 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYiming Wang
Meta-Reasoning: Semantics-Symbol Deconstruction For Large Language Models
Jun 30, 2023
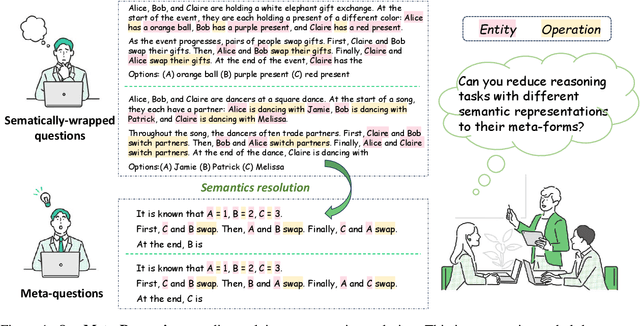

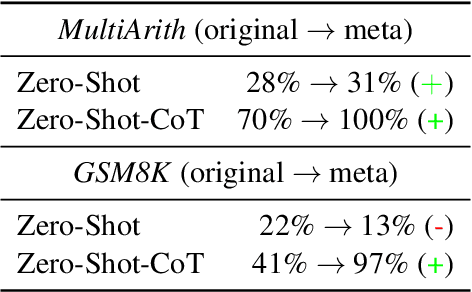
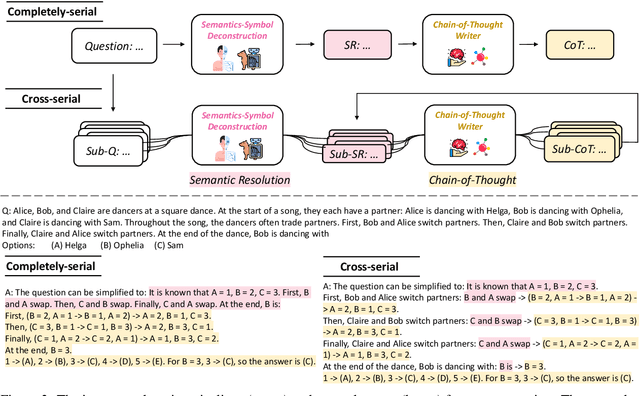
Symbolization methods in large language models (LLMs) have been shown effective to improve LLMs' reasoning ability. However, most of these approaches hinge on mapping natural languages to formal languages (e.g., Python, SQL) that are more syntactically complete and free of ambiguity. Although effective, they depart from the natural language itself and deviate from the habits of human thinking, and instead cater more to the execution mindset of computers. In contrast, we hope to simplify natural language by starting from the concept of symbols in linguistics itself, so that LLMs can learn the common formulation and general solution of reasoning problems wrapped in different natural semantics. From this consideration, we propose \textbf{Meta-Reasoning}, which allows LLMs to automatically accomplish semantic-symbol deconstruction, i.e., semantic resolution, to maximally reduce different questions of certain reasoning tasks to similar natural language representation, thus gaining the ability to learn by analogy and facilitating data-efficient in-context learning. Our experiments show that the Meta-Reasoning paradigm saliently enhances LLMs' reasoning performance with fewer demonstrations. They can learn not only reasoning chains but also general solutions to certain types of tasks. In particular, for symbolic reasoning tasks, such as 7-step Tracking Shuffled Objects, GPT-3 (text-davinci-002) achieves over 99% accuracy with only one Meta-Reasoning demonstration, outperforming all current LLMs with the standard chain-of-thought prompting.
