 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyGround: Benchmarking Physical Reasoning in Generative World Models
May 11, 2026Generative world models are increasingly used for video generation, where learned simulators are expected to capture the physical rules that govern real-world dynamics. However, evaluating whether generated videos actually follow these rules remains challenging. Existing physics-focused video benchmarks have made important progress, but they still face three key challenges, including the coarse evaluation frameworks that hide law-specific failures, response biases and fatigue that undermine the validity of annotation judgments, and automated evaluators that are insufficiently physics-aware or difficult to audit. To address those challenges, we introduce PhyGround, a criteria-grounded benchmark for evaluating physical reasoning in video generation. The benchmark contains 250 curated prompts, each augmented with an expected physical outcome, and a taxonomy of 13 physical laws across solid-body mechanics, fluid dynamics, and optics. Each law is operationalized through observable sub-questions to enable per-law diagnostics. We evaluate eight modern video generation models through a large-scale, quality-controlled human study, grounded on social science lab experiment design. A total of 459 annotators provided 5,796 complete annotations and over 37.4K fine-grained labels; after quality control, the retained annotations exhibited high split-half model-ranking correlations (Spearman's rho > 0.90). To support reproducible automated evaluation, we release PhyJudge-9B, an open physics-specialized VLM judge. PhyJudge-9B achieves substantially lower aggregate relative bias than Gemini-3.1-Pro (3.3% vs. 16.6%). We release prompts, human annotations, model checkpoints, and evaluation code on the project page https://phyground.github.io/.
Grounded Token Initialization for New Vocabulary in LMs for Generative Recommendation
Apr 02, 2026Language models (LMs) are increasingly extended with new learnable vocabulary tokens for domain-specific tasks, such as Semantic-ID tokens in generative recommendation. The standard practice initializes these new tokens as the mean of existing vocabulary embeddings, then relies on supervised fine-tuning to learn their representations. We present a systematic analysis of this strategy: through spectral and geometric diagnostics, we show that mean initialization collapses all new tokens into a degenerate subspace, erasing inter-token distinctions that subsequent fine-tuning struggles to fully recover. These findings suggest that \emph{token initialization} is a key bottleneck when extending LMs with new vocabularies. Motivated by this diagnosis, we propose the \emph{Grounded Token Initialization Hypothesis}: linguistically grounding novel tokens in the pretrained embedding space before fine-tuning better enables the model to leverage its general-purpose knowledge for novel-token domains. We operationalize this hypothesis as GTI (Grounded Token Initialization), a lightweight grounding stage that, prior to fine-tuning, maps new tokens to distinct, semantically meaningful locations in the pretrained embedding space using only paired linguistic supervision. Despite its simplicity, GTI outperforms both mean initialization and existing auxiliary-task adaptation methods in the majority of evaluation settings across multiple generative recommendation benchmarks, including industry-scale and public datasets. Further analyses show that grounded embeddings produce richer inter-token structure that persists through fine-tuning, corroborating the hypothesis that initialization quality is a key bottleneck in vocabulary extension.
