 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6.7ms on Mobile with over 78% ImageNet Accuracy: Unified Network Pruning and Architecture Search for Beyond Real-Time Mobile Acceleration
Dec 01, 2020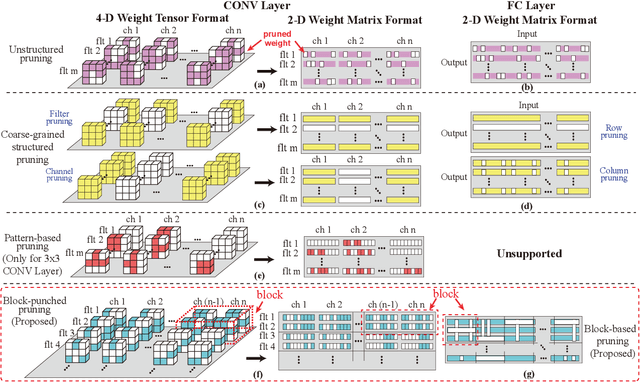
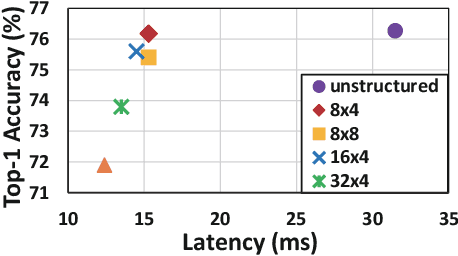
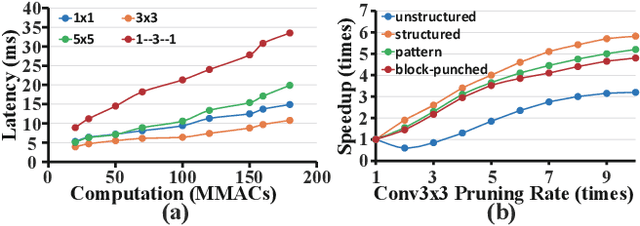
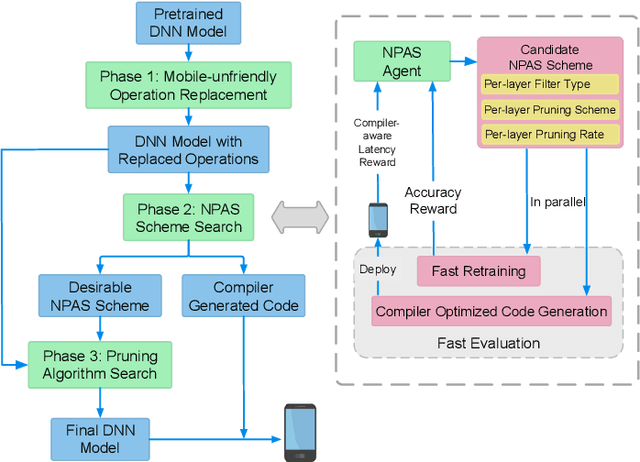
With the increasing demand to efficiently deploy DNNs on mobile edge devices, it becomes much more important to reduce unnecessary computation and increase the execution speed. Prior methods towards this goal, including model compression and network architecture search (NAS), are largely performed independently and do not fully consider compiler-level optimizations which is a must-do for mobile acceleration. In this work, we first propose (i) a general category of fine-grained structured pruning applicable to various DNN layers, and (ii) a comprehensive, compiler automatic code generation framework supporting different DNNs and different pruning schemes, which bridge the gap of model compression and NAS. We further propose NPAS, a compiler-aware unified network pruning, and architecture search. To deal with large search space, we propose a meta-modeling procedure based on reinforcement learning with fast evaluation and Bayesian optimization, ensuring the total number of training epochs comparable with representative NAS frameworks. Our framework achieves 6.7ms, 5.9ms, 3.9ms ImageNet inference times with 78.2%, 75% (MobileNet-V3 level), and 71% (MobileNet-V2 level) Top-1 accuracy respectively on an off-the-shelf mobile phone, consistently outperforming prior work.