Self-Enhancement Improves Text-Image Retrieval in Foundation Visual-Language Models
Jun 11, 2023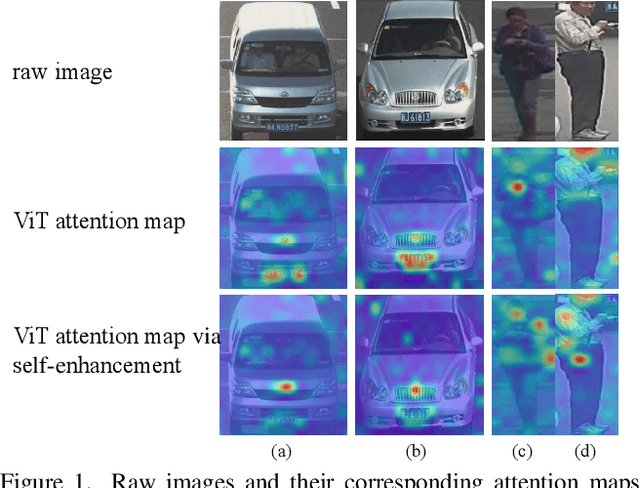
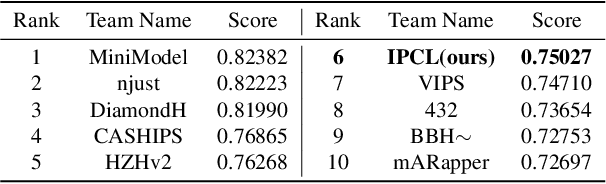
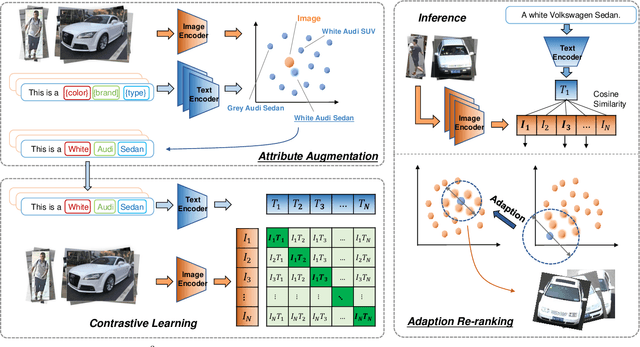

The emergence of cross-modal foundation models has introduced numerous approaches grounded in text-image retrieval. However, on some domain-specific retrieval tasks, these models fail to focus on the key attributes required. To address this issue, we propose a self-enhancement framework, A^{3}R, based on the CLIP-ViT/G-14, one of the largest cross-modal models. First, we perform an Attribute Augmentation strategy to enrich the textual description for fine-grained representation before model learning. Then, we propose an Adaption Re-ranking method to unify the representation space of textual query and candidate images and re-rank candidate images relying on the adapted query after model learning. The proposed framework is validated to achieve a salient improvement over the baseline and other teams' solutions in the cross-modal image retrieval track of the 1st foundation model challenge without introducing any additional samples. The code is available at \url{https://github.com/CapricornGuang/A3R}.
Vocabulary-free Image Classification
Jun 01, 2023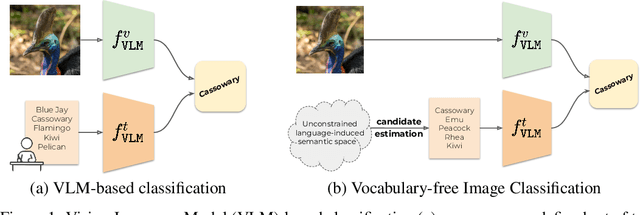
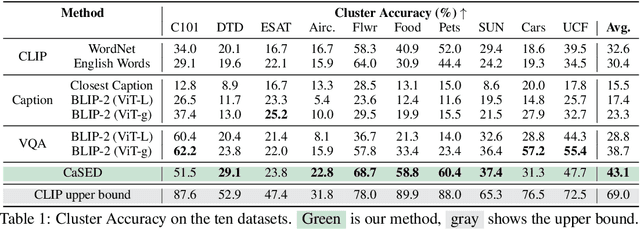
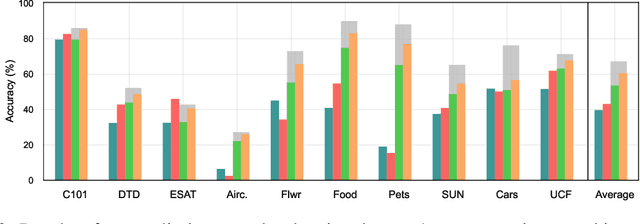
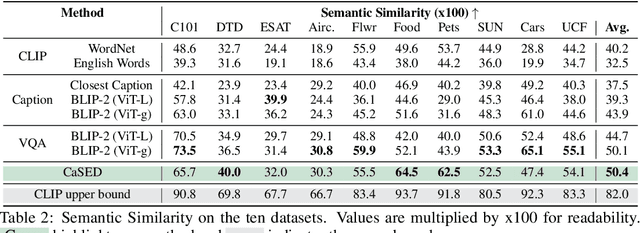
Recent advances in large vision-language models have revolutionized the image classification paradigm. Despite showing impressive zero-shot capabilities, a pre-defined set of categories, a.k.a. the vocabulary, is assumed at test time for composing the textual prompts. However, such assumption can be impractical when the semantic context is unknown and evolving. We thus formalize a novel task, termed as Vocabulary-free Image Classification (VIC), where we aim to assign to an input image