Demystifying When Pruning Works via Representation Hierarchies
Mar 25, 2026Network pruning, which removes less important parameters or architectures, is often expected to improve efficiency while preserving performance. However, this expectation does not consistently hold across language tasks: pruned models can perform well on non-generative tasks but frequently fail in generative settings. To understand this discrepancy, we analyze network pruning from a representation-hierarchy perspective, decomposing the internal computation of language models into three sequential spaces: embedding (hidden representations), logit (pre-softmax outputs), and probability (post-softmax distributions). We find that representations in the embedding and logit spaces are largely robust to pruning-induced perturbations. However, the nonlinear transformation from logits to probabilities amplifies these deviations, which accumulate across time steps and lead to substantial degradation during generation. In contrast, the stability of the categorical-token probability subspace, together with the robustness of the embedding space, supports the effectiveness of pruning for non-generative tasks such as retrieval and multiple-choice selection. Our analysis disentangles the effects of pruning across tasks and provides practical guidance for its application. Code is available at https://github.com/CASE-Lab-UMD/Pruning-on-Representations
ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
Mar 23, 2026Recent progress in latent world models (e.g., V-JEPA2) has shown promising capability in forecasting future world states from video observations. Nevertheless, dense prediction from a short observation window limits temporal context and can bias predictors toward local, low-level extrapolation, making it difficult to capture long-horizon semantics and reducing downstream utility. Vision--language models (VLMs), in contrast, provide strong semantic grounding and general knowledge by reasoning over uniformly sampled frames, but they are not ideal as standalone dense predictors due to compute-driven sparse sampling, a language-output bottleneck that compresses fine-grained interaction states into text-oriented representations, and a data-regime mismatch when adapting to small action-conditioned datasets. We propose a VLM-guided JEPA-style latent world modeling framework that combines dense-frame dynamics modeling with long-horizon semantic guidance via a dual-temporal pathway: a dense JEPA branch for fine-grained motion and interaction cues, and a uniformly sampled VLM \emph{thinker} branch with a larger temporal stride for knowledge-rich guidance. To transfer the VLM's progressive reasoning signals effectively, we introduce a hierarchical pyramid representation extraction module that aggregates multi-layer VLM representations into guidance features compatible with latent prediction. Experiments on hand-manipulation trajectory prediction show that our method outperforms both a strong VLM-only baseline and a JEPA-predictor baseline, and yields more robust long-horizon rollout behavior.
LinkedOut: Linking World Knowledge Representation Out of Video LLM for Next-Generation Video Recommendation
Dec 18, 2025Video Large Language Models (VLLMs) unlock world-knowledge-aware video understanding through pretraining on internet-scale data and have already shown promise on tasks such as movie analysis and video question answering. However, deploying VLLMs for downstream tasks such as video recommendation remains challenging, since real systems require multi-video inputs, lightweight backbones, low-latency sequential inference, and rapid response. In practice, (1) decode-only generation yields high latency for sequential inference, (2) typical interfaces do not support multi-video inputs, and (3) constraining outputs to language discards fine-grained visual details that matter for downstream vision tasks. We argue that these limitations stem from the absence of a representation that preserves pixel-level detail while leveraging world knowledge. We present LinkedOut, a representation that extracts VLLM world knowledge directly from video to enable fast inference, supports multi-video histories, and removes the language bottleneck. LinkedOut extracts semantically grounded, knowledge-aware tokens from raw frames using VLLMs, guided by promptable queries and optional auxiliary modalities. We introduce a cross-layer knowledge fusion MoE that selects the appropriate level of abstraction from the rich VLLM features, enabling personalized, interpretable, and low-latency recommendation. To our knowledge, LinkedOut is the first VLLM-based video recommendation method that operates on raw frames without handcrafted labels, achieving state-of-the-art results on standard benchmarks. Interpretability studies and ablations confirm the benefits of layer diversity and layer-wise fusion, pointing to a practical path that fully leverages VLLM world-knowledge priors and visual reasoning for downstream vision tasks such as recommendation.
Dense Video Understanding with Gated Residual Tokenization
Sep 18, 2025High temporal resolution is essential for capturing fine-grained details in video understanding. However, current video large language models (VLLMs) and benchmarks mostly rely on low-frame-rate sampling, such as uniform sampling or keyframe selection, discarding dense temporal information. This compromise avoids the high cost of tokenizing every frame, which otherwise leads to redundant computation and linear token growth as video length increases. While this trade-off works for slowly changing content, it fails for tasks like lecture comprehension, where information appears in nearly every frame and requires precise temporal alignment. To address this gap, we introduce Dense Video Understanding (DVU), which enables high-FPS video comprehension by reducing both tokenization time and token overhead. Existing benchmarks are also limited, as their QA pairs focus on coarse content changes. We therefore propose DIVE (Dense Information Video Evaluation), the first benchmark designed for dense temporal reasoning. To make DVU practical, we present Gated Residual Tokenization (GRT), a two-stage framework: (1) Motion-Compensated Inter-Gated Tokenization uses pixel-level motion estimation to skip static regions during tokenization, achieving sub-linear growth in token count and compute. (2) Semantic-Scene Intra-Tokenization Merging fuses tokens across static regions within a scene, further reducing redundancy while preserving dynamic semantics. Experiments on DIVE show that GRT outperforms larger VLLM baselines and scales positively with FPS. These results highlight the importance of dense temporal information and demonstrate that GRT enables efficient, scalable high-FPS video understanding.
