 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSTA: Cognitive-State-Conditioned TTS Data Augmentation Using ASR Transcripts for Alzheimer's Disease Detection
Jun 04, 2026Speech-based Alzheimer's Disease (AD) detection is constrained by scarce pathological speech data. To address this, we propose CoSTA, a Text-to-Speech (TTS)-based data augmentation framework. Specifically, we first develop two Cognitive-State-Conditioned (CS-Cond) TTS models by adapting CosyVoice2 and F5-TTS to synthesize speech with distinct AD and Healthy Control characteristics. Furthermore, by constructing a transcript pool comprising Manual Transcripts (MT) and 36 Automatic Speech Recognition (ASR) transcripts, we investigate the impact of text sources on TTS-based augmentation. We also perform augmentation-factor analysis and test-time augmentation. Experiments on the ADReSS dataset show that CS-Cond TTS significantly improves synthetic speech utility, and ASR-driven augmentation frequently outperforms MT-driven augmentation. Finally, CoSTA yields a 4.16% gain over the baseline, achieving an audio-only accuracy of 85.83% on the ADReSS test set and outperforming prior methods.
EGGCodec: A Robust Neural Encodec Framework for EGG Reconstruction and F0 Extraction
Aug 12, 2025This letter introduces EGGCodec, a robust neural Encodec framework engineered for electroglottography (EGG) signal reconstruction and F0 extraction. We propose a multi-scale frequency-domain loss function to capture the nuanced relationship between original and reconstructed EGG signals, complemented by a time-domain correlation loss to improve generalization and accuracy. Unlike conventional Encodec models that extract F0 directly from features, EGGCodec leverages reconstructed EGG signals, which more closely correspond to F0. By removing the conventional GAN discriminator, we streamline EGGCodec's training process without compromising efficiency, incurring only negligible performance degradation. Trained on a widely used EGG-inclusive dataset, extensive evaluations demonstrate that EGGCodec outperforms state-of-the-art F0 extraction schemes, reducing mean absolute error (MAE) from 14.14 Hz to 13.69 Hz, and improving voicing decision error (VDE) by 38.2\%. Moreover, extensive ablation experiments validate the contribution of each component of EGGCodec.
Exploring Gender Bias in Alzheimer's Disease Detection: Insights from Mandarin and Greek Speech Perception
Jul 16, 2025



Gender bias has been widely observed in speech perception tasks, influenced by the fundamental voicing differences between genders. This study reveals a gender bias in the perception of Alzheimer's Disease (AD) speech. In a perception experiment involving 16 Chinese listeners evaluating both Chinese and Greek speech, we identified that male speech was more frequently identified as AD, with this bias being particularly pronounced in Chinese speech. Acoustic analysis showed that shimmer values in male speech were significantly associated with AD perception, while speech portion exhibited a significant negative correlation with AD identification. Although language did not have a significant impact on AD perception, our findings underscore the critical role of gender bias in AD speech perception. This work highlights the necessity of addressing gender bias when developing AD detection models and calls for further research to validate model performance across different linguistic contexts.
Decoding Speaker-Normalized Pitch from EEG for Mandarin Perception
May 26, 2025The same speech content produced by different speakers exhibits significant differences in pitch contour, yet listeners' semantic perception remains unaffected. This phenomenon may stem from the brain's perception of pitch contours being independent of individual speakers' pitch ranges. In this work, we recorded electroencephalogram (EEG) while participants listened to Mandarin monosyllables with varying tones, phonemes, and speakers. The CE-ViViT model is proposed to decode raw or speaker-normalized pitch contours directly from EEG. Experimental results demonstrate that the proposed model can decode pitch contours with modest errors, achieving performance comparable to state-of-the-art EEG regression methods. Moreover, speaker-normalized pitch contours were decoded more accurately, supporting the neural encoding of relative pitch.
Automated Tone Transcription and Clustering with Tone2Vec
Oct 03, 2024



Lexical tones play a crucial role in Sino-Tibetan languages. However, current phonetic fieldwork relies on manual effort, resulting in substantial time and financial costs. This is especially challenging for the numerous endangered languages that are rapidly disappearing, often compounded by limited funding. In this paper, we introduce pitch-based similarity representations for tone transcription, named Tone2Vec. Experiments on dialect clustering and variance show that Tone2Vec effectively captures fine-grained tone variation. Utilizing Tone2Vec, we develop the first automatic approach for tone transcription and clustering by presenting a novel representation transformation for transcriptions. Additionally, these algorithms are systematically integrated into an open-sourced and easy-to-use package, ToneLab, which facilitates automated fieldwork and cross-regional, cross-lexical analysis for tonal languages. Extensive experiments were conducted to demonstrate the effectiveness of our methods.
