 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4 Technical Report
Dec 12, 2024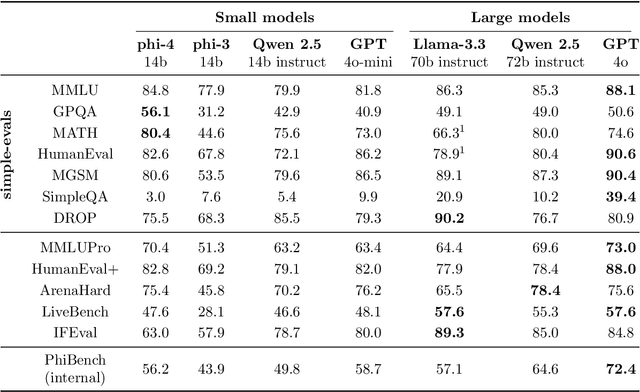
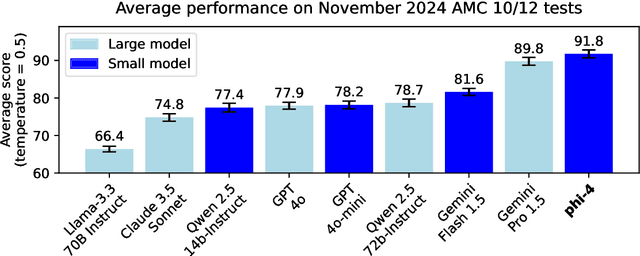

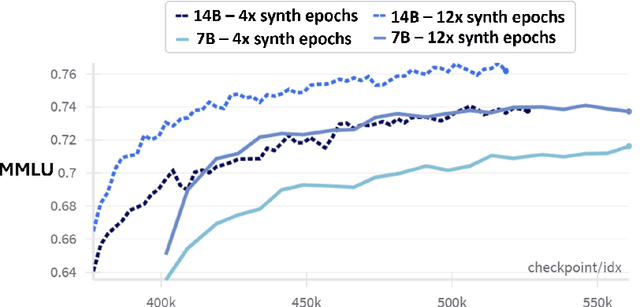
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
Small Language Models for Application Interactions: A Case Study
May 23, 2024



We study the efficacy of Small Language Models (SLMs) in facilitating application usage through natural language interactions. Our focus here is on a particular internal application used in Microsoft for cloud supply chain fulfilment. Our experiments show that small models can outperform much larger ones in terms of both accuracy and running time, even when fine-tuned on small datasets. Alongside these results, we also highlight SLM-based system design considerations.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Positional Description Matters for Transformers Arithmetic
Nov 22, 2023Transformers, central to the successes in modern Natural Language Processing, often falter on arithmetic tasks despite their vast capabilities --which paradoxically include remarkable coding abilities. We observe that a crucial challenge is their naive reliance on positional information to solve arithmetic problems with a small number of digits, leading to poor performance on larger numbers. Herein, we delve deeper into the role of positional encoding, and propose several ways to fix the issue, either by modifying the positional encoding directly, or by modifying the representation of the arithmetic task to leverage standard positional encoding differently. We investigate the value of these modifications for three tasks: (i) classical multiplication, (ii) length extrapolation in addition, and (iii) addition in natural language context. For (i) we train a small model on a small dataset (100M parameters and 300k samples) with remarkable aptitude in (direct, no scratchpad) 15 digits multiplication and essentially perfect up to 12 digits, while usual training in this context would give a model failing at 4 digits multiplication. In the experiments on addition, we use a mere 120k samples to demonstrate: for (ii) extrapolation from 10 digits to testing on 12 digits numbers while usual training would have no extrapolation, and for (iii) almost perfect accuracy up to 5 digits while usual training would be correct only up to 3 digits (which is essentially memorization with a training set of 120k samples).
Textbooks Are All You Need II: phi-1.5 technical report
Sep 11, 2023



We continue the investigation into the power of smaller Transformer-based language models as initiated by \textbf{TinyStories} -- a 10 million parameter model that can produce coherent English -- and the follow-up work on \textbf{phi-1}, a 1.3 billion parameter model with Python coding performance close to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to generate ``textbook quality" data as a way to enhance the learning process compared to traditional web data. We follow the ``Textbooks Are All You Need" approach, focusing this time on common sense reasoning in natural language, and create a new 1.3 billion parameter model named \textbf{phi-1.5}, with performance on natural language tasks comparable to models 5x larger, and surpassing most non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic coding. More generally, \textbf{phi-1.5} exhibits many of the traits of much larger LLMs, both good -- such as the ability to ``think step by step" or perform some rudimentary in-context learning -- and bad, including hallucinations and the potential for toxic and biased generations -- encouragingly though, we are seeing improvement on that front thanks to the absence of web data. We open-source \textbf{phi-1.5} to promote further research on these urgent topics.
Textbooks Are All You Need
Jun 20, 2023



We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Mar 27, 2023



Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT-4 is part of a new cohort of LLMs (along with ChatGPT and Google's PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4's performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
Learning threshold neurons via the "edge of stability"
Dec 14, 2022