a class that resides in an unconstrained language-induced semantic space, without the prerequisite of a known vocabulary. VIC is a challenging task as the semantic space is extremely large, containing millions of concepts, with hard-to-discriminate fine-grained categories. In this work, we first empirically verify that representing this semantic space by means of an external vision-language database is the most effective way to obtain semantically relevant content for classifying the image. We then propose Category Search from External Databases (CaSED), a method that exploits a pre-trained vision-language model and an external vision-language database to address VIC in a training-free manner. CaSED first extracts a set of candidate categories from captions retrieved from the database based on their semantic similarity to the image, and then assigns to the image the best matching candidate category according to the same vision-language model. Experiments on benchmark datasets validate that CaSED outperforms other complex vision-language frameworks, while being efficient with much fewer parameters, paving the way for future research in this direction.
Audio-Visual Dataset and Method for Anomaly Detection in Traffic Videos
May 24, 2023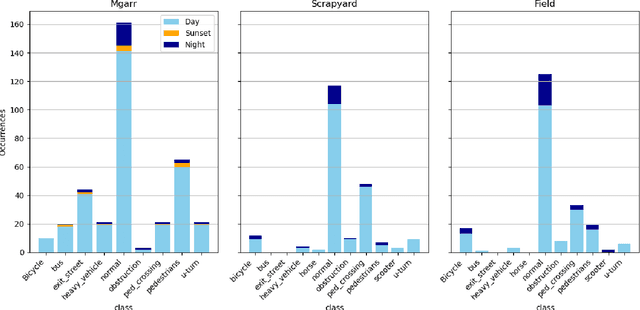
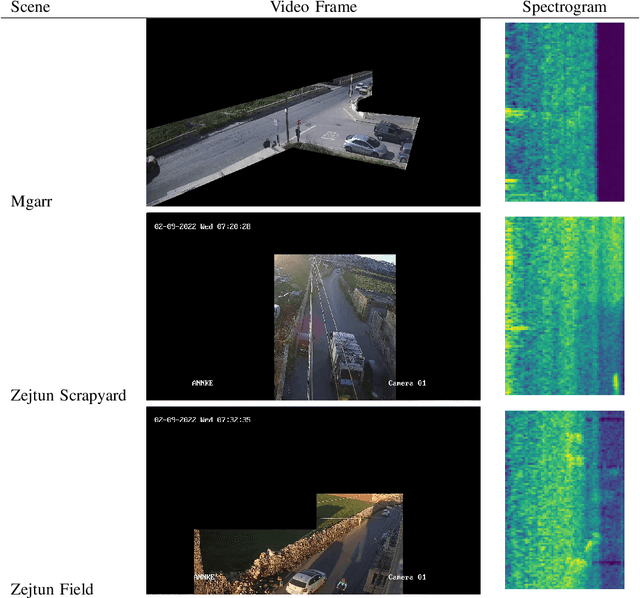

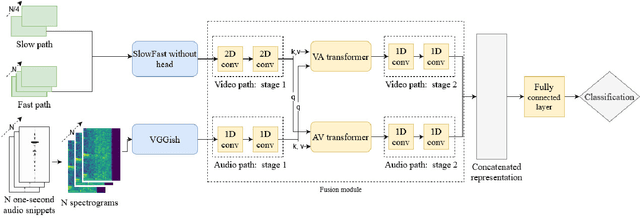
We introduce the first audio-visual dataset for traffic anomaly detection taken from real-world scenes, called MAVAD, with a diverse range of weather and illumination conditions. In addition, we propose a novel method named AVACA that combines visual and audio features extracted from video sequences by means of cross-attention to detect anomalies. We demonstrate that the addition of audio improves the performance of AVACA by up to 5.2%. We also evaluate the impact of image anonymization, showing only a minor decrease in performance averaging at 1.7%.
