 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding the Score: Explicit Visual Premise Verification for Reliable Vision-Language Process Reward Models
Mar 17, 2026Vision-language process reward models (VL-PRMs) are increasingly used to score intermediate reasoning steps and rerank candidates under test-time scaling. However, they often function as black-box judges: a low step score may reflect a genuine reasoning mistake or simply the verifier's misperception of the image. This entanglement between perception and reasoning leads to systematic false positives (rewarding hallucinated visual premises) and false negatives (penalizing correct grounded statements), undermining both reranking and error localization. We introduce Explicit Visual Premise Verification (EVPV), a lightweight verification interface that conditions step scoring on the reliability of the visual premises a step depends on. The policy is prompted to produce a step-wise visual checklist that makes required visual facts explicit, while a constraint extractor independently derives structured visual constraints from the input image. EVPV matches checklist claims against these constraints to compute a scalar visual reliability signal, and calibrates PRM step rewards via reliability gating: rewards for visually dependent steps are attenuated when reliability is low and preserved when reliability is high. This decouples perceptual uncertainty from logical evaluation without per-step tool calls. Experiments on VisualProcessBench and six multimodal reasoning benchmarks show that EVPV improves step-level verification and consistently boosts Best-of-N reranking accuracy over strong baselines. Furthermore, injecting controlled corruption into the extracted constraints produces monotonic performance degradation, providing causal evidence that the gains arise from constraint fidelity and explicit premise verification rather than incidental prompt effects. Code is available at: https://github.com/Qwen-Applications/EVPV-PRM
Rationale Matters: Learning Transferable Rubrics via Proxy-Guided Critique for VLMReward Models
Mar 17, 2026Generative reward models (GRMs) for vision-language models (VLMs) often evaluate outputs via a three-stage pipeline: rubric generation, criterion-based scoring, and a final verdict. However, the intermediate rubric is rarely optimized directly. Prior work typically either treats rubrics as incidental or relies on expensive LLM-as-judge checks that provide no differentiable signal and limited training-time guidance. We propose Proxy-GRM, which introduces proxy-guided rubric verification into Reinforcement Learning (RL) to explicitly enhance rubric quality. Concretely, we train lightweight proxy agents (Proxy-SFT and Proxy-RL) that take a candidate rubric together with the original query and preference pair, and then predict the preference ordering using only the rubric as evidence. The proxy's prediction accuracy serves as a rubric-quality reward, incentivizing the model to produce rubrics that are internally consistent and transferable. With ~50k data samples, Proxy-GRM reaches state-of-the-art results on the VL-Reward Bench, Multimodal Reward Bench, and MM-RLHF-Reward Bench, outperforming the methods trained on four times the data. Ablations show Proxy-SFT is a stronger verifier than Proxy-RL, and implicit reward aggregation performs best. Crucially, the learned rubrics transfer to unseen evaluators, improving reward accuracy at test time without additional training. Our code is available at https://github.com/Qwen-Applications/Proxy-GRM.
One Size Does Not Fit All: A Distribution-Aware Sparsification for More Precise Model Merging
Aug 08, 2025Model merging has emerged as a compelling data-free paradigm for multi-task learning, enabling the fusion of multiple fine-tuned models into a single, powerful entity. A key technique in merging methods is sparsification, which prunes redundant parameters from task vectors to mitigate interference. However, prevailing approaches employ a ``one-size-fits-all'' strategy, applying a uniform sparsity ratio that overlooks the inherent structural and statistical heterogeneity of model parameters. This often leads to a suboptimal trade-off, where critical parameters are inadvertently pruned while less useful ones are retained. To address this limitation, we introduce \textbf{TADrop} (\textbf{T}ensor-wise \textbf{A}daptive \textbf{Drop}), an adaptive sparsification strategy that respects this heterogeneity. Instead of a global ratio, TADrop assigns a tailored sparsity level to each parameter tensor based on its distributional properties. The core intuition is that tensors with denser, more redundant distributions can be pruned aggressively, while sparser, more critical ones are preserved. As a simple and plug-and-play module, we validate TADrop by integrating it with foundational, classic, and SOTA merging methods. Extensive experiments across diverse tasks (vision, language, and multimodal) and models (ViT, BEiT) demonstrate that TADrop consistently and significantly boosts their performance. For instance, when enhancing a leading merging method, it achieves an average performance gain of 2.0\% across 8 ViT-B/32 tasks. TADrop provides a more effective way to mitigate parameter interference by tailoring sparsification to the model's structure, offering a new baseline for high-performance model merging.
