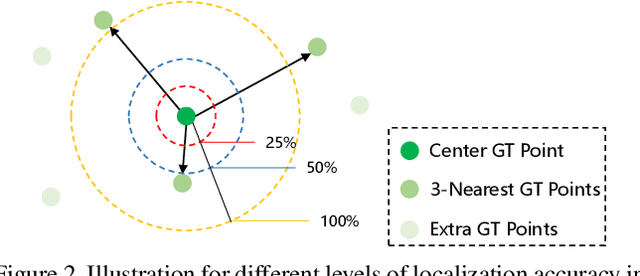
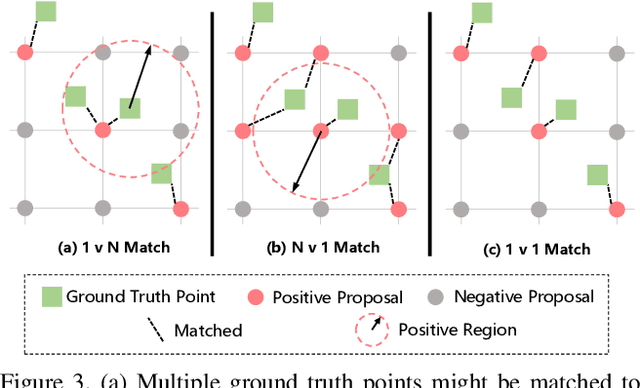
Localizing individuals in crowds is more in accordance with the practical demands of subsequent high-level crowd analysis tasks than simply counting. However, existing localization based methods relying on intermediate representations (\textit{i.e.}, density maps or pseudo boxes) serving as learning targets are counter-intuitive and error-prone. In this paper, we propose a purely point-based framework for joint crowd counting and individual localization. For this framework, instead of merely reporting the absolute counting error at image level, we propose a new metric, called density Normalized Average Precision (nAP), to provide more comprehensive and more precise performance evaluation. Moreover, we design an intuitive solution under this framework, which is called Point to Point Network (P2PNet). P2PNet discards superfluous steps and directly predicts a set of point proposals to represent heads in an image, being consistent with the human annotation results. By thorough analysis, we reveal the key step towards implementing such a novel idea is to assign optimal learning targets for these proposals. Therefore, we propose to conduct this crucial association in an one-to-one matching manner using the Hungarian algorithm. The P2PNet not only significantly surpasses state-of-the-art methods on popular counting benchmarks, but also achieves promising localization accuracy. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-P2PNet.
Uniformity in Heterogeneity:Diving Deep into Count Interval Partition for Crowd Counting
Aug 07, 2021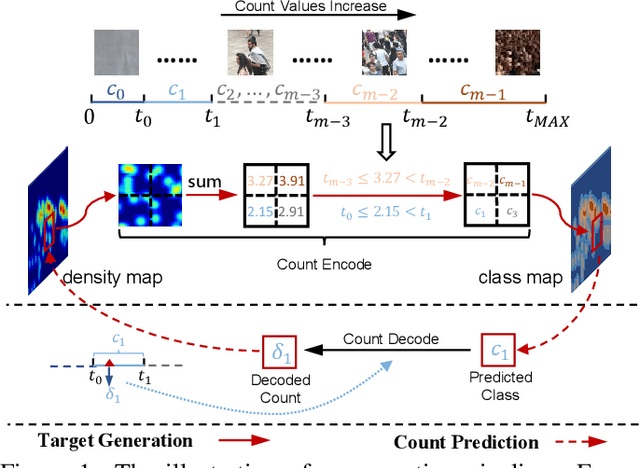
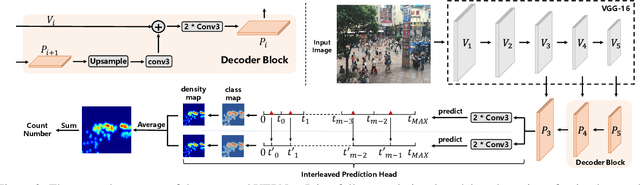
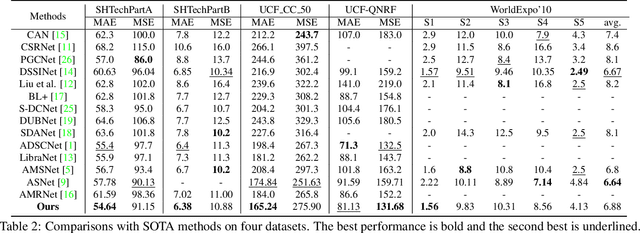
Recently, the problem of inaccurate learning targets in crowd counting draws increasing attention. Inspired by a few pioneering work, we solve this problem by trying to predict the indices of pre-defined interval bins of counts instead of the count values themselves. However, an inappropriate interval setting might make the count error contributions from different intervals extremely imbalanced, leading to inferior counting performance. Therefore, we propose a novel count interval partition criterion called Uniform Error Partition (UEP), which always keeps the expected counting error contributions equal for all intervals to minimize the prediction risk. Then to mitigate the inevitably introduced discretization errors in the count quantization process, we propose another criterion called Mean Count Proxies (MCP). The MCP criterion selects the best count proxy for each interval to represent its count value during inference, making the overall expected discretization error of an image nearly negligible. As far as we are aware, this work is the first to delve into such a classification task and ends up with a promising solution for count interval partition. Following the above two theoretically demonstrated criterions, we propose a simple yet effective model termed Uniform Error Partition Network (UEPNet), which achieves state-of-the-art performance on several challenging datasets. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-UEPNet.