Element-aware Summarization with Large Language Models: Expert-aligned Evaluation and Chain-of-Thought Method
May 22, 2023
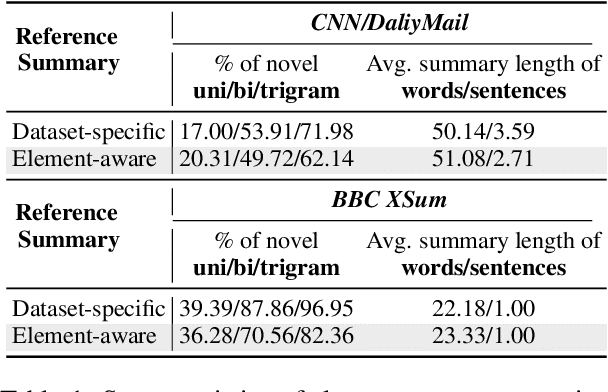

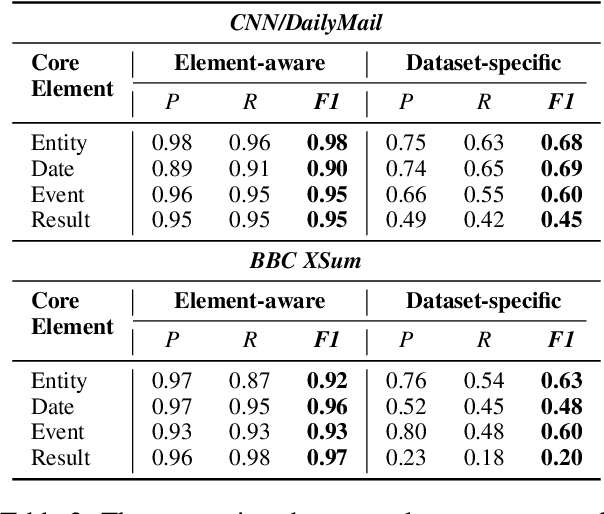
Automatic summarization generates concise summaries that contain key ideas of source documents. As the most mainstream datasets for the news sub-domain, CNN/DailyMail and BBC XSum have been widely used for performance benchmarking. However, the reference summaries of those datasets turn out to be noisy, mainly in terms of factual hallucination and information redundancy. To address this challenge, we first annotate new expert-writing Element-aware test sets following the "Lasswell Communication Model" proposed by Lasswell (1948), allowing reference summaries to focus on more fine-grained news elements objectively and comprehensively. Utilizing the new test sets, we observe the surprising zero-shot summary ability of LLMs, which addresses the issue of the inconsistent results between human preference and automatic evaluation metrics of LLMs' zero-shot summaries in prior work. Further, we propose a Summary Chain-of-Thought (SumCoT) technique to elicit LLMs to generate summaries step by step, which helps them integrate more fine-grained details of source documents into the final summaries that correlate with the human writing mindset. Experimental results show our method outperforms state-of-the-art fine-tuned PLMs and zero-shot LLMs by +4.33/+4.77 in ROUGE-L on the two datasets, respectively. Dataset and code are publicly available at https://github.com/Alsace08/SumCoT.