An Efficient End-to-End Deep Learning Training Framework via Fine-Grained Pattern-Based Pruning
Nov 20, 2020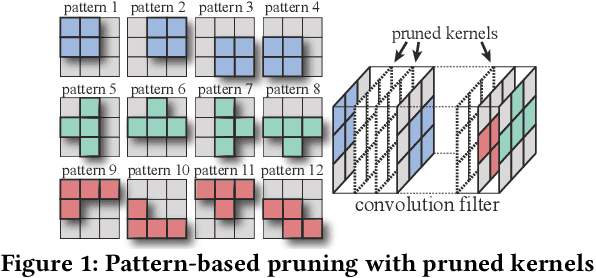
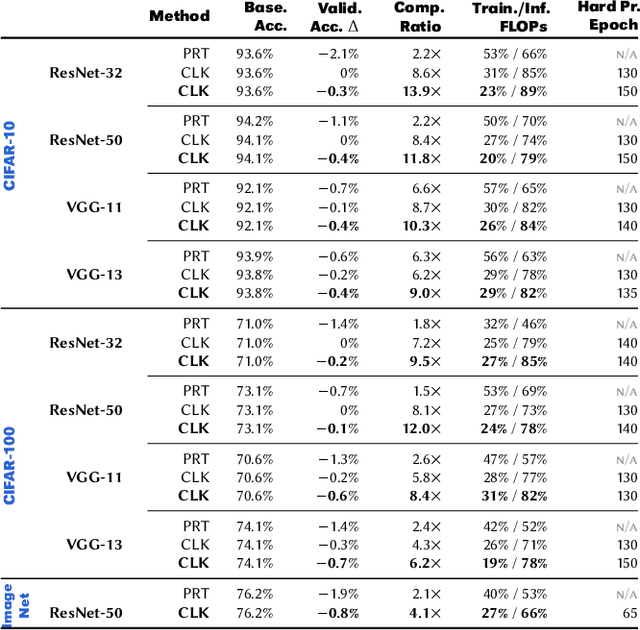
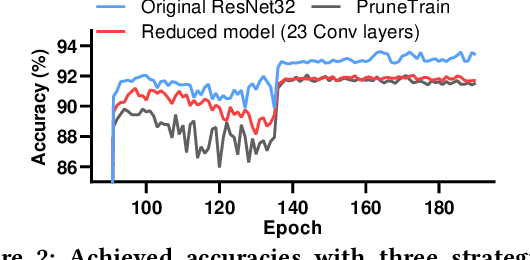
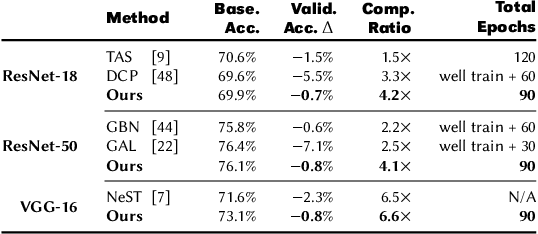
Convolutional neural networks (CNNs) are becoming increasingly deeper, wider, and non-linear because of the growing demand on prediction accuracy and analysis quality. The wide and deep CNNs, however, require a large amount of computing resources and processing time. Many previous works have studied model pruning to improve inference performance, but little work has been done for effectively reducing training cost. In this paper, we propose ClickTrain: an efficient and accurate end-to-end training and pruning framework for CNNs. Different from the existing pruning-during-training work, ClickTrain provides higher model accuracy and compression ratio via fine-grained architecture-preserving pruning. By leveraging pattern-based pruning with our proposed novel accurate weight importance estimation, dynamic pattern generation and selection, and compiler-assisted computation optimizations, ClickTrain generates highly accurate and fast pruned CNN models for direct deployment without any time overhead, compared with the baseline training. ClickTrain also reduces the end-to-end time cost of the state-of-the-art pruning-after-training methods by up to about 67% with comparable accuracy and compression ratio. Moreover, compared with the state-of-the-art pruning-during-training approach, ClickTrain reduces the accuracy drop by up to 2.1% and improves the compression ratio by up to 2.2X on the tested datasets, under similar limited training time.
