 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Terminal Agents Learn World Models for Free
May 23, 2026CLI agents are the closest thing language models have to an embodied setting: the model emits commands, the terminal executes them, and the returned stream -- stdout, errors, files, logs, and traces -- records the consequences. We argue that this stream is a supervision signal, but standard agent RL discards it: GRPO-style training updates action tokens with sparse outcome-level rewards while ignoring environment responses already in the rollout. Failed rollouts provide little policy-gradient signal despite containing rich evidence about how the environment responds. We introduce ECHO (Environment Cross-entropy Hybrid Objective), a hybrid objective that combines the standard policy-gradient loss on action tokens with an auxiliary loss that trains the policy to predict environment observation tokens resulting from its own actions. ECHO reuses the same forward pass as GRPO, requires no additional rollouts, and turns terminal feedback into dense supervision for all rollouts. ECHO doubles GRPO pass@1 on TerminalBench-2.0: Qwen3-8B improves from 2.70% to 5.17%, and Qwen3-14B from 5.17% to 10.79%. ECHO also produces policies that better predict terminal dynamics, even on trajectories they did not generate: across held-out rollouts, it sharply reduces environment-token cross-entropy while GRPO alone barely changes it. From base Qwen3-8B, ECHO matches expert-SFT-then-GRPO performance on held-out terminal tasks without expert demonstrations, and recovers roughly half of the expert-SFT initialization benefit on TerminalBench-2.0. In some settings, the environment prediction loss alone enables verifier-free self-improvement, allowing policies to improve on unseen OOD tasks by learning only from environment interactions. Together, these results suggest that environment observations are not merely context for future actions, but a dense, on-policy supervision signal already present in every rollout.
Phi-4-reasoning Technical Report
Apr 30, 2025We introduce Phi-4-reasoning, a 14-billion parameter reasoning model that achieves strong performance on complex reasoning tasks. Trained via supervised fine-tuning of Phi-4 on carefully curated set of "teachable" prompts-selected for the right level of complexity and diversity-and reasoning demonstrations generated using o3-mini, Phi-4-reasoning generates detailed reasoning chains that effectively leverage inference-time compute. We further develop Phi-4-reasoning-plus, a variant enhanced through a short phase of outcome-based reinforcement learning that offers higher performance by generating longer reasoning traces. Across a wide range of reasoning tasks, both models outperform significantly larger open-weight models such as DeepSeek-R1-Distill-Llama-70B model and approach the performance levels of full DeepSeek-R1 model. Our comprehensive evaluations span benchmarks in math and scientific reasoning, coding, algorithmic problem solving, planning, and spatial understanding. Interestingly, we observe a non-trivial transfer of improvements to general-purpose benchmarks as well. In this report, we provide insights into our training data, our training methodologies, and our evaluations. We show that the benefit of careful data curation for supervised fine-tuning (SFT) extends to reasoning language models, and can be further amplified by reinforcement learning (RL). Finally, our evaluation points to opportunities for improving how we assess the performance and robustness of reasoning models.
Phi-4 Technical Report
Dec 12, 2024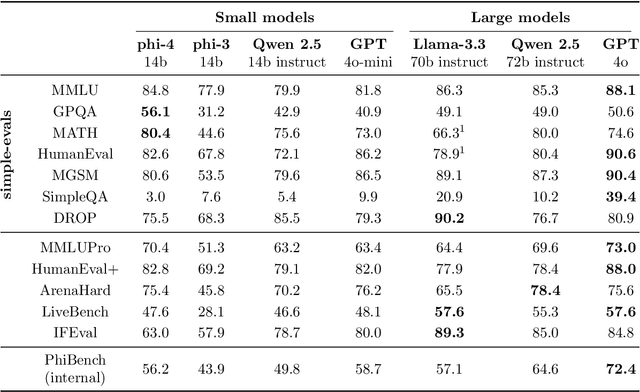
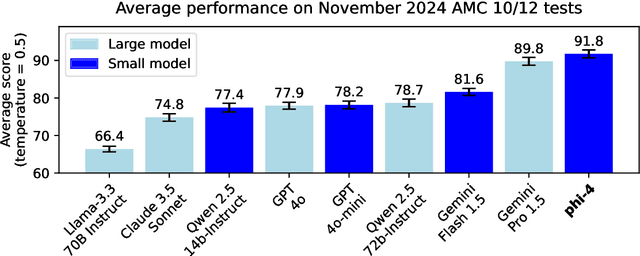

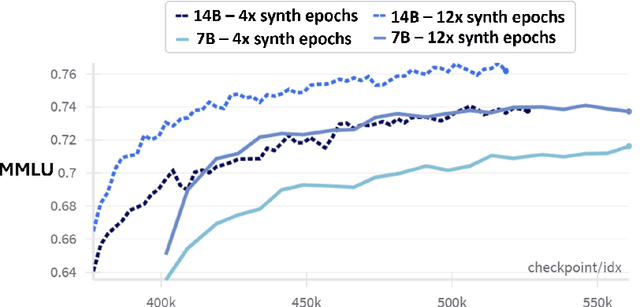
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Textbooks Are All You Need
Jun 20, 2023



We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.