 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Birds with One Stone: Improving Rumor Detection by Addressing the Unfairness Issue
Dec 30, 2024



The degraded performance and group unfairness caused by confounding sensitive attributes in rumor detection remains relatively unexplored. To address this, we propose a two-step framework. Initially, it identifies confounding sensitive attributes that limit rumor detection performance and cause unfairness across groups. Subsequently, we aim to learn equally informative representations through invariant learning. Our method considers diverse sets of groups without sensitive attribute annotations. Experiments show our method easily integrates with existing rumor detectors, significantly improving both their detection performance and fairness.
Inclusion 2024 Global Multimedia Deepfake Detection: Towards Multi-dimensional Facial Forgery Detection
Dec 30, 2024



In this paper, we present the Global Multimedia Deepfake Detection held concurrently with the Inclusion 2024. Our Multimedia Deepfake Detection aims to detect automatic image and audio-video manipulations including but not limited to editing, synthesis, generation, Photoshop,etc. Our challenge has attracted 1500 teams from all over the world, with about 5000 valid result submission counts. We invite the top 20 teams to present their solutions to the challenge, from which the top 3 teams are awarded prizes in the grand finale. In this paper, we present the solutions from the top 3 teams of the two tracks, to boost the research work in the field of image and audio-video forgery detection. The methodologies developed through the challenge will contribute to the development of next-generation deepfake detection systems and we encourage participants to open source their methods.
Explainable Multi-Modal Data Exploration in Natural Language via LLM Agent
Dec 24, 2024



International enterprises, organizations, or hospitals collect large amounts of multi-modal data stored in databases, text documents, images, and videos. While there has been recent progress in the separate fields of multi-modal data exploration as well as in database systems that automatically translate natural language questions to database query languages, the research challenge of querying database systems combined with other unstructured modalities such as images in natural language is widely unexplored. In this paper, we propose XMODE - a system that enables explainable, multi-modal data exploration in natural language. Our approach is based on the following research contributions: (1) Our system is inspired by a real-world use case that enables users to explore multi-modal information systems. (2) XMODE leverages a LLM-based agentic AI framework to decompose a natural language question into subtasks such as text-to-SQL generation and image analysis. (3) Experimental results on multi-modal datasets over relational data and images demonstrate that our system outperforms state-of-the-art multi-modal exploration systems, excelling not only in accuracy but also in various performance metrics such as query latency, API costs, planning efficiency, and explanation quality, thanks to the more effective utilization of the reasoning capabilities of LLMs.
Correcting Large Language Model Behavior via Influence Function
Dec 21, 2024



Recent advancements in AI alignment techniques have significantly improved the alignment of large language models (LLMs) with static human preferences. However, the dynamic nature of human preferences can render some prior training data outdated or even erroneous, ultimately causing LLMs to deviate from contemporary human preferences and societal norms. Existing methodologies, whether they involve the curation of new data for continual alignment or the manual correction of outdated data for re-alignment, demand costly human resources. To address this challenge, we propose a novel approach, Large Language Model Behavior Correction with Influence Function Recall and Post-Training (LANCET), which requires no human involvement. LANCET consists of two phases: (1) using influence functions to identify the training data that significantly impact undesirable model outputs, and (2) applying an Influence function-driven Bregman Optimization (IBO) technique to adjust the model's behavior based on these influence distributions. Our experiments demonstrate that LANCET effectively and efficiently correct inappropriate behaviors of LLMs. Furthermore, LANCET can outperform methods that rely on collecting human preferences, and it enhances the interpretability of learning human preferences within LLMs.
Cross-Modal Few-Shot Learning with Second-Order Neural Ordinary Differential Equations
Dec 20, 2024



We introduce SONO, a novel method leveraging Second-Order Neural Ordinary Differential Equations (Second-Order NODEs) to enhance cross-modal few-shot learning. By employing a simple yet effective architecture consisting of a Second-Order NODEs model paired with a cross-modal classifier, SONO addresses the significant challenge of overfitting, which is common in few-shot scenarios due to limited training examples. Our second-order approach can approximate a broader class of functions, enhancing the model's expressive power and feature generalization capabilities. We initialize our cross-modal classifier with text embeddings derived from class-relevant prompts, streamlining training efficiency by avoiding the need for frequent text encoder processing. Additionally, we utilize text-based image augmentation, exploiting CLIP's robust image-text correlation to enrich training data significantly. Extensive experiments across multiple datasets demonstrate that SONO outperforms existing state-of-the-art methods in few-shot learning performance.
Minimax Regret Estimation for Generalizing Heterogeneous Treatment Effects with Multisite Data
Dec 15, 2024



To test scientific theories and develop individualized treatment rules, researchers often wish to learn heterogeneous treatment effects that can be consistently found across diverse populations and contexts. We consider the problem of generalizing heterogeneous treatment effects (HTE) based on data from multiple sites. A key challenge is that a target population may differ from the source sites in unknown and unobservable ways. This means that the estimates from site-specific models lack external validity, and a simple pooled analysis risks bias. We develop a robust CATE (conditional average treatment effect) estimation methodology with multisite data from heterogeneous populations. We propose a minimax-regret framework that learns a generalizable CATE model by minimizing the worst-case regret over a class of target populations whose CATE can be represented as convex combinations of site-specific CATEs. Using robust optimization, the proposed methodology accounts for distribution shifts in both individual covariates and treatment effect heterogeneity across sites. We show that the resulting CATE model has an interpretable closed-form solution, expressed as a weighted average of site-specific CATE models. Thus, researchers can utilize a flexible CATE estimation method within each site and aggregate site-specific estimates to produce the final model. Through simulations and a real-world application, we show that the proposed methodology improves the robustness and generalizability of existing approaches.
Timealign: A multi-modal object detection method for time misalignment fusing in autonomous driving
Dec 13, 2024