DAIS: Automatic Channel Pruning via Differentiable Annealing Indicator Search
Nov 04, 2020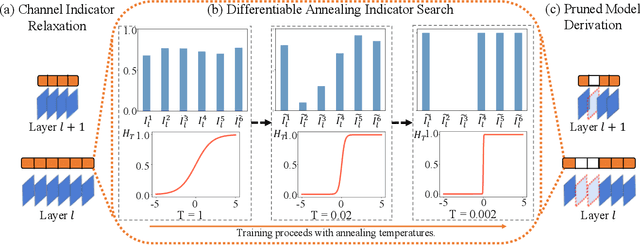
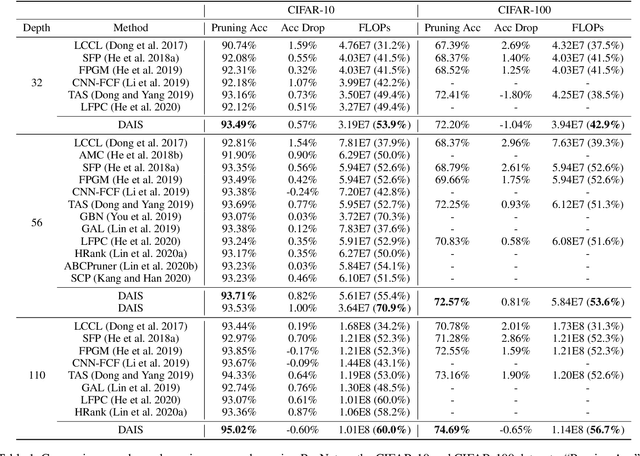
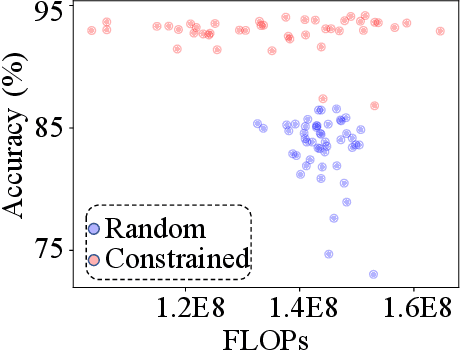
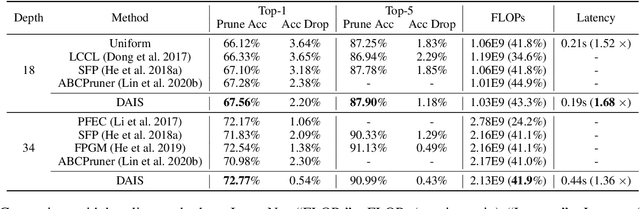
The convolutional neural network has achieved great success in fulfilling computer vision tasks despite large computation overhead against efficient deployment. Structured (channel) pruning is usually applied to reduce the model redundancy while preserving the network structure, such that the pruned network can be easily deployed in practice. However, existing structured pruning methods require hand-crafted rules which may lead to tremendous pruning space. In this paper, we introduce Differentiable Annealing Indicator Search (DAIS) that leverages the strength of neural architecture search in the channel pruning and automatically searches for the effective pruned model with given constraints on computation overhead. Specifically, DAIS relaxes the binarized channel indicators to be continuous and then jointly learns both indicators and model parameters via bi-level optimization. To bridge the non-negligible discrepancy between the continuous model and the target binarized model, DAIS proposes an annealing-based procedure to steer the indicator convergence towards binarized states. Moreover, DAIS designs various regularizations based on a priori structural knowledge to control the pruning sparsity and to improve model performance. Experimental results show that DAIS outperforms state-of-the-art pruning methods on CIFAR-10, CIFAR-100, and ImageNet.
