 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIMOS: Disentangling Instance-level Moving Object Segmentation
Jun 11, 2026Moving instance segmentation (MIS) attracts increasing attention due to its broad applications in traffic surveillance, autonomous driving, and animal tracking. Event cameras record asynchronous brightness changes, providing high temporal resolution and dynamic range, which makes them highly sensitive to motion information. By fusing event and image features, motion cues from events can complement spatial details from images, enhancing the performance of MIS. However, current multimodal MIS methods still struggle to segment small moving instances, as event cameras often yield sparse features under limited resolution. Moreover, event features entangle appearance attributes with motion cues, which further restricts effective cross-modal fusion. To address these challenges, we first propose a dual-disentangling feature extraction framework that separates and extracts appearance and motion information within both image and event modalities, thereby improving feature density. Subsequently, a multi-granularity cross-modal alignment is introduced to align distributionally and semantically consistent features across modalities, enabling more effective fusion with rich spatial and temporal details. The experiment results demonstrate that our method achieves state-of-the-art performance in multimodal MIS, especially for small instances under challenging conditions such as fast motion and low-light settings.
Generating Adversarial Events: A Motion-Aware Point Cloud Framework
Feb 09, 2026Event cameras have been widely adopted in safety-critical domains such as autonomous driving, robotics, and human-computer interaction. A pressing challenge arises from the vulnerability of deep neural networks to adversarial examples, which poses a significant threat to the reliability of event-based systems. Nevertheless, research into adversarial attacks on events is scarce. This is primarily due to the non-differentiable nature of mainstream event representations, which hinders the extension of gradient-based attack methods. In this paper, we propose MA-ADV, a novel \textbf{M}otion-\textbf{A}ware \textbf{Adv}ersarial framework. To the best of our knowledge, this is the first work to generate adversarial events by leveraging point cloud representations. MA-ADV accounts for high-frequency noise in events and employs a diffusion-based approach to smooth perturbations, while fully leveraging the spatial and temporal relationships among events. Finally, MA-ADV identifies the minimal-cost perturbation through a combination of sample-wise Adam optimization, iterative refinement, and binary search. Extensive experimental results validate that MA-ADV ensures a 100\% attack success rate with minimal perturbation cost, and also demonstrate enhanced robustness against defenses, underscoring the critical security challenges facing future event-based perception systems.
E^2-LLM: Bridging Neural Signals and Interpretable Affective Analysis
Jan 11, 2026Emotion recognition from electroencephalography (EEG) signals remains challenging due to high inter-subject variability, limited labeled data, and the lack of interpretable reasoning in existing approaches. While recent multimodal large language models (MLLMs) have advanced emotion analysis, they have not been adapted to handle the unique spatiotemporal characteristics of neural signals. We present E^2-LLM (EEG-to-Emotion Large Language Model), the first MLLM framework for interpretable emotion analysis from EEG. E^2-LLM integrates a pretrained EEG encoder with Qwen-based LLMs through learnable projection layers, employing a multi-stage training pipeline that encompasses emotion-discriminative pretraining, cross-modal alignment, and instruction tuning with chain-of-thought reasoning. We design a comprehensive evaluation protocol covering basic emotion prediction, multi-task reasoning, and zero-shot scenario understanding. Experiments on the dataset across seven emotion categories demonstrate that E^2-LLM achieves excellent performance on emotion classification, with larger variants showing enhanced reliability and superior zero-shot generalization to complex reasoning scenarios. Our work establishes a new paradigm combining physiological signals with LLM reasoning capabilities, showing that model scaling improves both recognition accuracy and interpretable emotional understanding in affective computing.
Spiking Transformers Need High Frequency Information
May 24, 2025Spiking Transformers offer an energy-efficient alternative to conventional deep learning by transmitting information solely through binary (0/1) spikes. However, there remains a substantial performance gap compared to artificial neural networks. A common belief is that their binary and sparse activation transmission leads to information loss, thus degrading feature representation and accuracy. In this work, however, we reveal for the first time that spiking neurons preferentially propagate low-frequency information. We hypothesize that the rapid dissipation of high-frequency components is the primary cause of performance degradation. For example, on Cifar-100, adopting Avg-Pooling (low-pass) for token mixing lowers performance to 76.73%; interestingly, replacing it with Max-Pooling (high-pass) pushes the top-1 accuracy to 79.12%, surpassing the well-tuned Spikformer baseline by 0.97%. Accordingly, we introduce Max-Former that restores high-frequency signals through two frequency-enhancing operators: extra Max-Pooling in patch embedding and Depth-Wise Convolution in place of self-attention. Notably, our Max-Former (63.99 M) hits the top-1 accuracy of 82.39% on ImageNet, showing a +7.58% improvement over Spikformer with comparable model size (74.81%, 66.34 M). We hope this simple yet effective solution inspires future research to explore the distinctive nature of spiking neural networks, beyond the established practice in standard deep learning.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025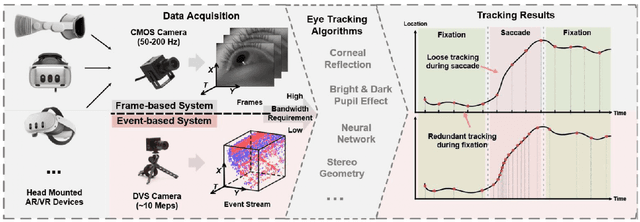
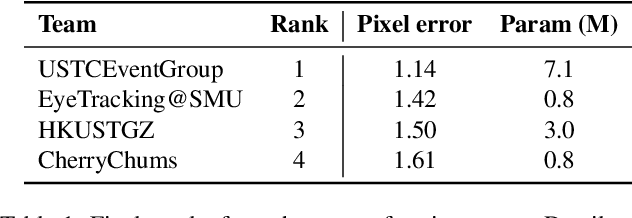
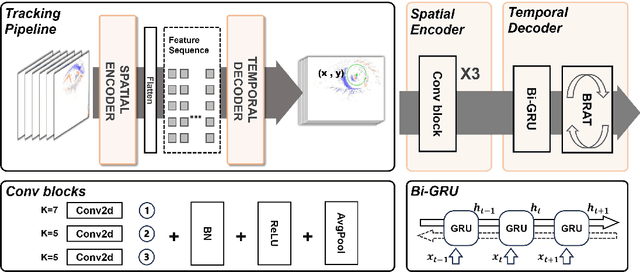

