 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Aligning CodeLLMs on Human Preference
Dec 06, 2024



Code large language models (codeLLMs) have made significant strides in code generation. Most previous code-related benchmarks, which consist of various programming exercises along with the corresponding test cases, are used as a common measure to evaluate the performance and capabilities of code LLMs. However, the current code LLMs focus on synthesizing the correct code snippet, ignoring the alignment with human preferences, where the query should be sampled from the practical application scenarios and the model-generated responses should satisfy the human preference. To bridge the gap between the model-generated response and human preference, we present a rigorous human-curated benchmark CodeArena to emulate the complexity and diversity of real-world coding tasks, where 397 high-quality samples spanning 40 categories and 44 programming languages, carefully curated from user queries. Further, we propose a diverse synthetic instruction corpus SynCode-Instruct (nearly 20B tokens) by scaling instructions from the website to verify the effectiveness of the large-scale synthetic instruction fine-tuning, where Qwen2.5-SynCoder totally trained on synthetic instruction data can achieve top-tier performance of open-source code LLMs. The results find performance differences between execution-based benchmarks and CodeArena. Our systematic experiments of CodeArena on 40+ LLMs reveal a notable performance gap between open SOTA code LLMs (e.g. Qwen2.5-Coder) and proprietary LLMs (e.g., OpenAI o1), underscoring the importance of the human preference alignment.\footnote{\url{https://codearenaeval.github.io/ }}
Language Models can Self-Lengthen to Generate Long Texts
Oct 31, 2024



Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to process long contexts, yet a notable gap remains in generating long, aligned outputs. This limitation stems from a training gap where pre-training lacks effective instructions for long-text generation, and post-training data primarily consists of short query-response pairs. Current approaches, such as instruction backtranslation and behavior imitation, face challenges including data quality, copyright issues, and constraints on proprietary model usage. In this paper, we introduce an innovative iterative training framework called Self-Lengthen that leverages only the intrinsic knowledge and skills of LLMs without the need for auxiliary data or proprietary models. The framework consists of two roles: the Generator and the Extender. The Generator produces the initial response, which is then split and expanded by the Extender. This process results in a new, longer response, which is used to train both the Generator and the Extender iteratively. Through this process, the models are progressively trained to handle increasingly longer responses. Experiments on benchmarks and human evaluations show that Self-Lengthen outperforms existing methods in long-text generation, when applied to top open-source LLMs such as Qwen2 and LLaMA3. Our code is publicly available at https://github.com/QwenLM/Self-Lengthen.
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Oct 10, 2024



Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models. To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation. These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark. Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54% and 52.55% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.
Qwen2 Technical Report
Jul 16, 2024



This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
Can Large Language Models Always Solve Easy Problems if They Can Solve Harder Ones?
Jun 18, 2024



Large language models (LLMs) have demonstrated impressive capabilities, but still suffer from inconsistency issues (e.g. LLMs can react differently to disturbances like rephrasing or inconsequential order change). In addition to these inconsistencies, we also observe that LLMs, while capable of solving hard problems, can paradoxically fail at easier ones. To evaluate this hard-to-easy inconsistency, we develop the ConsisEval benchmark, where each entry comprises a pair of questions with a strict order of difficulty. Furthermore, we introduce the concept of consistency score to quantitatively measure this inconsistency and analyze the potential for improvement in consistency by relative consistency score. Based on comprehensive experiments across a variety of existing models, we find: (1) GPT-4 achieves the highest consistency score of 92.2\% but is still inconsistent to specific questions due to distraction by redundant information, misinterpretation of questions, etc.; (2) models with stronger capabilities typically exhibit higher consistency, but exceptions also exist; (3) hard data enhances consistency for both fine-tuning and in-context learning. Our data and code will be publicly available on GitHub.
Qwen Technical Report
Sep 28, 2023



Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
Transferring General Multimodal Pretrained Models to Text Recognition
Dec 19, 2022This paper proposes a new method, OFA-OCR, to transfer multimodal pretrained models to text recognition. Specifically, we recast text recognition as image captioning and directly transfer a unified vision-language pretrained model to the end task. Without pretraining on large-scale annotated or synthetic text recognition data, OFA-OCR outperforms the baselines and achieves state-of-the-art performance in the Chinese text recognition benchmark. Additionally, we construct an OCR pipeline with OFA-OCR, and we demonstrate that it can achieve competitive performance with the product-level API. The code (https://github.com/OFA-Sys/OFA) and demo (https://modelscope.cn/studios/damo/ofa_ocr_pipeline/summary) are publicly available.
OFASys: A Multi-Modal Multi-Task Learning System for Building Generalist Models
Dec 08, 2022