Simultaneous Relevance and Diversity: A New Recommendation Inference Approach
Sep 27, 2020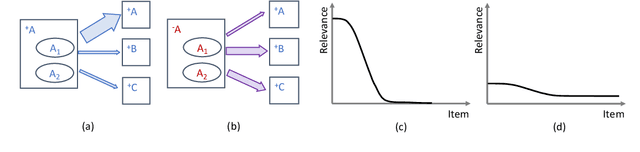
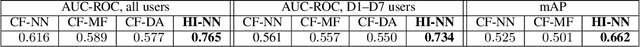
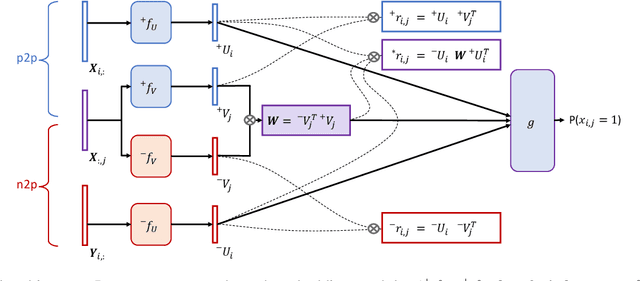
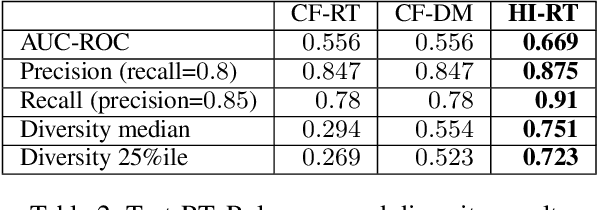
Relevance and diversity are both important to the success of recommender systems, as they help users to discover from a large pool of items a compact set of candidates that are not only interesting but exploratory as well. The challenge is that relevance and diversity usually act as two competing objectives in conventional recommender systems, which necessities the classic trade-off between exploitation and exploration. Traditionally, higher diversity often means sacrifice on relevance and vice versa. We propose a new approach, heterogeneous inference, which extends the general collaborative filtering (CF) by introducing a new way of CF inference, negative-to-positive. Heterogeneous inference achieves divergent relevance, where relevance and diversity support each other as two collaborating objectives in one recommendation model, and where recommendation diversity is an inherent outcome of the relevance inference process. Benefiting from its succinctness and flexibility, our approach is applicable to a wide range of recommendation scenarios/use-cases at various sophistication levels. Our analysis and experiments on public datasets and real-world production data show that our approach outperforms existing methods on relevance and diversity simultaneously.
MSP: An FPGA-Specific Mixed-Scheme, Multi-Precision Deep Neural Network Quantization Framework
Sep 16, 2020
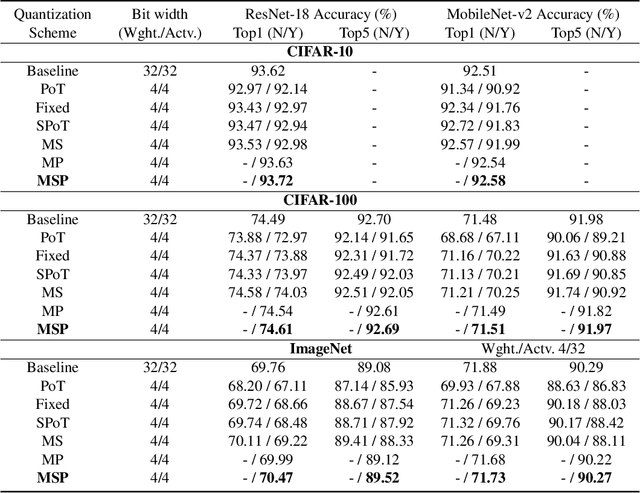
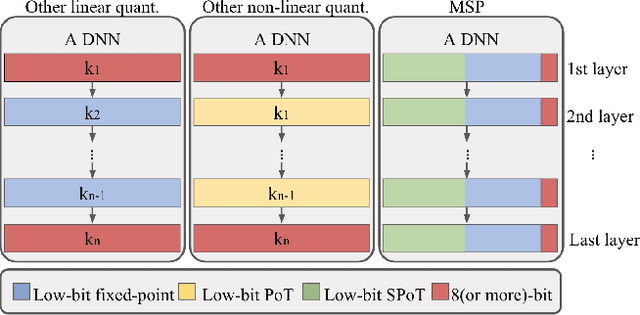
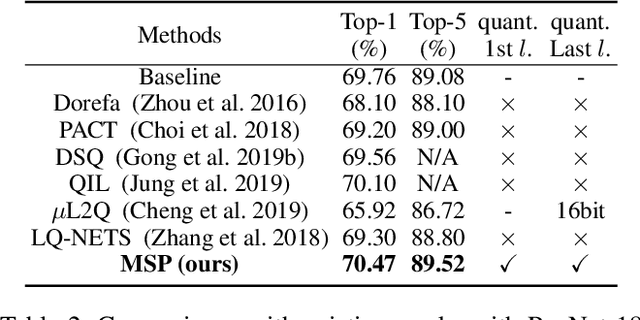
With the tremendous success of deep learning, there exists imminent need to deploy deep learning models onto edge devices. To tackle the limited computing and storage resources in edge devices, model compression techniques have been widely used to trim deep neural network (DNN) models for on-device inference execution. This paper targets the commonly used FPGA (field programmable gate array) devices as the hardware platforms for DNN edge computing. We focus on the DNN quantization as the main model compression technique, since DNN quantization has been of great