Out-of-Sight Trajectories: Tracking, Fusion, and Prediction
Sep 18, 2025Trajectory prediction is a critical task in computer vision and autonomous systems, playing a key role in autonomous driving, robotics, surveillance, and virtual reality. Existing methods often rely on complete and noise-free observational data, overlooking the challenges associated with out-of-sight objects and the inherent noise in sensor data caused by limited camera coverage, obstructions, and the absence of ground truth for denoised trajectories. These limitations pose safety risks and hinder reliable prediction in real-world scenarios. In this extended work, we present advancements in Out-of-Sight Trajectory (OST), a novel task that predicts the noise-free visual trajectories of out-of-sight objects using noisy sensor data. Building on our previous research, we broaden the scope of Out-of-Sight Trajectory Prediction (OOSTraj) to include pedestrians and vehicles, extending its applicability to autonomous driving, robotics, surveillance, and virtual reality. Our enhanced Vision-Positioning Denoising Module leverages camera calibration to establish a vision-positioning mapping, addressing the lack of visual references, while effectively denoising noisy sensor data in an unsupervised manner. Through extensive evaluations on the Vi-Fi and JRDB datasets, our approach achieves state-of-the-art performance in both trajectory denoising and prediction, significantly surpassing previous baselines. Additionally, we introduce comparisons with traditional denoising methods, such as Kalman filtering, and adapt recent trajectory prediction models to our task, providing a comprehensive benchmark. This work represents the first initiative to integrate vision-positioning projection for denoising noisy sensor trajectories of out-of-sight agents, paving the way for future advances. The code and preprocessed datasets are available at github.com/Hai-chao-Zhang/OST
Learning Multi-Stage Pick-and-Place with a Legged Mobile Manipulator
Sep 04, 2025Quadruped-based mobile manipulation presents significant challenges in robotics due to the diversity of required skills, the extended task horizon, and partial observability. After presenting a multi-stage pick-and-place task as a succinct yet sufficiently rich setup that captures key desiderata for quadruped-based mobile manipulation, we propose an approach that can train a visuo-motor policy entirely in simulation, and achieve nearly 80\% success in the real world. The policy efficiently performs search, approach, grasp, transport, and drop into actions, with emerged behaviors such as re-grasping and task chaining. We conduct an extensive set of real-world experiments with ablation studies highlighting key techniques for efficient training and effective sim-to-real transfer. Additional experiments demonstrate deployment across a variety of indoor and outdoor environments. Demo videos and additional resources are available on the project page: https://horizonrobotics.github.io/gail/SLIM.