Cross-lingual Speech Emotion Recognition: Humans vs. Self-Supervised Models
Sep 25, 2024



Utilizing Self-Supervised Learning (SSL) models for Speech Emotion Recognition (SER) has proven effective, yet limited research has explored cross-lingual scenarios. This study presents a comparative analysis between human performance and SSL models, beginning with a layer-wise analysis and an exploration of parameter-efficient fine-tuning strategies in monolingual, cross-lingual, and transfer learning contexts. We further compare the SER ability of models and humans at both utterance- and segment-levels. Additionally, we investigate the impact of dialect on cross-lingual SER through human evaluation. Our findings reveal that models, with appropriate knowledge transfer, can adapt to the target language and achieve performance comparable to native speakers. We also demonstrate the significant effect of dialect on SER for individuals without prior linguistic and paralinguistic background. Moreover, both humans and models exhibit distinct behaviors across different emotions. These results offer new insights into the cross-lingual SER capabilities of SSL models, underscoring both their similarities to and differences from human emotion perception.
Data-Driven Adaptive Simultaneous Machine Translation
Apr 27, 2022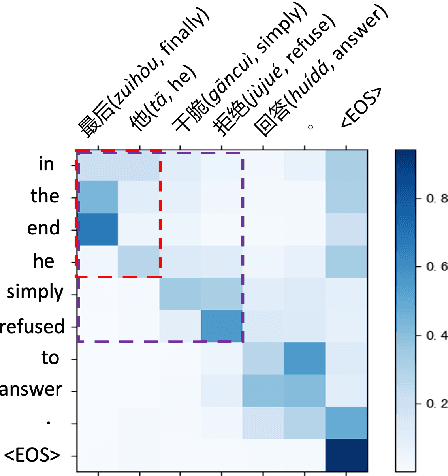
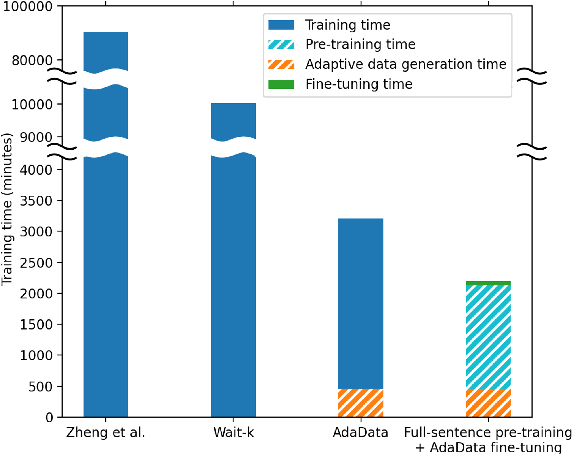
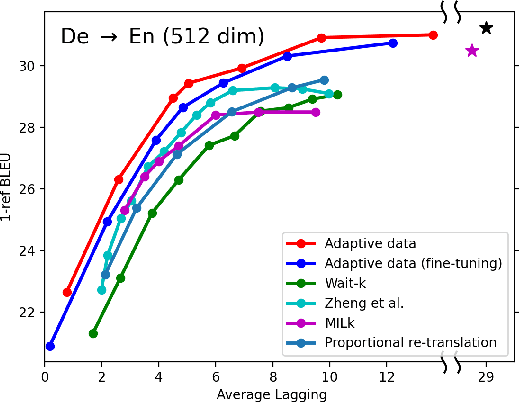
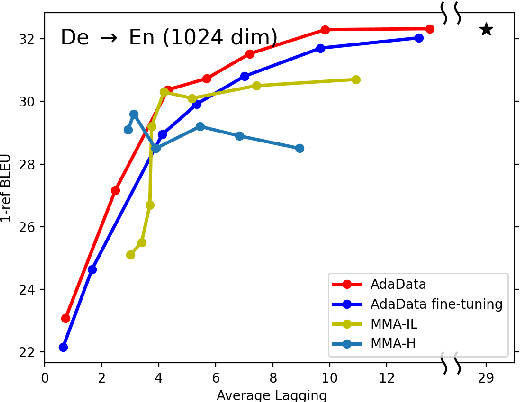
In simultaneous translation (SimulMT), the most widely used strategy is the wait-k policy thanks to its simplicity and effectiveness in balancing translation quality and latency. However, wait-k suffers from two major limitations: (a) it is a fixed policy that can not adaptively adjust latency given context, and (b) its training is much slower than full-sentence translation. To alleviate these issues, we propose a novel and efficient training scheme for adaptive SimulMT by augmenting the training corpus with adaptive prefix-to-prefix pairs, while the training complexity remains the same as that of training full-sentence translation models. Experiments on two language pairs show that our method outperforms all strong baselines in terms of translation quality and latency.