OIBench: Benchmarking Strong Reasoning Models with Olympiad in Informatics
Jun 12, 2025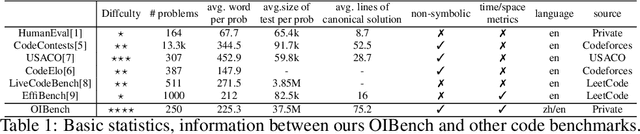

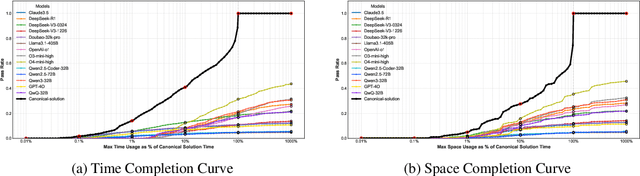
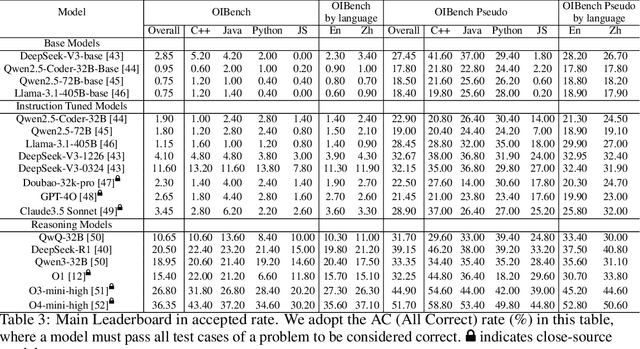
As models become increasingly sophisticated, conventional algorithm benchmarks are increasingly saturated, underscoring the need for more challenging benchmarks to guide future improvements in algorithmic reasoning. This paper introduces OIBench, a high-quality, private, and challenging olympiad-level informatics dataset comprising 250 carefully curated original problems. We detail the construction methodology of the benchmark, ensuring a comprehensive assessment across various programming paradigms and complexities, and we demonstrate its contamination-resistant properties via experiments. We propose Time/Space Completion Curves for finer-grained efficiency analysis and enable direct human-model comparisons through high-level participant evaluations. Our experiments reveal that while open-source models lag behind closed-source counterparts, current SOTA models already outperform most human participants in both correctness and efficiency, while still being suboptimal compared to the canonical solutions. By releasing OIBench as a fully open-source resource (https://huggingface.co/datasets/AGI-Eval/OIBench), we hope this benchmark will contribute to advancing code reasoning capabilities for future LLMs.
Boosting Text-To-Image Generation via Multilingual Prompting in Large Multimodal Models
Jan 13, 2025Previous work on augmenting large multimodal models (LMMs) for text-to-image (T2I) generation has focused on enriching the input space of in-context learning (ICL). This includes providing a few demonstrations and optimizing image descriptions to be more detailed and logical. However, as demand for more complex and flexible image descriptions grows, enhancing comprehension of input text within the ICL paradigm remains a critical yet underexplored area. In this work, we extend this line of research by constructing parallel multilingual prompts aimed at harnessing the multilingual capabilities of LMMs. More specifically, we translate the input text into several languages and provide the models with both the original text and the translations. Experiments on two LMMs across 3 benchmarks show that our method, PMT2I, achieves superior performance in general, compositional, and fine-grained assessments, especially in human preference alignment. Additionally, with its advantage of generating more diverse images, PMT2I significantly outperforms baseline prompts when incorporated with reranking methods. Our code and parallel multilingual data can be found at https://github.com/takagi97/PMT2I.