The multi-modal perception methods are thriving in the autonomous driving field due to their better usage of complementary data from different sensors. Such methods depend on calibration and synchronization between sensors to get accurate environmental information. There have already been studies about space-alignment robustness in autonomous driving object detection process, however, the research for time-alignment is relatively few. As in reality experiments, LiDAR point clouds are more challenging for real-time data transfer, our study used historical frames of LiDAR to better align features when the LiDAR data lags exist. We designed a Timealign module to predict and combine LiDAR features with observation to tackle such time misalignment based on SOTA GraphBEV framework.
Phi-4 Technical Report
Dec 12, 2024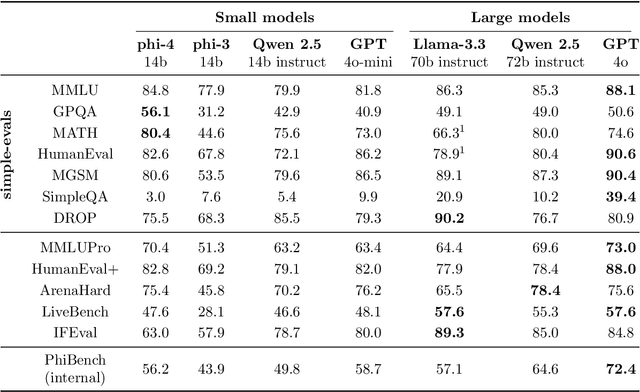
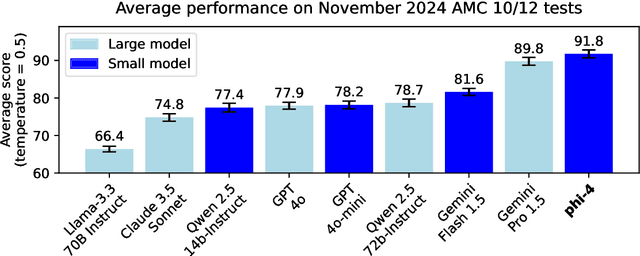

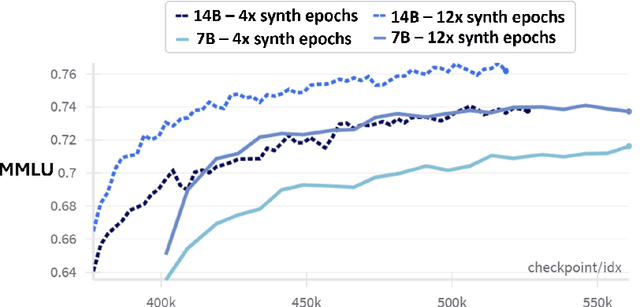
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
A Review of Human Emotion Synthesis Based on Generative Technology
Dec 10, 2024



Human emotion synthesis is a crucial aspect of affective computing. It involves using computational methods to mimic and convey human emotions through various modalities, with the goal of enabling more natural and effective human-computer interactions. Recent advancements in generative models, such as Autoencoders, Generative Adversarial Networks, Diffusion Models, Large Language Models, and Sequence-to-Sequence Models, have significantly contributed to the development of this field. However, there is a notable lack of comprehensive reviews in this field. To address this problem, this paper aims to address this gap by providing a thorough and systematic overview of recent advancements in human emotion synthesis based on generative models. Specifically, this review will first present the review methodology, the emotion models involved, the mathematical principles of generative models, and the datasets used. Then, the review covers the application of different generative models to emotion synthesis based on a variety of modalities, including facial images, speech, and text. It also examines mainstream evaluation metrics. Additionally, the review presents some major findings and suggests future research directions, providing a comprehensive understanding of the role of generative technology in the nuanced domain of emotion synthesis.
Exploring Critical Testing Scenarios for Decision-Making Policies: An LLM Approach
Dec 09, 2024



Recent years have witnessed surprising achievements of decision-making policies across various fields, such as autonomous driving and robotics. Testing for decision-making policies is crucial with the existence of critical scenarios that may threaten their reliability. Numerous research efforts have been dedicated to testing these policies. However, there are still significant challenges, such as low testing efficiency and diversity due to the complexity of the policies and environments under test. Inspired by the remarkable capabilities of large language models (LLMs), in this paper, we propose an LLM-driven online testing framework for efficiently testing decision-making policies. The main idea is to employ an LLM-based test scenario generator to intelligently generate challenging test cases through contemplation and reasoning. Specifically, we first design a "generate-test-feedback" pipeline and apply templated prompt engineering to fully leverage the knowledge and reasoning abilities of LLMs. Then, we introduce a multi-scale scenario generation strategy to address the inherent challenges LLMs face in making fine adjustments, further enhancing testing efficiency. Finally, we evaluate the LLM-driven approach on five widely used benchmarks. The experimental results demonstrate that our method significantly outperforms baseline approaches in uncovering both critical and diverse scenarios.