Existing analyses of neural network training often operate under the unrealistic assumption of an extremely small learning rate. This lies in stark contrast to practical wisdom and empirical studies, such as the work of J. Cohen et al. (ICLR 2021), which exhibit startling new phenomena (the "edge of stability" or "unstable convergence") and potential benefits for generalization in the large learning rate regime. Despite a flurry of recent works on this topic, however, the latter effect is still poorly understood. In this paper, we take a step towards understanding genuinely non-convex training dynamics with large learning rates by performing a detailed analysis of gradient descent for simplified models of two-layer neural networks. For these models, we provably establish the edge of stability phenomenon and discover a sharp phase transition for the step size below which the neural network fails to learn "threshold-like" neurons (i.e., neurons with a non-zero first-layer bias). This elucidates one possible mechanism by which the edge of stability can in fact lead to better generalization, as threshold neurons are basic building blocks with useful inductive bias for many tasks.
How to Fine-Tune Vision Models with SGD
Nov 17, 2022SGD (with momentum) and AdamW are the two most used optimizers for fine-tuning large neural networks in computer vision. When the two methods perform the same, SGD is preferable because it uses less memory (12 bytes/parameter) than AdamW (16 bytes/parameter). However, on a suite of downstream tasks, especially those with distribution shifts, we show that fine-tuning with AdamW performs substantially better than SGD on modern Vision Transformer and ConvNeXt models. We find that large gaps in performance between SGD and AdamW occur when the fine-tuning gradients in the first "embedding" layer are much larger than in the rest of the model. Our analysis suggests an easy fix that works consistently across datasets and models: merely freezing the embedding layer (less than 1\% of the parameters) leads to SGD performing competitively with AdamW while using less memory. Our insights result in state-of-the-art accuracies on five popular distribution shift benchmarks: WILDS-FMoW, WILDS-Camelyon, Living-17, Waterbirds, and DomainNet.
Unveiling Transformers with LEGO: a synthetic reasoning task
Jun 09, 2022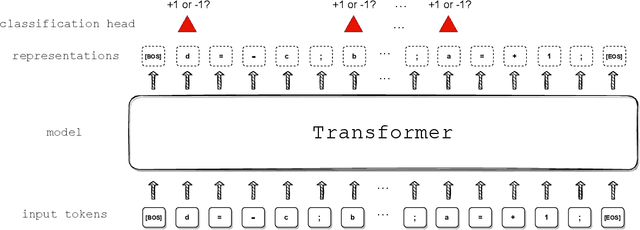
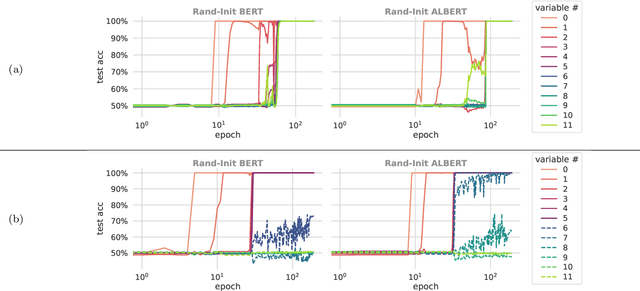
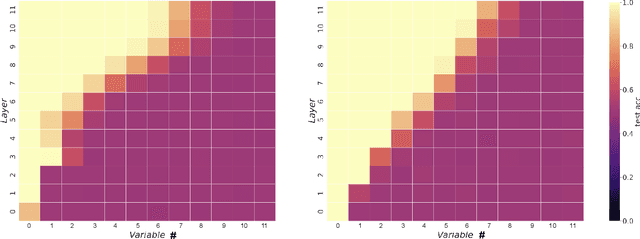
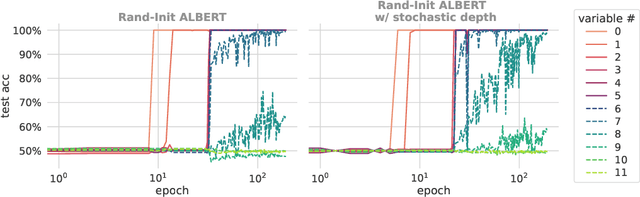
We propose a synthetic task, LEGO (Learning Equality and Group Operations), that encapsulates the problem of following a chain of reasoning, and we study how the transformer architecture learns this task. We pay special attention to data effects such as pretraining (on seemingly unrelated NLP tasks) and dataset composition (e.g., differing chain length at training and test time), as well as architectural variants such as weight-tied layers or adding convolutional components. We study how the trained models eventually succeed at the task, and in particular, we are able to understand (to some extent) some of the attention heads as well as how the information flows in the network. Based on these observations we propose a hypothesis that here pretraining helps merely due to being a smart initialization rather than some deep knowledge stored in the network. We also observe that in some data regime the trained transformer finds "shortcut" solutions to follow the chain of reasoning, which impedes the model's ability to generalize to simple variants of the main task, and moreover we find that one can prevent such shortcut with appropriate architecture modification or careful data preparation. Motivated by our findings, we begin to explore the task of learning to execute C programs, where a convolutional modification to transformers, namely adding convolutional structures in the key/query/value maps, shows an encouraging edge.