Positional Diffusion: Ordering Unordered Sets with Diffusion Probabilistic Models
Mar 20, 2023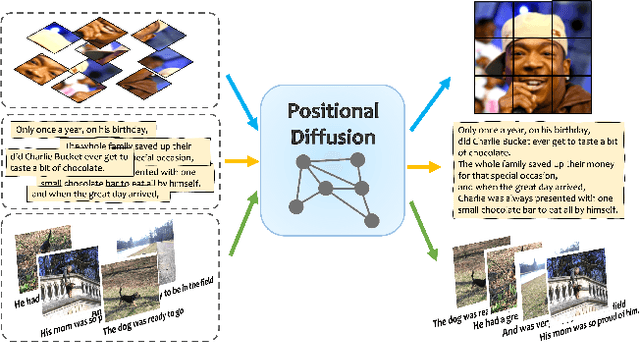


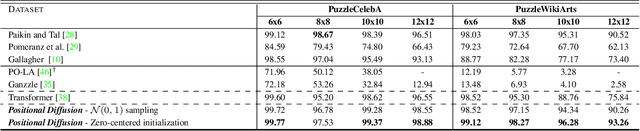
Positional reasoning is the process of ordering unsorted parts contained in a set into a consistent structure. We present Positional Diffusion, a plug-and-play graph formulation with Diffusion Probabilistic Models to address positional reasoning. We use the forward process to map elements' positions in a set to random positions in a continuous space. Positional Diffusion learns to reverse the noising process and recover the original positions through an Attention-based Graph Neural Network. We conduct extensive experiments with benchmark datasets including two puzzle datasets, three sentence ordering datasets, and one visual storytelling dataset, demonstrating that our method outperforms long-lasting research on puzzle solving with up to +18% compared to the second-best deep learning method, and performs on par against the state-of-the-art methods on sentence ordering and visual storytelling. Our work highlights the suitability of diffusion models for ordering problems and proposes a novel formulation and method for solving various ordering tasks. Project website at https://iit-pavis.github.io/Positional_Diffusion/
Unsupervised Active Visual Search with Monte Carlo planning under Uncertain Detections
Mar 06, 2023

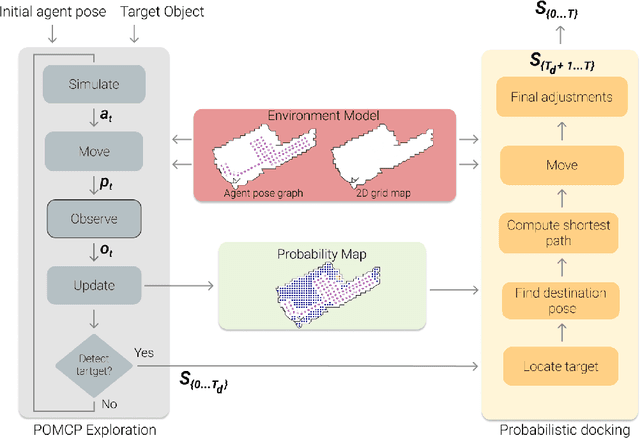
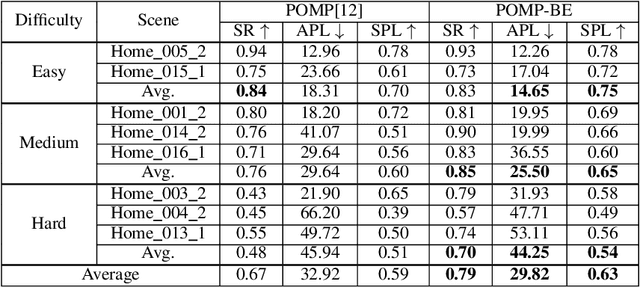
We propose a solution for Active Visual Search of objects in an environment, whose 2D floor map is the only known information. Our solution has three key features that make it more plausible and robust to detector failures compared to state-of-the-art methods: (i) it is unsupervised as it does not need any training sessions. (ii) During the exploration, a probability distribution on the 2D floor map is updated according to an intuitive mechanism, while an improved belief update increases the effectiveness of the agent's exploration. (iii) We incorporate the awareness that an object detector may fail into the aforementioned probability modelling by exploiting the success statistics of a specific detector. Our solution is dubbed POMP-BE-PD (Pomcp-based Online Motion Planning with Belief by Exploration and Probabilistic Detection). It uses the current pose of an agent and an RGB-D observation to learn an optimal search policy, exploiting a POMDP solved by a Monte-Carlo planning approach. On the Active Vision Database benchmark, we increase the average success rate over all the environments by a significant 35% while decreasing the average path length by 4% with respect to competing methods. Thus, our results are state-of-the-art, even without using any training procedure.