importance for the implementations of DNN models on the hardware platforms. The novelty of this work comes in twofold: (i) We propose a mixed-scheme DNN quantization method that incorporates both the linear and non-linear number systems for quantization, with the aim to boost the utilization of the heterogeneous computing resources, i.e., LUTs (look up tables) and DSPs (digital signal processors) on an FPGA. Note that all the existing (single-scheme) quantization methods can only utilize one type of resources (either LUTs or DSPs for the MAC (multiply-accumulate) operations in deep learning computations. (ii) We use a quantization method that supports multiple precisions along the intra-layer dimension, while the existing quantization methods apply multi-precision quantization along the inter-layer dimension. The intra-layer multi-precision method can uniform the hardware configurations for different layers to reduce computation overhead and at the same time preserve the model accuracy as the inter-layer approach.
Achieving Real-Time Execution of Transformer-based Large-scale Models on Mobile with Compiler-aware Neural Architecture Optimization
Sep 15, 2020
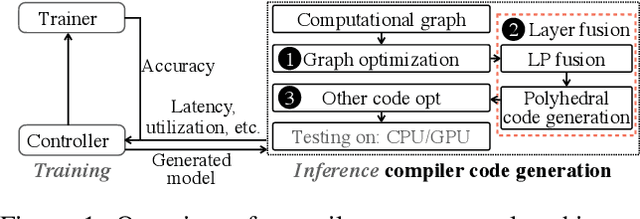
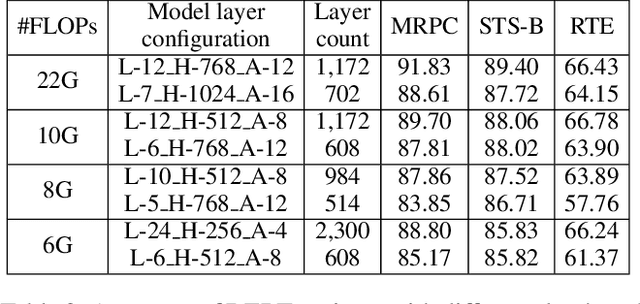
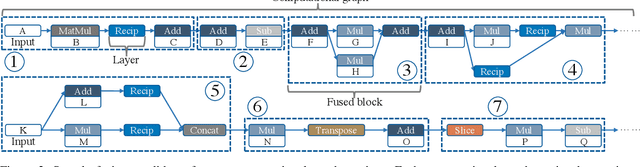
Pre-trained large-scale language models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. However, the limited weight storage and computational speed on hardware platforms have impeded the popularity of pre-trained models, especially in the era of edge computing. In this paper, we seek to find the best model structure of BERT for a given computation size to match specific devices. We propose the first compiler-aware neural architecture optimization framework (called CANAO). CANAO can guarantee the identified model to meet both resource and real-time specifications of mobile devices, thus achieving real-time execution of large transformer-based models like BERT variants. We evaluate our model on several NLP tasks, achieving competitive results on well-known benchmarks with lower latency on mobile devices. Specifically, our model is 5.2x faster on CPU and 4.1x faster on GPU with 0.5-2% accuracy loss compared with BERT-base. Our overall framework achieves up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss.
