 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinkedOut: Linking World Knowledge Representation Out of Video LLM for Next-Generation Video Recommendation
Dec 18, 2025Video Large Language Models (VLLMs) unlock world-knowledge-aware video understanding through pretraining on internet-scale data and have already shown promise on tasks such as movie analysis and video question answering. However, deploying VLLMs for downstream tasks such as video recommendation remains challenging, since real systems require multi-video inputs, lightweight backbones, low-latency sequential inference, and rapid response. In practice, (1) decode-only generation yields high latency for sequential inference, (2) typical interfaces do not support multi-video inputs, and (3) constraining outputs to language discards fine-grained visual details that matter for downstream vision tasks. We argue that these limitations stem from the absence of a representation that preserves pixel-level detail while leveraging world knowledge. We present LinkedOut, a representation that extracts VLLM world knowledge directly from video to enable fast inference, supports multi-video histories, and removes the language bottleneck. LinkedOut extracts semantically grounded, knowledge-aware tokens from raw frames using VLLMs, guided by promptable queries and optional auxiliary modalities. We introduce a cross-layer knowledge fusion MoE that selects the appropriate level of abstraction from the rich VLLM features, enabling personalized, interpretable, and low-latency recommendation. To our knowledge, LinkedOut is the first VLLM-based video recommendation method that operates on raw frames without handcrafted labels, achieving state-of-the-art results on standard benchmarks. Interpretability studies and ablations confirm the benefits of layer diversity and layer-wise fusion, pointing to a practical path that fully leverages VLLM world-knowledge priors and visual reasoning for downstream vision tasks such as recommendation.
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Leveraging Large Language Models for Career Mobility Analysis: A Study of Gender, Race, and Job Change Using U.S. Online Resume Profiles
Nov 15, 2025
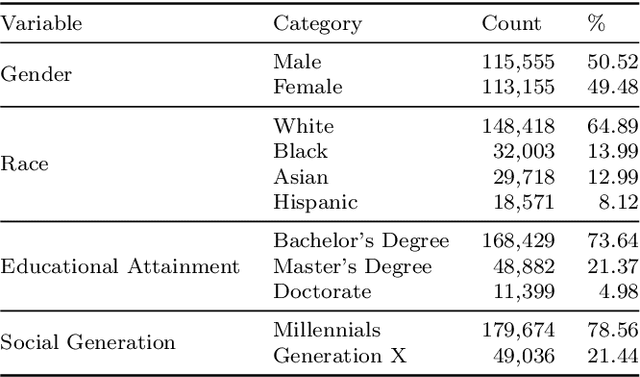


We present a large-scale analysis of career mobility of college-educated U.S. workers using online resume profiles to investigate how gender, race, and job change options are associated with upward mobility. This study addresses key research questions of how the job changes affect their upward career mobility, and how the outcomes of upward career mobility differ by gender and race. We address data challenges -- such as missing demographic attributes, missing wage data, and noisy occupation labels -- through various data processing and Artificial Intelligence (AI) methods. In particular, we develop a large language models (LLMs) based occupation classification method known as FewSOC that achieves accuracy significantly higher than the original occupation labels in the resume dataset. Analysis of 228,710 career trajectories reveals that intra-firm occupation change has been found to facilitate upward mobility most strongly, followed by inter-firm occupation change and inter-firm lateral move. Women and Black college graduates experience significantly lower returns from job changes than men and White peers. Multilevel sensitivity analyses confirm that these disparities are robust to cluster-level heterogeneity and reveal additional intersectional patterns.
StreamingVLM: Real-Time Understanding for Infinite Video Streams
Oct 10, 2025Vision-language models (VLMs) could power real-time assistants and autonomous agents, but they face a critical challenge: understanding near-infinite video streams without escalating latency and memory usage. Processing entire videos with full attention leads to quadratic computational costs and poor performance on long videos. Meanwhile, simple sliding window methods are also flawed, as they either break coherence or suffer from high latency due to redundant recomputation. In this paper, we introduce StreamingVLM, a model designed for real-time, stable understanding of infinite visual input. Our approach is a unified framework that aligns training with streaming inference. During inference, we maintain a compact KV cache by reusing states of attention sinks, a short window of recent vision tokens, and a long window of recent text tokens. This streaming ability is instilled via a simple supervised fine-tuning (SFT) strategy that applies full attention on short, overlapped video chunks, which effectively mimics the inference-time attention pattern without training on prohibitively long contexts. For evaluation, we build Inf-Streams-Eval, a new benchmark with videos averaging over two hours that requires dense, per-second alignment between frames and text. On Inf-Streams-Eval, StreamingVLM achieves a 66.18% win rate against GPT-4O mini and maintains stable, real-time performance at up to 8 FPS on a single NVIDIA H100. Notably, our SFT strategy also enhances general VQA abilities without any VQA-specific fine-tuning, improving performance on LongVideoBench by +4.30 and OVOBench Realtime by +5.96. Code is available at https://github.com/mit-han-lab/streaming-vlm.
Drawing Conclusions from Draws: Rethinking Preference Semantics in Arena-Style LLM Evaluation
Oct 02, 2025



In arena-style evaluation of large language models (LLMs), two LLMs respond to a user query, and the user chooses the winning response or deems the "battle" a draw, resulting in an adjustment to the ratings of both models. The prevailing approach for modeling these rating dynamics is to view battles as two-player game matches, as in chess, and apply the Elo rating system and its derivatives. In this paper, we critically examine this paradigm. Specifically, we question whether a draw genuinely means that the two models are equal and hence whether their ratings should be equalized. Instead, we conjecture that draws are more indicative of query difficulty: if the query is too easy, then both models are more likely to succeed equally. On three real-world arena datasets, we show that ignoring rating updates for draws yields a 1-3% relative increase in battle outcome prediction accuracy (which includes draws) for all four rating systems studied. Further analyses suggest that draws occur more for queries rated as very easy and those as highly objective, with risk ratios of 1.37 and 1.35, respectively. We recommend future rating systems to reconsider existing draw semantics and to account for query properties in rating updates.
LongLive: Real-time Interactive Long Video Generation
Sep 26, 2025We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
3D Aware Region Prompted Vision Language Model
Sep 16, 2025