Dual Reweighting Domain Generalization for Face Presentation Attack Detection
Jun 30, 2021
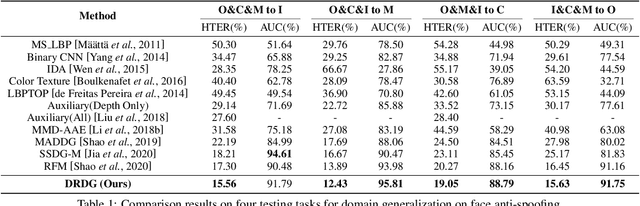
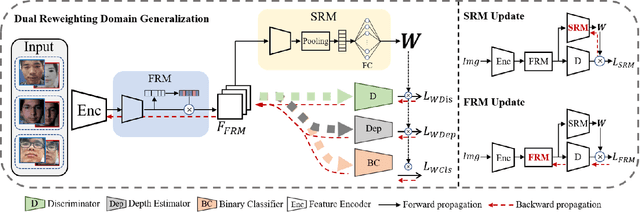
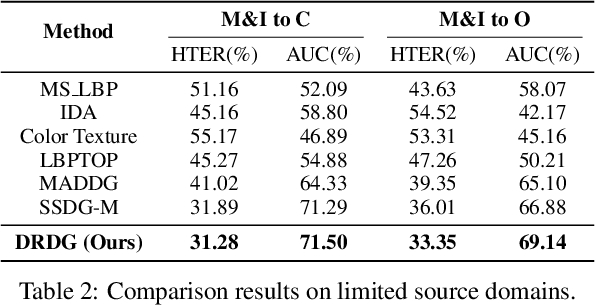
Face anti-spoofing approaches based on domain generalization (DG) have drawn growing attention due to their robustness for unseen scenarios. Previous methods treat each sample from multiple domains indiscriminately during the training process, and endeavor to extract a common feature space to improve the generalization. However, due to complex and biased data distribution, directly treating them equally will corrupt the generalization ability. To settle the issue, we propose a novel Dual Reweighting Domain Generalization (DRDG) framework which iteratively reweights the relative importance between samples to further improve the generalization. Concretely, Sample Reweighting Module is first proposed to identify samples with relatively large domain bias, and reduce their impact on the overall optimization. Afterwards, Feature Reweighting Module is introduced to focus on these samples and extract more domain-irrelevant features via a self-distilling mechanism. Combined with the domain discriminator, the iteration of the two modules promotes the extraction of generalized features. Extensive experiments and visualizations are presented to demonstrate the effectiveness and interpretability of our method against the state-of-the-art competitors.
HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping
Jun 18, 2021
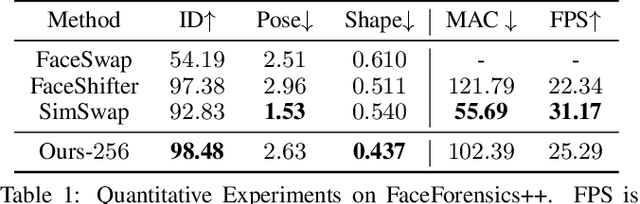
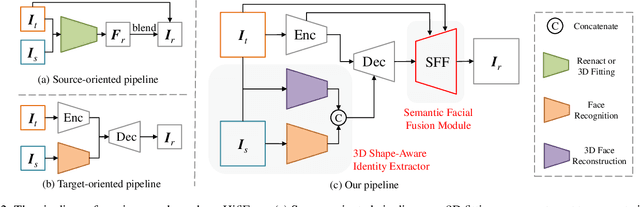
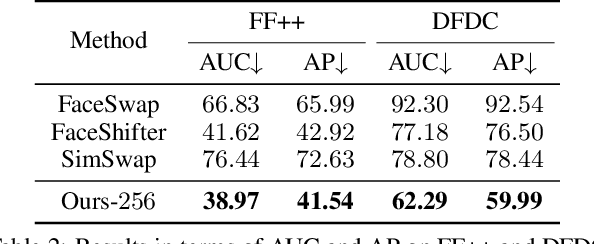
In this work, we propose a high fidelity face swapping method, called HifiFace, which can well preserve the face shape of the source face and generate photo-realistic results. Unlike other existing face swapping works that only use face recognition model to keep the identity similarity, we propose 3D shape-aware identity to control the face shape with the geometric supervision from 3DMM and 3D face reconstruction method. Meanwhile, we introduce the Semantic Facial Fusion module to optimize the combination of encoder and decoder features and make adaptive blending, which makes the results more photo-realistic. Extensive experiments on faces in the wild demonstrate that our method can preserve better identity, especially on the face shape, and can generate more photo-realistic results than previous state-of-the-art methods.