Uncertainty-Aware Semantic Decoding for LLM-Based Sequential Recommendation
Aug 10, 2025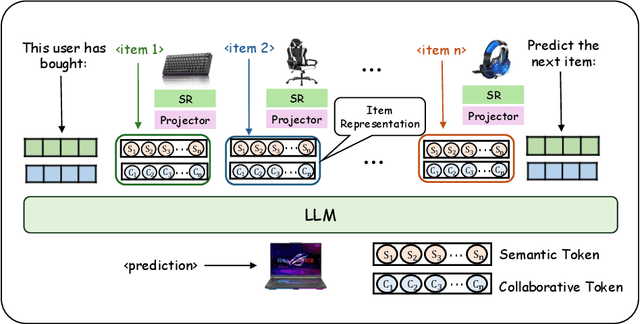
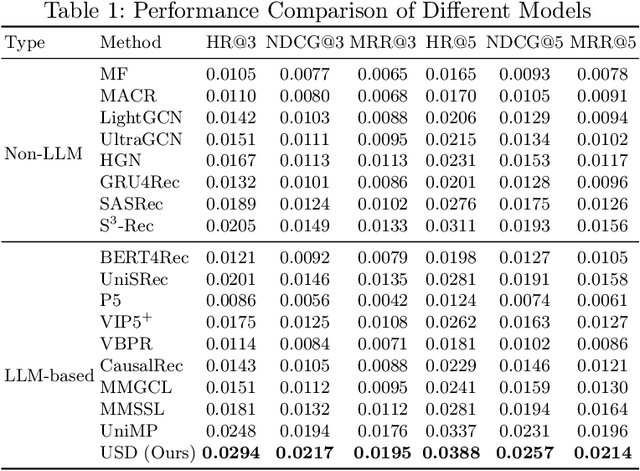
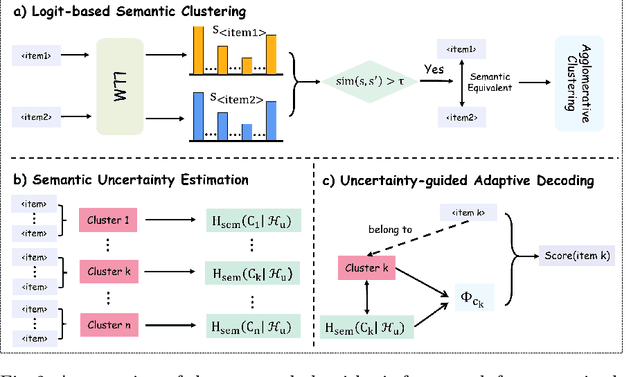

Large language models have been widely applied to sequential recommendation tasks, yet during inference, they continue to rely on decoding strategies developed for natural language processing. This creates a mismatch between text-generation objectives and recommendation next item selection objectives. This paper addresses this limitation by proposing an Uncertainty-aware Semantic Decoding (USD) framework that combines logit-based clustering with adaptive scoring to improve next-item predictions. Our approach clusters items with similar logit vectors into semantic equivalence groups, then redistributes probability mass within these clusters and computes entropy across them to control item scoring and sampling temperature during recommendation inference. Experiments on Amazon Product datasets (six domains) gains of 18.5\% in HR@3, 11.9\% in NDCG@3, and 10.8\% in MRR@3 compared to state-of-the-art baselines. Hyperparameter analysis confirms the optimal parameters among various settings, and experiments on H\&M, and Netflix datasets indicate that the framework can adapt to differing recommendation domains. The experimental results confirm that integrating semantic clustering and uncertainty assessment yields more reliable and accurate recommendations.
Robot Policy Learning with Temporal Optimal Transport Reward
Oct 29, 2024



Reward specification is one of the most tricky problems in Reinforcement Learning, which usually requires tedious hand engineering in practice. One promising approach to tackle this challenge is to adopt existing expert video demonstrations for policy learning. Some recent work investigates how to learn robot policies from only a single/few expert video demonstrations. For example, reward labeling via Optimal Transport (OT) has been shown to be an effective strategy to generate a proxy reward by measuring the alignment between the robot trajectory and the expert demonstrations. However, previous work mostly overlooks that the OT reward is invariant to temporal order information, which could bring extra noise to the reward signal. To address this issue, in this paper, we introduce the Temporal Optimal Transport (TemporalOT) reward to incorporate temporal order information for learning a more accurate OT-based proxy reward. Extensive experiments on the Meta-world benchmark tasks validate the efficacy of the proposed method. Code is available at: https://github.com/fuyw/TemporalOT