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Exploring Temporal Dynamics in Event-based Eye Tracker
Mar 31, 2025



Eye-tracking is a vital technology for human-computer interaction, especially in wearable devices such as AR, VR, and XR. The realization of high-speed and high-precision eye-tracking using frame-based image sensors is constrained by their limited temporal resolution, which impairs the accurate capture of rapid ocular dynamics, such as saccades and blinks. Event cameras, inspired by biological vision systems, are capable of perceiving eye movements with extremely low power consumption and ultra-high temporal resolution. This makes them a promising solution for achieving high-speed, high-precision tracking with rich temporal dynamics. In this paper, we propose TDTracker, an effective eye-tracking framework that captures rapid eye movements by thoroughly modeling temporal dynamics from both implicit and explicit perspectives. TDTracker utilizes 3D convolutional neural networks to capture implicit short-term temporal dynamics and employs a cascaded structure consisting of a Frequency-aware Module, GRU, and Mamba to extract explicit long-term temporal dynamics. Ultimately, a prediction heatmap is used for eye coordinate regression. Experimental results demonstrate that TDTracker achieves state-of-the-art (SOTA) performance on the synthetic SEET dataset and secured Third place in the CVPR event-based eye-tracking challenge 2025. Our code is available at https://github.com/rhwxmx/TDTracker.
ClearSight: Human Vision-Inspired Solutions for Event-Based Motion Deblurring
Jan 27, 2025