Learning to Aggregate and Personalize 3D Face from In-the-Wild Photo Collection
Jun 15, 2021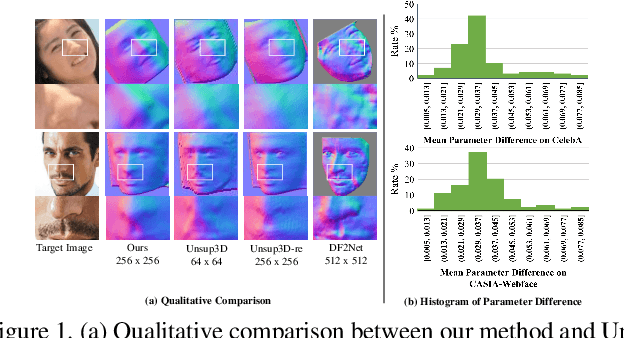
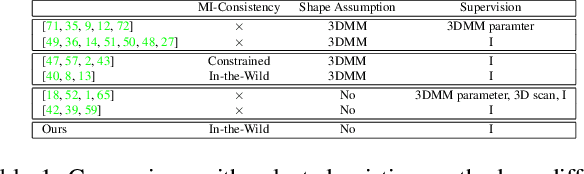
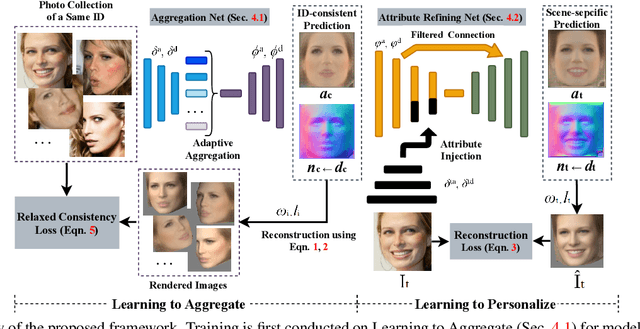
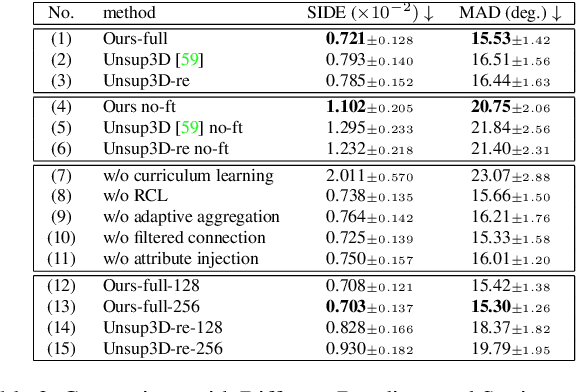
Non-parametric face modeling aims to reconstruct 3D face only from images without shape assumptions. While plausible facial details are predicted, the models tend to over-depend on local color appearance and suffer from ambiguous noise. To address such problem, this paper presents a novel Learning to Aggregate and Personalize (LAP) framework for unsupervised robust 3D face modeling. Instead of using controlled environment, the proposed method implicitly disentangles ID-consistent and scene-specific face from unconstrained photo set. Specifically, to learn ID-consistent face, LAP adaptively aggregates intrinsic face factors of an identity based on a novel curriculum learning approach with relaxed consistency loss. To adapt the face for a personalized scene, we propose a novel attribute-refining network to modify ID-consistent face with target attribute and details. Based on the proposed method, we make unsupervised 3D face modeling benefit from meaningful image facial structure and possibly higher resolutions. Extensive experiments on benchmarks show LAP recovers superior or competitive face shape and texture, compared with state-of-the-art (SOTA) methods with or without prior and supervision.