YOLObile: Real-Time Object Detection on Mobile Devices via Compression-Compilation Co-Design
Sep 12, 2020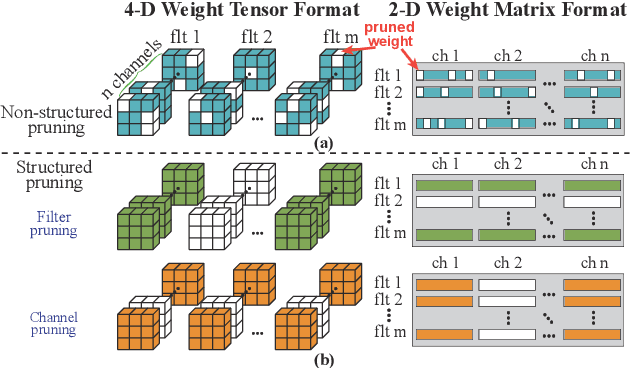
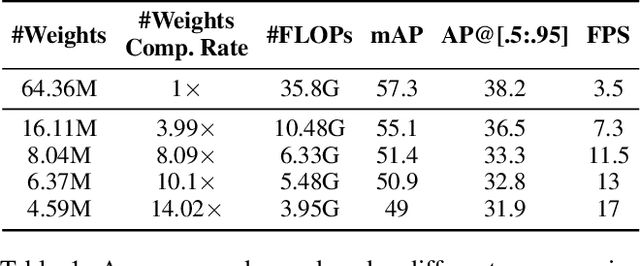
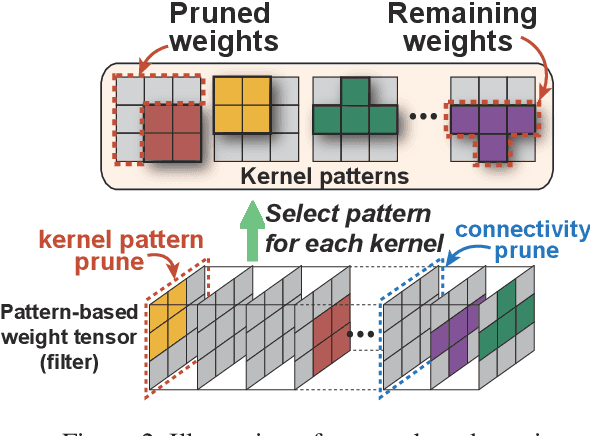
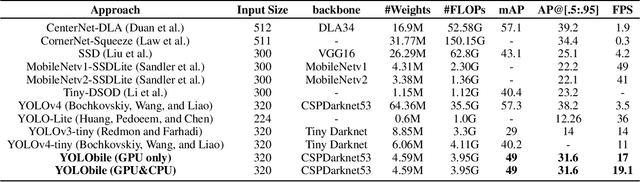
The rapid development and wide utilization of object detection techniques have aroused attention on both accuracy and speed of object detectors. However, the current state-of-the-art object detection works are either accuracy-oriented using a large model but leading to high latency or speed-oriented using a lightweight model but sacrificing accuracy. In this work, we propose YOLObile framework, a real-time object detection on mobile devices via compression-compilation co-design. A novel block-punched pruning scheme is proposed for any kernel size. To improve computational efficiency on mobile devices, a GPU-CPU collaborative scheme is adopted along with advanced compiler-assisted optimizations. Experimental results indicate that our pruning scheme achieves 14$\times$ compression rate of YOLOv4 with 49.0 mAP. Under our YOLObile framework, we achieve 17 FPS inference speed using GPU on Samsung Galaxy S20. By incorporating our proposed GPU-CPU collaborative scheme, the inference speed is increased to 19.1 FPS, and outperforms the original YOLOv4 by 5$\times$ speedup.