3DSGrasp: 3D Shape-Completion for Robotic Grasp
Jan 02, 2023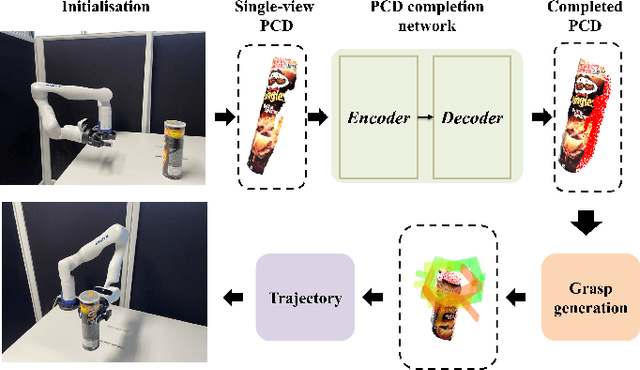
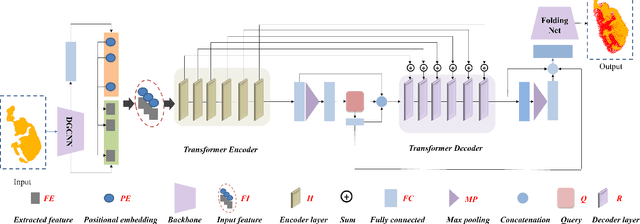
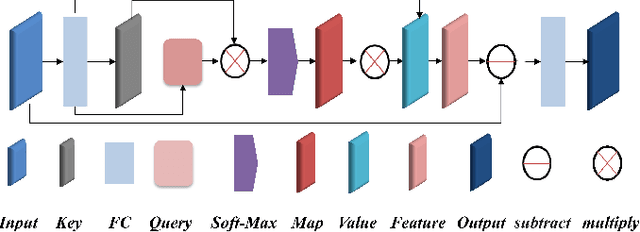
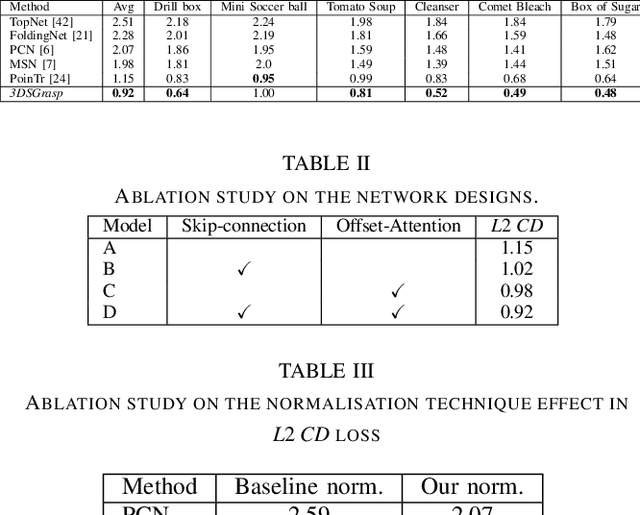
Real-world robotic grasping can be done robustly if a complete 3D Point Cloud Data (PCD) of an object is available. However, in practice, PCDs are often incomplete when objects are viewed from few and sparse viewpoints before the grasping action, leading to the generation of wrong or inaccurate grasp poses. We propose a novel grasping strategy, named 3DSGrasp, that predicts the missing geometry from the partial PCD to produce reliable grasp poses. Our proposed PCD completion network is a Transformer-based encoder-decoder network with an Offset-Attention layer. Our network is inherently invariant to the object pose and point's permutation, which generates PCDs that are geometrically consistent and completed properly. Experiments on a wide range of partial PCD show that 3DSGrasp outperforms the best state-of-the-art method on PCD completion tasks and largely improves the grasping success rate in real-world scenarios. The code and dataset will be made available upon acceptance.