Context-Aware Image Inpainting with Learned Semantic Priors
Jun 14, 2021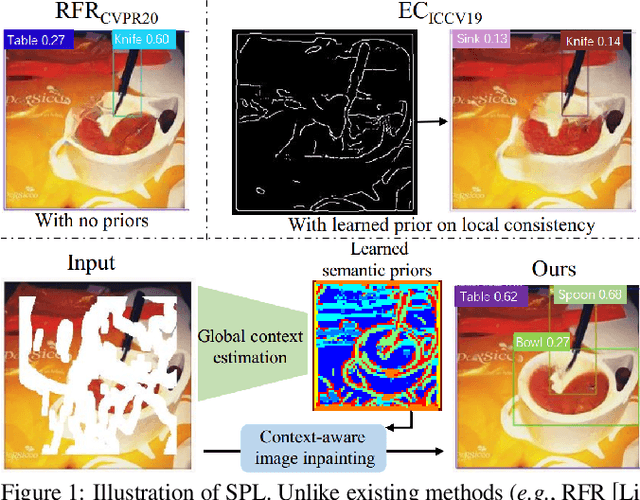
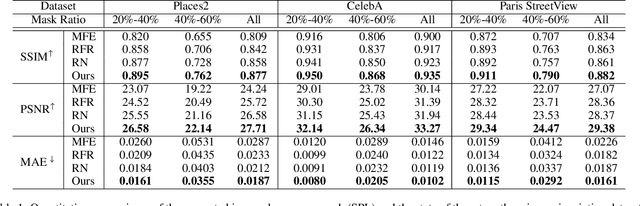
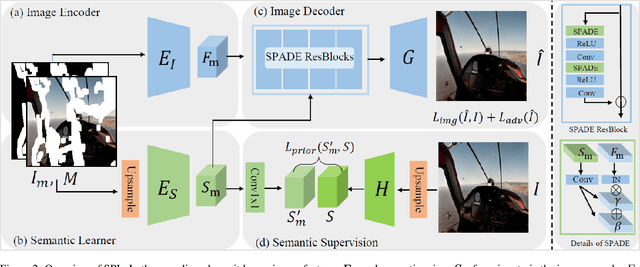

Recent advances in image inpainting have shown impressive results for generating plausible visual details on rather simple backgrounds. However, for complex scenes, it is still challenging to restore reasonable contents as the contextual information within the missing regions tends to be ambiguous. To tackle this problem, we introduce pretext tasks that are semantically meaningful to estimating the missing contents. In particular, we perform knowledge distillation on pretext models and adapt the features to image inpainting. The learned semantic priors ought to be partially invariant between the high-level pretext task and low-level image inpainting, which not only help to understand the global context but also provide structural guidance for the restoration of local textures. Based on the semantic priors, we further propose a context-aware image inpainting model, which adaptively integrates global semantics and local features in a unified image generator. The semantic learner and the image generator are trained in an end-to-end manner. We name the model SPL to highlight its ability to learn and leverage semantic priors. It achieves the state of the art on Places2, CelebA, and Paris StreetView datasets.
SiamRCR: Reciprocal Classification and Regression for Visual Object Tracking
Jun 04, 2021


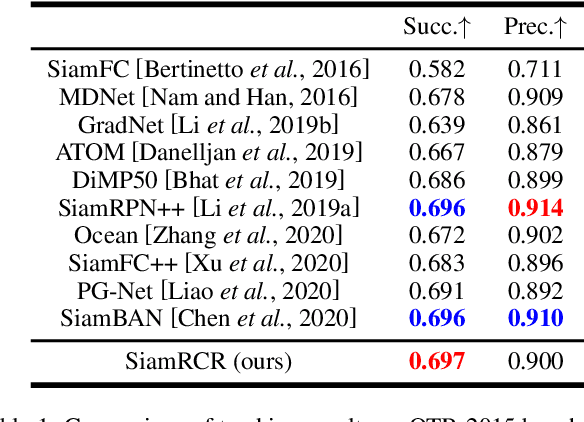
Recently, most siamese network based trackers locate targets via object classification and bounding-box regression. Generally, they select the bounding-box with maximum classification confidence as the final prediction. This strategy may miss the right result due to the accuracy misalignment between classification and regression. In this paper, we propose a novel siamese tracking algorithm called SiamRCR, addressing this problem with a simple, light and effective solution. It builds reciprocal links between classification and regression branches, which can dynamically re-weight their losses for each positive sample. In addition, we add a localization branch to predict the localization accuracy, so that it can work as the replacement of the regression assistance link during inference. This branch makes the training and inference more consistent. Extensive experimental results demonstrate the effectiveness of SiamRCR and its superiority over the state-of-the-art competitors on GOT-10k, LaSOT, TrackingNet, OTB-2015, VOT-2018 and VOT-2019. Moreover, our SiamRCR runs at 65 FPS, far above the real-time requirement.