ESMFL: Efficient and Secure Models for Federated Learning
Sep 03, 2020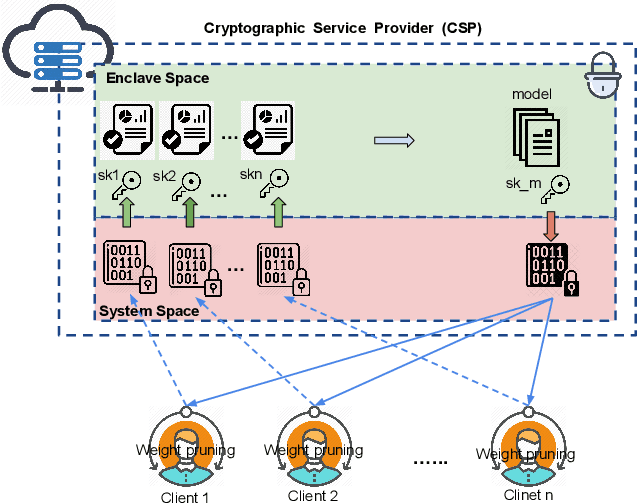
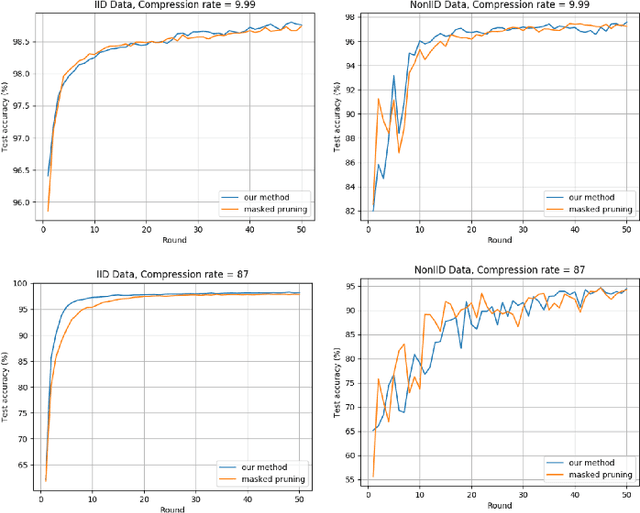
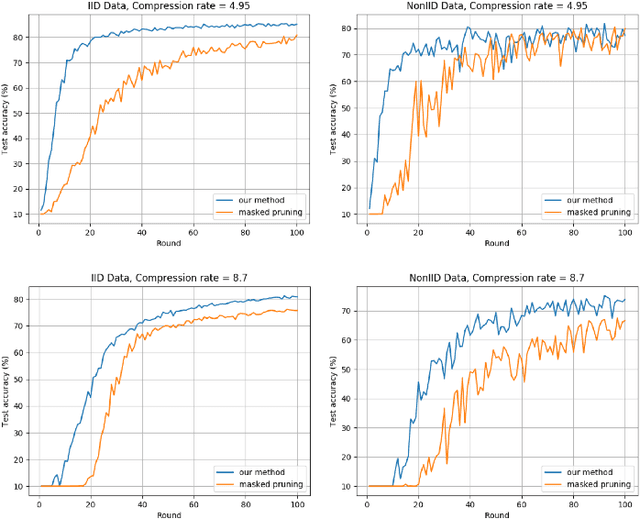

Deep Neural Networks are widely applied to various domains. The successful deployment of these applications is everywhere and it depends on the availability of big data. However, massive data collection required for deep neural network reveals the potential privacy issues and also consumes large mounts of communication bandwidth. To address this problem, we propose a privacy-preserving method for the federated learning distributed system, operated on Intel Software Guard Extensions, a set of instructions that increases the security of application code and data. Meanwhile, the encrypted models make the transmission overhead larger. Hence, we reduce the commutation cost by sparsification and achieve reasonable accuracy with different model architectures. Experimental results under our privacy-preserving framework show that, for LeNet-5, we obtain 98.78% accuracy on IID data and 97.60% accuracy on Non-IID data with 34.85% communication saving, and 1.8X total elapsed time acceleration. For MobileNetV2, we obtain 85.40% accuracy on IID data and 81.66% accuracy on Non-IID data with 15.85% communication saving, and 1.2X total elapsed time acceleration.
AntiDote: Attention-based Dynamic Optimization for Neural Network Runtime Efficiency
Aug 14, 2020



Convolutional Neural Networks (CNNs) achieved great cognitive performance at the expense of considerable computation load. To relieve the computation load, many optimization works are developed to reduce the model redundancy by identifying and removing insignificant model components, such as weight sparsity and filter pruning. However, these works only evaluate model components' static significance with internal parameter information, ignoring their dynamic interaction with external inputs. With per-input feature activation, the model component significance can dynamically change, and thus the static methods can only achieve sub-optimal results. Therefore, we propose a dynamic CNN optimization framework in this work. Based on the neural network attention mechanism, we propose a comprehensive dynamic optimization framework including (1) testing-phase channel and column feature map pruning, as well as (2) training-phase optimization by targeted dropout. Such a dynamic optimization framework has several benefits: (1) First, it can accurately identify and aggressively remove per-input feature redundancy with considering the model-input interaction; (2) Meanwhile, it can maximally remove the feature map redundancy in various dimensions thanks to the multi-dimension flexibility; (3) The training-testing co-optimization favors the dynamic pruning and helps maintain the model accuracy even with very high feature pruning ratio. Extensive experiments show that our method could bring 37.4% to 54.5% FLOPs reduction with negligible accuracy drop on various of test networks.
