 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025



Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
May 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities but often face challenges with tasks requiring sophisticated reasoning. While Chain-of-Thought (CoT) prompting significantly enhances reasoning, it indiscriminately generates lengthy reasoning steps for all queries, leading to substantial computational costs and inefficiency, especially for simpler inputs. To address this critical issue, we introduce AdaCoT (Adaptive Chain-of-Thought), a novel framework enabling LLMs to adaptively decide when to invoke CoT. AdaCoT framed adaptive reasoning as a Pareto optimization problem that seeks to balance model performance with the costs associated with CoT invocation (both frequency and computational overhead). We propose a reinforcement learning (RL) based method, specifically utilizing Proximal Policy Optimization (PPO), to dynamically control the CoT triggering decision boundary by adjusting penalty coefficients, thereby allowing the model to determine CoT necessity based on implicit query complexity. A key technical contribution is Selective Loss Masking (SLM), designed to counteract decision boundary collapse during multi-stage RL training, ensuring robust and stable adaptive triggering. Experimental results demonstrate that AdaCoT successfully navigates the Pareto frontier, achieving substantial reductions in CoT usage for queries not requiring elaborate reasoning. For instance, on our production traffic testset, AdaCoT reduced CoT triggering rates to as low as 3.18\% and decreased average response tokens by 69.06%, while maintaining high performance on complex tasks.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Motion Planning for Robotics: A Review for Sampling-based Planners
Oct 28, 2024



Recent advancements in robotics have transformed industries such as manufacturing, logistics, surgery, and planetary exploration. A key challenge is developing efficient motion planning algorithms that allow robots to navigate complex environments while avoiding collisions and optimizing metrics like path length, sweep area, execution time, and energy consumption. Among the available algorithms, sampling-based methods have gained the most traction in both research and industry due to their ability to handle complex environments, explore free space, and offer probabilistic completeness along with other formal guarantees. Despite their widespread application, significant challenges still remain. To advance future planning algorithms, it is essential to review the current state-of-the-art solutions and their limitations. In this context, this work aims to shed light on these challenges and assess the development and applicability of sampling-based methods. Furthermore, we aim to provide an in-depth analysis of the design and evaluation of ten of the most popular planners across various scenarios. Our findings highlight the strides made in sampling-based methods while underscoring persistent challenges. This work offers an overview of the important ongoing research in robotic motion planning.
Only 5\% Attention Is All You Need: Efficient Long-range Document-level Neural Machine Translation
Sep 25, 2023



Document-level Neural Machine Translation (DocNMT) has been proven crucial for handling discourse phenomena by introducing document-level context information. One of the most important directions is to input the whole document directly to the standard Transformer model. In this case, efficiency becomes a critical concern due to the quadratic complexity of the attention module. Existing studies either focus on the encoder part, which cannot be deployed on sequence-to-sequence generation tasks, e.g., Machine Translation (MT), or suffer from a significant performance drop. In this work, we keep the translation performance while gaining 20\% speed up by introducing extra selection layer based on lightweight attention that selects a small portion of tokens to be attended. It takes advantage of the original attention to ensure performance and dimension reduction to accelerate inference. Experimental results show that our method could achieve up to 95\% sparsity (only 5\% tokens attended) approximately, and save 93\% computation cost on the attention module compared with the original Transformer, while maintaining the performance.
Beyond Triplet: Leveraging the Most Data for Multimodal Machine Translation
Dec 20, 2022



Multimodal machine translation (MMT) aims to improve translation quality by incorporating information from other modalities, such as vision. Previous MMT systems mainly focus on better access and use of visual information and tend to validate their methods on image-related datasets. These studies face two challenges. First, they can only utilize triple data (bilingual texts with images), which is scarce; second, current benchmarks are relatively restricted and do not correspond to realistic scenarios. Therefore, this paper correspondingly establishes new methods and new datasets for MMT. First, we propose a framework 2/3-Triplet with two new approaches to enhance MMT by utilizing large-scale non-triple data: monolingual image-text data and parallel text-only data. Second, we construct an English-Chinese {e}-commercial {m}ulti{m}odal {t}ranslation dataset (including training and testing), named EMMT, where its test set is carefully selected as some words are ambiguous and shall be translated mistakenly without the help of images. Experiments show that our method is more suitable for real-world scenarios and can significantly improve translation performance by using more non-triple data. In addition, our model also rivals various SOTA models in conventional multimodal translation benchmarks.
Better Datastore, Better Translation: Generating Datastores from Pre-Trained Models for Nearest Neural Machine Translation
Dec 17, 2022



Nearest Neighbor Machine Translation (kNNMT) is a simple and effective method of augmenting neural machine translation (NMT) with a token-level nearest neighbor retrieval mechanism. The effectiveness of kNNMT directly depends on the quality of retrieved neighbors. However, original kNNMT builds datastores based on representations from NMT models, which would result in poor retrieval accuracy when NMT models are not good enough, leading to sub-optimal translation performance. In this paper, we propose PRED, a framework that leverages Pre-trained models for Datastores in kNN-MT. Better representations from pre-trained models allow us to build datastores of better quality. We also design a novel contrastive alignment objective to mitigate the representation gap between the NMT model and pre-trained models, enabling the NMT model to retrieve from better datastores. We conduct extensive experiments on both bilingual and multilingual translation benchmarks, including WMT17 English $\leftrightarrow$ Chinese, WMT14 English $\leftrightarrow$ German, IWSLT14 German $\leftrightarrow$ English, and IWSLT14 multilingual datasets. Empirical results demonstrate the effectiveness of PRED.
Controlling Styles in Neural Machine Translation with Activation Prompt
Dec 17, 2022