Automatic recognition of suprasegmentals in speech
Aug 04, 2021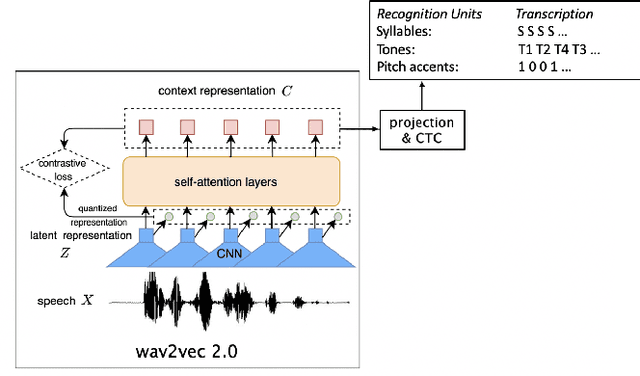
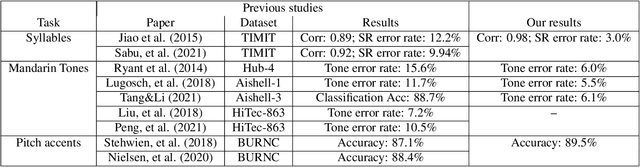
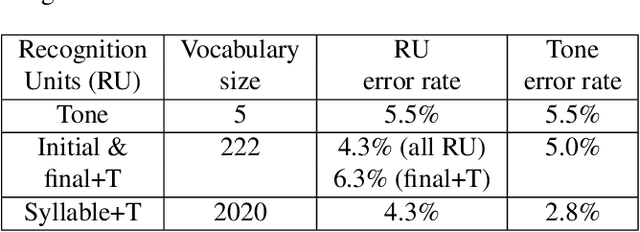
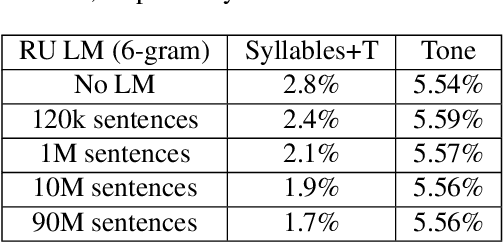
This study reports our efforts to improve automatic recognition of suprasegmentals by fine-tuning wav2vec 2.0 with CTC, a method that has been successful in automatic speech recognition. We demonstrate that the method can improve the state-of-the-art on automatic recognition of syllables, tones, and pitch accents. Utilizing segmental information, by employing tonal finals or tonal syllables as recognition units, can significantly improve Mandarin tone recognition. Language models are helpful when tonal syllables are used as recognition units, but not helpful when tones are recognition units. Finally, Mandarin tone recognition can benefit from English phoneme recognition by combining the two tasks in fine-tuning wav2vec 2.0.
The Role of Phonetic Units in Speech Emotion Recognition
Aug 02, 2021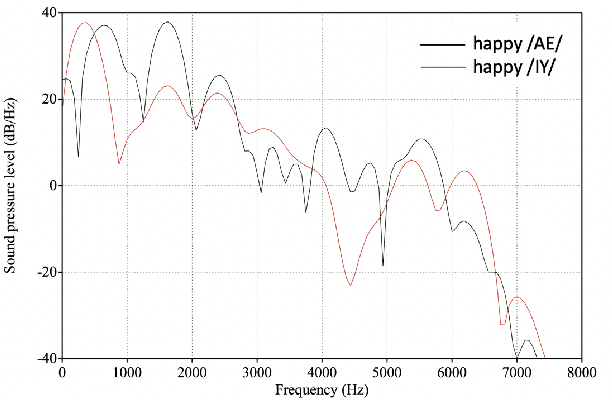
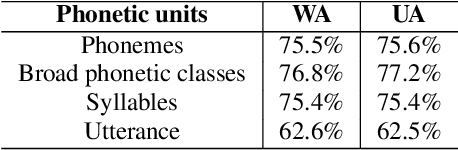
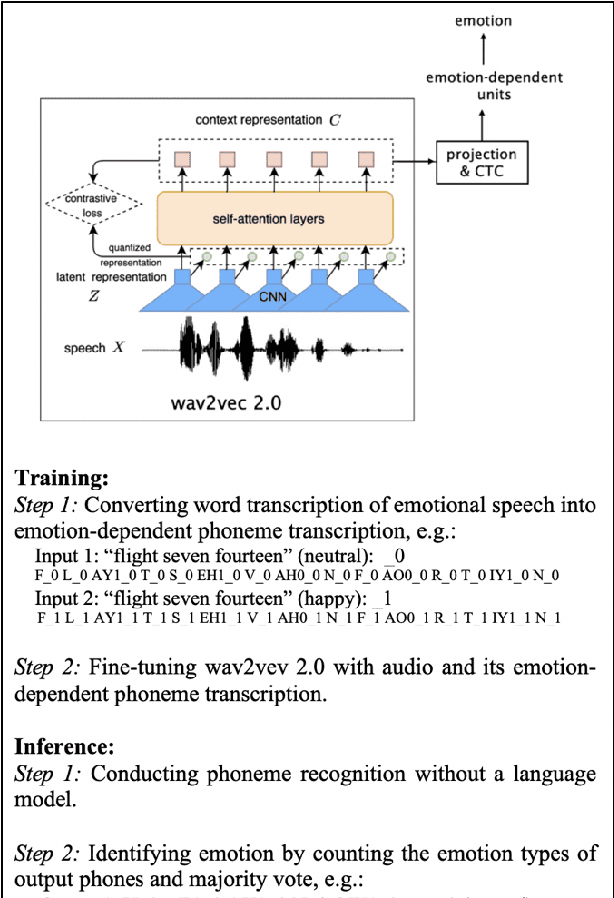
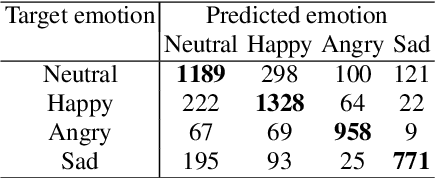
We propose a method for emotion recognition through emotiondependent speech recognition using Wav2vec 2.0. Our method achieved a significant improvement over most previously reported results on IEMOCAP, a benchmark emotion dataset. Different types of phonetic