One for Many: Transfer Learning for Building HVAC Control
Aug 09, 2020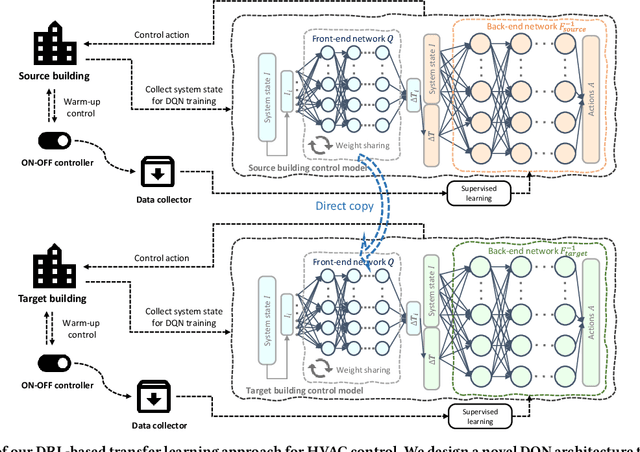
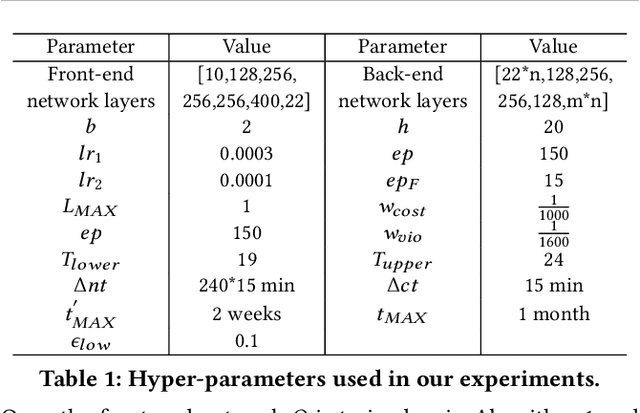
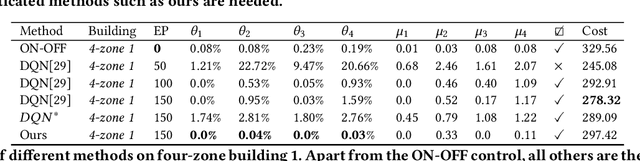
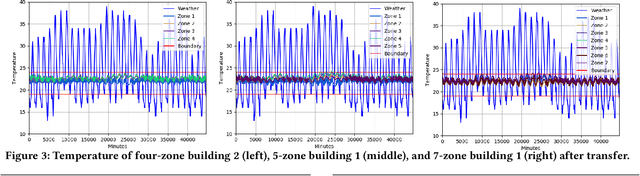
The design of building heating, ventilation, and air conditioning (HVAC) system is critically important, as it accounts for around half of building energy consumption and directly affects occupant comfort, productivity, and health. Traditional HVAC control methods are typically based on creating explicit physical models for building thermal dynamics, which often require significant effort to develop and are difficult to achieve sufficient accuracy and efficiency for runtime building control and scalability for field implementations. Recently, deep reinforcement learning (DRL) has emerged as a promising data-driven method that provides good control performance without analyzing physical models at runtime. However, a major challenge to DRL (and many other data-driven learning methods) is the long training time it takes to reach the desired performance. In this work, we present a novel transfer learning based approach to overcome this challenge. Our approach can effectively transfer a DRL-based HVAC controller trained for the source building to a controller for the target building with minimal effort and improved performance, by decomposing the design of neural network controller into a transferable front-end network that captures building-agnostic behavior and a back-end network that can be efficiently trained for each specific building. We conducted experiments on a variety of transfer scenarios between buildings with different sizes, numbers of thermal zones, materials and layouts, air conditioner types, and ambient weather conditions. The experimental results demonstrated the effectiveness of our approach in significantly reducing the training time, energy cost, and temperature violations.