Learning with linear mixed model for group recommendation systems
Dec 17, 2022
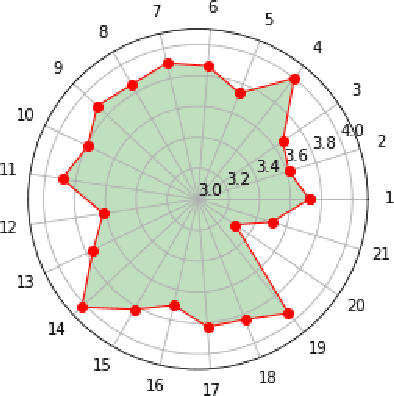
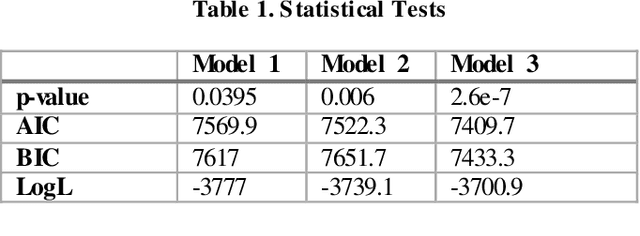
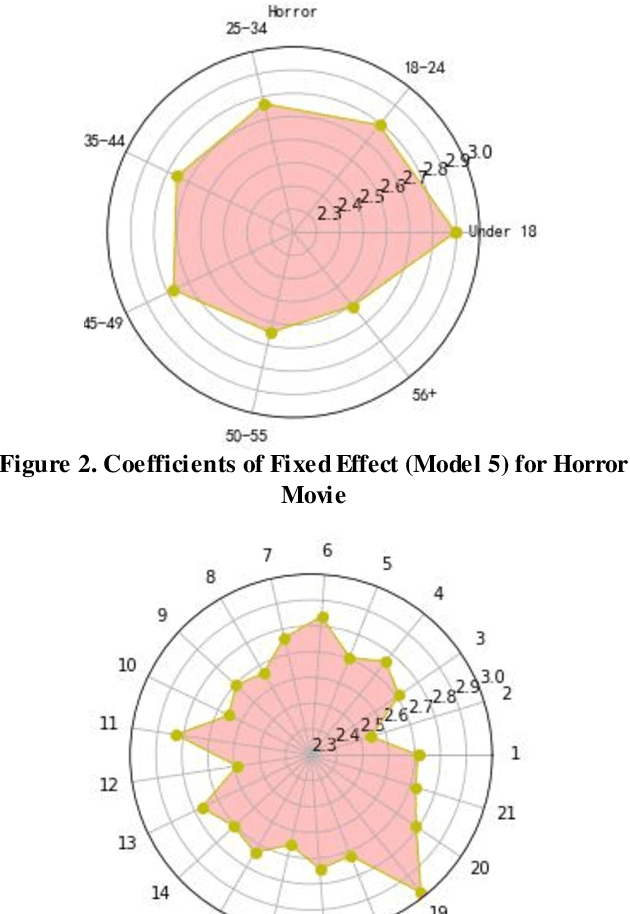
Accurate prediction of users' responses to items is one of the main aims of many computational advising applications. Examples include recommending movies, news articles, songs, jobs, clothes, books and so forth. Accurate prediction of inactive users' responses still remains a challenging problem for many applications. In this paper, we explore the linear mixed model in recommendation system. The recommendation process is naturally modelled as the mixed process between objective effects (fixed effects) and subjective effects (random effects). The latent association between the subjective effects and the users' responses can be mined through the restricted maximum likelihood method. It turns out the linear mixed models can collaborate items' attributes and users' characteristics naturally and effectively. While this model cannot produce the most precisely individual level personalized recommendation, it is relative fast and accurate for group (users)/class (items) recommendation. Numerical examples on GroupLens benchmark problems are presented to show the effectiveness of this method.