units are employed and compared in terms of accuracy and robustness of emotion recognition within and across datasets and languages. Models of phonemes, broad phonetic classes, and syllables all significantly outperform the utterance model, demonstrating that phonetic units are helpful and should be incorporated in speech emotion recognition. The best performance is from using broad phonetic classes. Further research is needed to investigate the optimal set of broad phonetic classes for the task of emotion recognition. Finally, we found that Wav2vec 2.0 can be fine-tuned to recognize coarser-grained or larger phonetic units than phonemes, such as broad phonetic classes and syllables.
Decoupling recognition and transcription in Mandarin ASR
Aug 02, 2021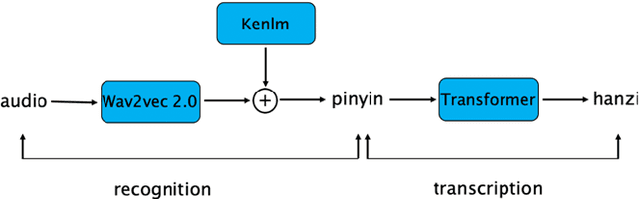
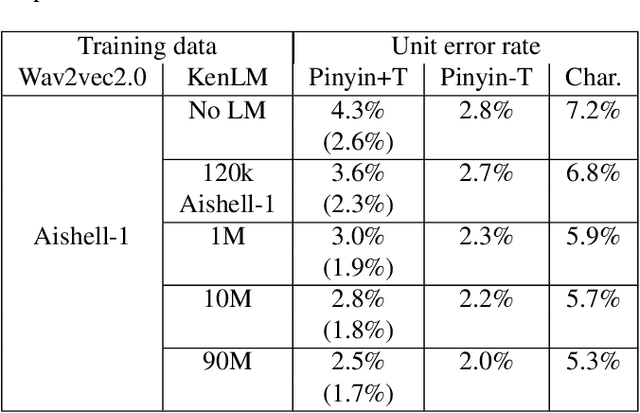
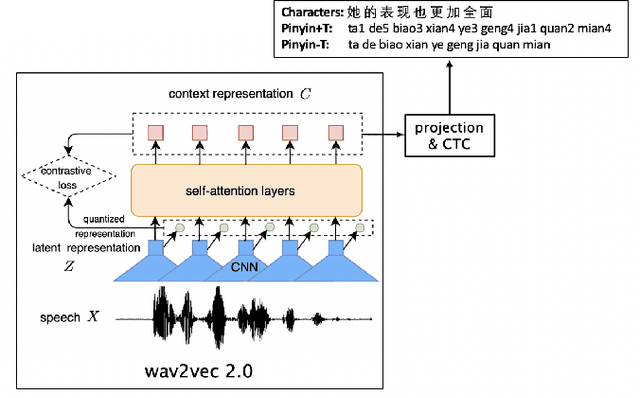
Much of the recent literature on automatic speech recognition (ASR) is taking an end-to-end approach. Unlike English where the writing system is closely related to sound, Chinese characters (Hanzi) represent meaning, not sound. We propose factoring audio -> Hanzi into two sub-tasks: (1) audio -> Pinyin and (2) Pinyin -> Hanzi, where Pinyin is a system of phonetic transcription of standard Chinese. Factoring the audio -> Hanzi task in this way achieves 3.9% CER (character error rate) on the Aishell-1 corpus, the best result reported on this dataset so far.