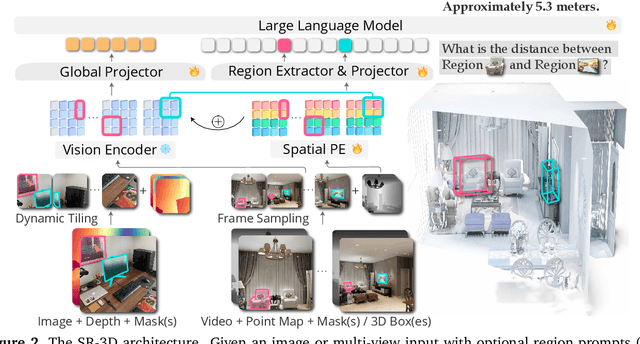

We present Spatial Region 3D (SR-3D) aware vision-language model that connects single-view 2D images and multi-view 3D data through a shared visual token space. SR-3D supports flexible region prompting, allowing users to annotate regions with bounding boxes, segmentation masks on any frame, or directly in 3D, without the need for exhaustive multi-frame labeling. We achieve this by enriching 2D visual features with 3D positional embeddings, which allows the 3D model to draw upon strong 2D priors for more accurate spatial reasoning across frames, even when objects of interest do not co-occur within the same view. Extensive experiments on both general 2D vision language and specialized 3D spatial benchmarks demonstrate that SR-3D achieves state-of-the-art performance, underscoring its effectiveness for unifying 2D and 3D representation space on scene understanding. Moreover, we observe applicability to in-the-wild videos without sensory 3D inputs or ground-truth 3D annotations, where SR-3D accurately infers spatial relationships and metric measurements.
\emph{FoQuS}: A Forgetting-Quality Coreset Selection Framework for Automatic Modulation Recognition
Sep 10, 2025Deep learning-based Automatic Modulation Recognition (AMR) model has made significant progress with the support of large-scale labeled data. However, when developing new models or performing hyperparameter tuning, the time and energy consumption associated with repeated training using massive amounts of data are often unbearable. To address the above challenges, we propose \emph{FoQuS}, which approximates the effect of full training by selecting a coreset from the original dataset, thereby significantly reducing training overhead. Specifically, \emph{FoQuS} records the prediction trajectory of each sample during full-dataset training and constructs three importance metrics based on training dynamics. Experiments show that \emph{FoQuS} can maintain high recognition accuracy and good cross-architecture generalization on multiple AMR datasets using only 1\%-30\% of the original data.
Amazon Nova AI Challenge -- Trusted AI: Advancing secure, AI-assisted software development
Aug 13, 2025AI systems for software development are rapidly gaining prominence, yet significant challenges remain in ensuring their safety. To address this, Amazon launched the Trusted AI track of the Amazon Nova AI Challenge, a global competition among 10 university teams to drive advances in secure AI. In the challenge, five teams focus on developing automated red teaming bots, while the other five create safe AI assistants. This challenge provides teams with a unique platform to evaluate automated red-teaming and safety alignment methods through head-to-head adversarial tournaments where red teams have multi-turn conversations with the competing AI coding assistants to test their safety alignment. Along with this, the challenge provides teams with a feed of high quality annotated data to fuel iterative improvement. Throughout the challenge, teams developed state-of-the-art techniques, introducing novel approaches in reasoning-based safety alignment, robust model guardrails, multi-turn jail-breaking, and efficient probing of large language models (LLMs). To support these efforts, the Amazon Nova AI Challenge team made substantial scientific and engineering investments, including building a custom baseline coding specialist model for the challenge from scratch, developing a tournament orchestration service, and creating an evaluation harness. This paper outlines the advancements made by university teams and the Amazon Nova AI Challenge team in addressing the safety challenges of AI for software development, highlighting this collaborative effort to raise the bar for AI safety.
MonoPartNeRF:Human Reconstruction from Monocular Video via Part-Based Neural Radiance Fields
Aug 12, 2025In recent years, Neural Radiance Fields (NeRF) have achieved remarkable progress in dynamic human reconstruction and rendering. Part-based rendering paradigms, guided by human segmentation, allow for flexible parameter allocation based on structural complexity, thereby enhancing representational efficiency. However, existing methods still struggle with complex pose variations, often producing unnatural transitions at part boundaries and failing to reconstruct occluded regions accurately in monocular settings. We propose MonoPartNeRF, a novel framework for monocular dynamic human rendering that ensures smooth transitions and robust occlusion recovery. First, we build a bidirectional deformation model that combines rigid and non-rigid transformations to establish a continuous, reversible mapping between observation and canonical spaces. Sampling points are projected into a parameterized surface-time space (u, v, t) to better capture non-rigid motion. A consistency loss further suppresses deformation-induced artifacts and discontinuities. We introduce a part-based pose embedding mechanism that decomposes global pose vectors into local joint embeddings based on body regions. This is combined with keyframe pose retrieval and interpolation, along three orthogonal directions, to guide pose-aware feature sampling. A learnable appearance code is integrated via attention to model dynamic texture changes effectively. Experiments on the ZJU-MoCap and MonoCap datasets demonstrate that our method significantly outperforms prior approaches under complex pose and occlusion conditions, achieving superior joint alignment, texture fidelity, and structural continuity.