Motion deblurring addresses the challenge of image blur caused by camera or scene movement. Event cameras provide motion information that is encoded in the asynchronous event streams. To efficiently leverage the temporal information of event streams, we employ Spiking Neural Networks (SNNs) for motion feature extraction and Artificial Neural Networks (ANNs) for color information processing. Due to the non-uniform distribution and inherent redundancy of event data, existing cross-modal feature fusion methods exhibit certain limitations. Inspired by the visual attention mechanism in the human visual system, this study introduces a bioinspired dual-drive hybrid network (BDHNet). Specifically, the Neuron Configurator Module (NCM) is designed to dynamically adjusts neuron configurations based on cross-modal features, thereby focusing the spikes in blurry regions and adapting to varying blurry scenarios dynamically. Additionally, the Region of Blurry Attention Module (RBAM) is introduced to generate a blurry mask in an unsupervised manner, effectively extracting motion clues from the event features and guiding more accurate cross-modal feature fusion. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art methods on both synthetic and real-world datasets.
Frequency-aware Event Cloud Network
Dec 30, 2024



Event cameras are biologically inspired sensors that emit events asynchronously with remarkable temporal resolution, garnering significant attention from both industry and academia. Mainstream methods favor frame and voxel representations, which reach a satisfactory performance while introducing time-consuming transformation, bulky models, and sacrificing fine-grained temporal information. Alternatively, Point Cloud representation demonstrates promise in addressing the mentioned weaknesses, but it ignores the polarity information, and its models have limited proficiency in abstracting long-term events' features. In this paper, we propose a frequency-aware network named FECNet that leverages Event Cloud representations. FECNet fully utilizes 2S-1T-1P Event Cloud by innovating the event-based Group and Sampling module. To accommodate the long sequence events from Event Cloud, FECNet embraces feature extraction in the frequency domain via the Fourier transform. This approach substantially extinguishes the explosion of Multiply Accumulate Operations (MACs) while effectively abstracting spatial-temporal features. We conducted extensive experiments on event-based object classification, action recognition, and human pose estimation tasks, and the results substantiate the effectiveness and efficiency of FECNet.
Adaptive Calibration: A Unified Conversion Framework of Spiking Neural Network
Dec 18, 2024Spiking Neural Networks (SNNs) are seen as an energy-efficient alternative to traditional Artificial Neural Networks (ANNs), but the performance gap remains a challenge. While this gap is narrowing through ANN-to-SNN conversion, substantial computational resources are still needed, and the energy efficiency of converted SNNs cannot be ensured. To address this, we present a unified training-free conversion framework that significantly enhances both the performance and efficiency of converted SNNs. Inspired by the biological nervous system, we propose a novel Adaptive-Firing Neuron Model (AdaFire), which dynamically adjusts firing patterns across different layers to substantially reduce the Unevenness Error - the primary source of error of converted SNNs within limited inference timesteps. We further introduce two efficiency-enhancing techniques: the Sensitivity Spike Compression (SSC) technique for reducing spike operations, and the Input-aware Adaptive Timesteps (IAT) technique for decreasing latency. These methods collectively enable our approach to achieve state-of-the-art performance while delivering significant energy savings of up to 70.1%, 60.3%, and 43.1% on CIFAR-10, CIFAR-100, and ImageNet datasets, respectively. Extensive experiments across 2D, 3D, event-driven classification tasks, object detection, and segmentation tasks, demonstrate the effectiveness of our method in various domains. The code is available at: https://github.com/bic-L/burst-ann2snn.
Event-based Motion Deblurring via Multi-Temporal Granularity Fusion
Dec 16, 2024



Conventional frame-based cameras inevitably produce blurry effects due to motion occurring during the exposure time. Event camera, a bio-inspired sensor offering continuous visual information could enhance the deblurring performance. Effectively utilizing the high-temporal-resolution event data is crucial for extracting precise motion information and enhancing deblurring performance. However, existing event-based image deblurring methods usually utilize voxel-based event representations, losing the fine-grained temporal details that are mathematically essential for fast motion deblurring. In this paper, we first introduce point cloud-based event representation into the image deblurring task and propose a Multi-Temporal Granularity Network (MTGNet). It combines the spatially dense but temporally coarse-grained voxel-based event representation and the temporally fine-grained but spatially sparse point cloud-based event. To seamlessly integrate such complementary representations, we design a Fine-grained Point Branch. An Aggregation and Mapping Module (AMM) is proposed to align the low-level point-based features with frame-based features and an Adaptive Feature Diffusion Module (AFDM) is designed to manage the resolution discrepancies between event data and image data by enriching the sparse point feature. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art approaches on both synthetic and real-world datasets.