Neural machine translation(NMT) has aroused wide attention due to its impressive quality. Beyond quality, controlling translation styles is also an important demand for many languages. Previous related studies mainly focus on controlling formality and gain some improvements. However, they still face two challenges. The first is the evaluation limitation. Style contains abundant information including lexis, syntax, etc. But only formality is well studied. The second is the heavy reliance on iterative fine-tuning when new styles are required. Correspondingly, this paper contributes in terms of the benchmark and approach. First, we re-visit this task and propose a multiway stylized machine translation (MSMT) benchmark, which includes multiple categories of styles in four language directions to push the boundary of this task. Second, we propose a method named style activation prompt (StyleAP) by retrieving prompts from stylized monolingual corpus, which needs no extra fine-tuning. Experiments show that StyleAP could effectively control the style of translation and achieve remarkable performance. All of our data and code are released at https://github.com/IvanWang0730/StyleAP.
Zero-shot Domain Adaptation for Neural Machine Translation with Retrieved Phrase-level Prompts
Sep 23, 2022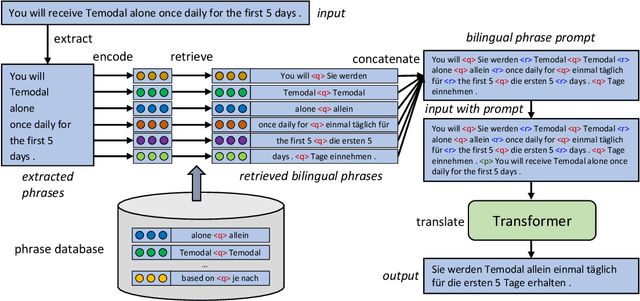

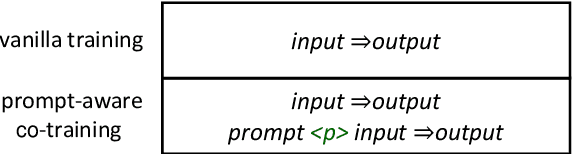

Domain adaptation is an important challenge for neural machine translation. However, the traditional fine-tuning solution requires multiple extra training and yields a high cost. In this paper, we propose a non-tuning paradigm, resolving domain adaptation with a prompt-based method. Specifically, we construct a bilingual phrase-level database and retrieve relevant pairs from it as a prompt for the input sentences. By utilizing Retrieved Phrase-level Prompts (RePP), we effectively boost the translation quality. Experiments show that our method improves domain-specific machine translation for 6.2 BLEU scores and improves translation constraints for 11.5% accuracy without additional training.
Multilingual Translation via Grafting Pre-trained Language Models
Sep 11, 2021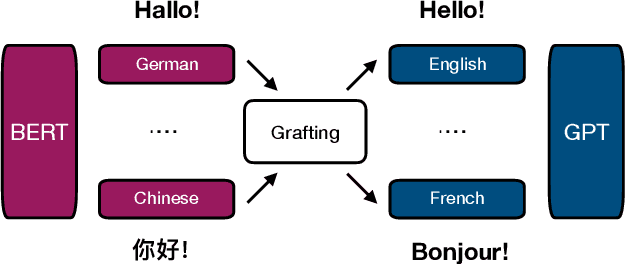
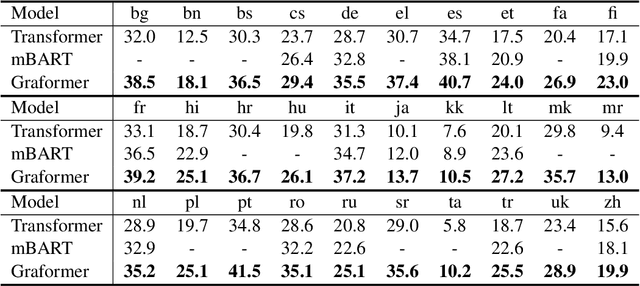
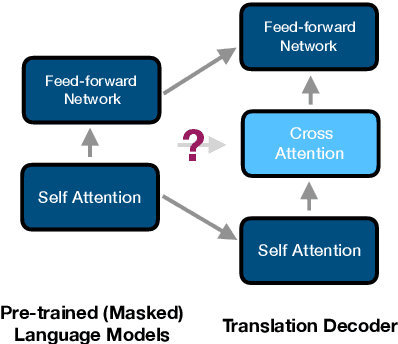
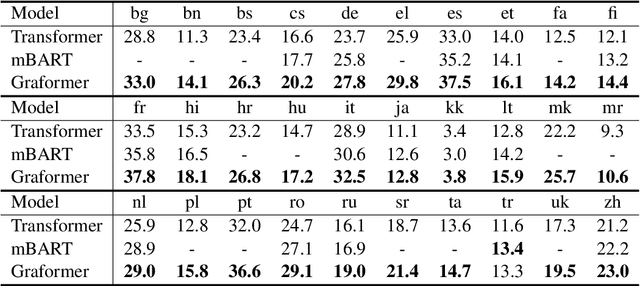
Can pre-trained BERT for one language and GPT for another be glued together to translate texts? Self-supervised training using only monolingual data has led to the success of pre-trained (masked) language models in many NLP tasks. However, directly connecting BERT as an encoder and GPT as a decoder can be challenging in machine translation, for GPT-like models lack a cross-attention component that is needed in seq2seq decoders. In this paper, we propose Graformer to graft separately pre-trained (masked) language models for machine translation. With monolingual data for pre-training and parallel data for grafting training, we maximally take advantage of the usage of both types of data. Experiments on 60 directions show that our method achieves average improvements of 5.8 BLEU in x2en and 2.9 BLEU in en2x directions comparing with the multilingual Transformer of the same size.