* 5 pages, 9 figures, published
NeuS2: Fast Learning of Neural Implicit Surfaces for Multi-view Reconstruction
Dec 10, 2022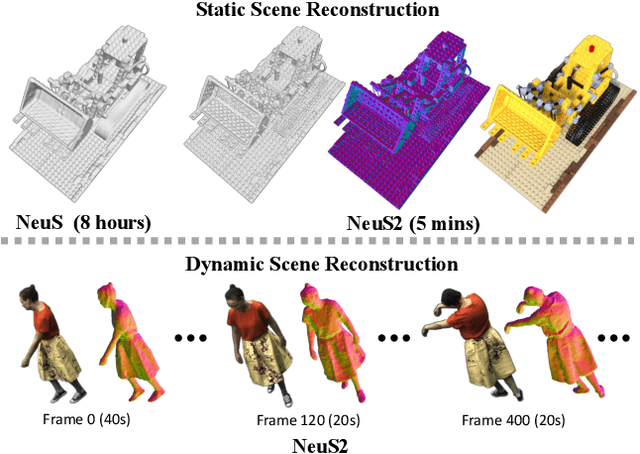
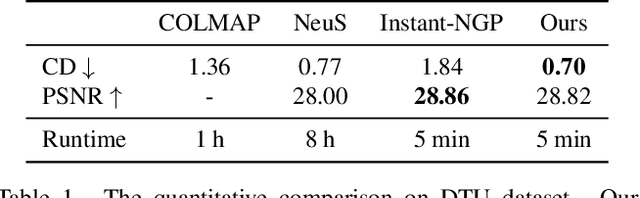
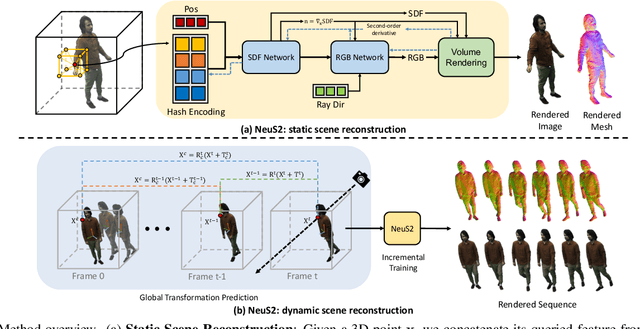
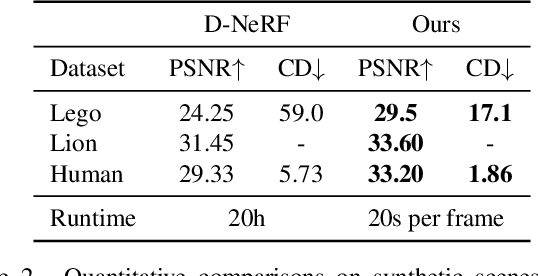
Recent methods for neural surface representation and rendering, for example NeuS, have demonstrated remarkably high-quality reconstruction of static scenes. However, the training of NeuS takes an extremely long time (8 hours), which makes it almost impossible to apply them to dynamic scenes with thousands of frames. We propose a fast neural surface reconstruction approach, called NeuS2, which achieves two orders of magnitude improvement in terms of acceleration without compromising reconstruction quality. To accelerate the training process, we integrate multi-resolution hash encodings into a neural surface representation and implement our whole algorithm in CUDA. We also present a lightweight calculation of second-order derivatives tailored to our networks (i.e., ReLU-based MLPs), which achieves a factor two speed up. To further stabilize training, a progressive learning strategy is proposed to optimize multi-resolution hash encodings from coarse to fine. In addition, we extend our method for reconstructing dynamic scenes with an incremental training strategy. Our experiments on various datasets demonstrate that NeuS2 significantly outperforms the state-of-the-arts in both surface reconstruction accuracy and training speed. The video is available at https://vcai.mpi-inf.mpg.de/projects/NeuS2/ .