Generalist models, which are capable of performing diverse multi-modal tasks in a task-agnostic way within a single model, have been explored recently. Being, hopefully, an alternative to approaching general-purpose AI, existing generalist models are still at an early stage, where modality and task coverage is limited. To empower multi-modal task-scaling and speed up this line of research, we release a generalist model learning system, OFASys, built on top of a declarative task interface named multi-modal instruction. At the core of OFASys is the idea of decoupling multi-modal task representations from the underlying model implementations. In OFASys, a task involving multiple modalities can be defined declaratively even with just a single line of code. The system automatically generates task plans from such instructions for training and inference. It also facilitates multi-task training for diverse multi-modal workloads. As a starting point, we provide presets of 7 different modalities and 23 highly-diverse example tasks in OFASys, with which we also develop a first-in-kind, single model, OFA+, that can handle text, image, speech, video, and motion data. The single OFA+ model achieves 95% performance in average with only 16% parameters of 15 task-finetuned models, showcasing the performance reliability of multi-modal task-scaling provided by OFASys. Available at https://github.com/OFA-Sys/OFASys
Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese
Nov 03, 2022



The tremendous success of CLIP (Radford et al., 2021) has promoted the research and application of contrastive learning for vision-language pretraining. In this work, we construct a large-scale dataset of image-text pairs in Chinese, where most data are retrieved from publicly available datasets, and we pretrain Chinese CLIP models on the new dataset. We develop 5 Chinese CLIP models of multiple sizes, spanning from 77 to 958 million parameters. Furthermore, we propose a two-stage pretraining method, where the model is first trained with the image encoder frozen and then trained with all parameters being optimized, to achieve enhanced model performance. Our comprehensive experiments demonstrate that Chinese CLIP can achieve the state-of-the-art performance on MUGE, Flickr30K-CN, and COCO-CN in the setups of zero-shot learning and finetuning, and it is able to achieve competitive performance in zero-shot image classification based on the evaluation on the ELEVATER benchmark (Li et al., 2022). We have released our codes, models, and demos in https://github.com/OFA-Sys/Chinese-CLIP
Sketch and Refine: Towards Faithful and Informative Table-to-Text Generation
May 31, 2021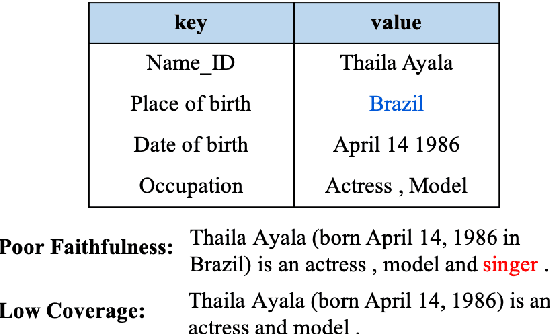
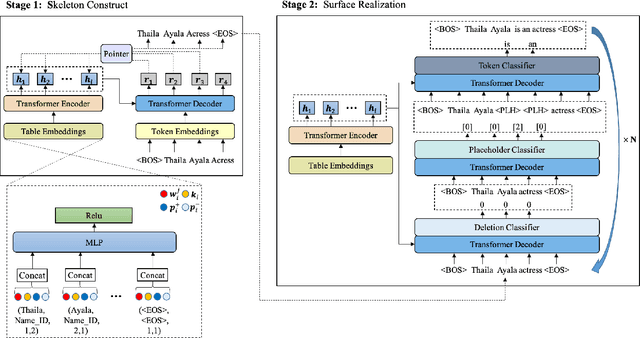
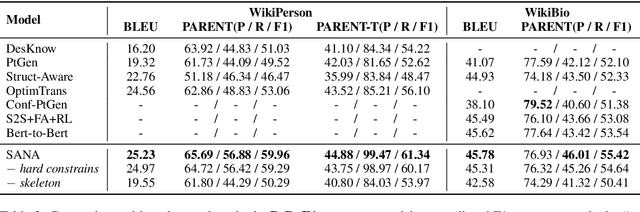
Table-to-text generation refers to generating a descriptive text from a key-value table. Traditional autoregressive methods, though can generate text with high fluency, suffer from low coverage and poor faithfulness problems. To mitigate these problems, we propose a novel Skeleton-based two-stage method that combines both Autoregressive and Non-Autoregressive generations (SANA). Our approach includes: (1) skeleton generation with an autoregressive pointer network to select key tokens from the source table; (2) edit-based non-autoregressive generation model to produce texts via iterative insertion and deletion operations. By integrating hard constraints from the skeleton, the non-autoregressive model improves the generation's coverage over the source table and thus enhances its faithfulness. We conduct automatic and human evaluations on both WikiPerson and WikiBio datasets. Experimental results demonstrate that our method outperforms the previous state-of-the-art methods in both automatic and human evaluation, especially on coverage and faithfulness. In particular, we achieve PARENT-T recall of 99.47 in WikiPerson, improving over the existing best results by more than 10 points.