 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBernini: Latent Semantic Planning for Video Diffusion
May 21, 2026Multimodal large language models (MLLMs) and diffusion models have each reached remarkable maturity: MLLMs excel at reasoning over heterogeneous multimodal inputs with strong semantic grounding, while diffusion models synthesize images and videos with photorealistic fidelity. We argue that these two families can be unified through a simple division of labor: MLLMs perform semantic planning, while diffusion models render pixels from high-level semantic guidance and low-level visual features. Building on this idea, we propose Bernini, a unified framework for video generation and editing. An MLLM-based planner predicts the target semantic representation directly in the ViT embedding space, and a DiT-based renderer synthesizes pixels conditioned on this plan, augmented by text features and, for editing, source VAE features for detail preservation. Because semantics serve as the interface, the planner and renderer can be trained separately and only lightly co-trained, preserving the pretrained strengths of both components while keeping training efficient. To better handle multiple visual inputs, we introduce Segment-Aware 3D Rotary Positional Embedding (SA-3D RoPE), and further incorporate chain-of-thought reasoning in the planner to better transfer understanding into generation. Bernini achieves state-of-the-art performance across a wide range of video generation and editing benchmarks, with the MLLM's pretrained understanding translating into strong generalization on challenging editing tasks.
Remote Sensing Image Segmentation Using Vision Mamba and Multi-Scale Multi-Frequency Feature Fusion
Oct 08, 2024



As remote sensing imaging technology continues to advance and evolve, processing high-resolution and diversified satellite imagery to improve segmentation accuracy and enhance interpretation efficiency emerg as a pivotal area of investigation within the realm of remote sensing. Although segmentation algorithms based on CNNs and Transformers achieve significant progress in performance, balancing segmentation accuracy and computational complexity remains challenging, limiting their wide application in practical tasks. To address this, this paper introduces state space model (SSM) and proposes a novel hybrid semantic segmentation network based on vision Mamba (CVMH-UNet). This method designs a cross-scanning visual state space block (CVSSBlock) that uses cross 2D scanning (CS2D) to fully capture global information from multiple directions, while by incorporating convolutional neural network branches to overcome the constraints of Vision Mamba (VMamba) in acquiring local information, this approach facilitates a comprehensive analysis of both global and local features. Furthermore, to address the issue of limited discriminative power and the difficulty in achieving detailed fusion with direct skip connections, a multi-frequency multi-scale feature fusion block (MFMSBlock) is designed. This module introduces multi-frequency information through 2D discrete cosine transform (2D DCT) to enhance information utilization and provides additional scale local detail information through point-wise convolution branches. Finally, it aggregates multi-scale information along the channel dimension, achieving refined feature fusion. Findings from experiments conducted on renowned datasets of remote sensing imagery demonstrate that proposed CVMH-UNet achieves superior segmentation performance while maintaining low computational complexity, outperforming surpassing current leading-edge segmentation algorithms.
A Collaborative PIM Computing Optimization Framework for Multi-Tenant DNN
Aug 09, 2024



Modern Artificial Intelligence (AI) applications are increasingly utilizing multi-tenant deep neural networks (DNNs), which lead to a significant rise in computing complexity and the need for computing parallelism. ReRAM-based processing-in-memory (PIM) computing, with its high density and low power consumption characteristics, holds promising potential for supporting the deployment of multi-tenant DNNs. However, direct deployment of complex multi-tenant DNNs on exsiting ReRAM-based PIM designs poses challenges. Resource contention among different tenants can result in sever under-utilization of on-chip computing resources. Moreover, area-intensive operators and computation-intensive operators require excessively large on-chip areas and long processing times, leading to high overall latency during parallel computing. To address these challenges, we propose a novel ReRAM-based in-memory computing framework that enables efficient deployment of multi-tenant DNNs on ReRAM-based PIM designs. Our approach tackles the resource contention problems by iteratively partitioning the PIM hardware at tenant level. In addition, we construct a fine-grained reconstructed processing pipeline at the operator level to handle area-intensive operators. Compared to the direct deployments on traditional ReRAM-based PIM designs, our proposed PIM computing framework achieves significant improvements in speed (ranges from 1.75x to 60.43x) and energy(up to 1.89x).
EdgeShield: A Universal and Efficient Edge Computing Framework for Robust AI
Aug 08, 2024



The increasing prevalence of adversarial attacks on Artificial Intelligence (AI) systems has created a need for innovative security measures. However, the current methods of defending against these attacks often come with a high computing cost and require back-end processing, making real-time defense challenging. Fortunately, there have been remarkable advancements in edge-computing, which make it easier to deploy neural networks on edge devices. Building upon these advancements, we propose an edge framework design to enable universal and efficient detection of adversarial attacks. This framework incorporates an attention-based adversarial detection methodology and a lightweight detection network formation, making it suitable for a wide range of neural networks and can be deployed on edge devices. To assess the effectiveness of our proposed framework, we conducted evaluations on five neural networks. The results indicate an impressive 97.43% F-score can be achieved, demonstrating the framework's proficiency in detecting adversarial attacks. Moreover, our proposed framework also exhibits significantly reduced computing complexity and cost in comparison to previous detection methods. This aspect is particularly beneficial as it ensures that the defense mechanism can be efficiently implemented in real-time on-edge devices.
DexGrasp-Diffusion: Diffusion-based Unified Functional Grasp Synthesis Pipeline for Multi-Dexterous Robotic Hands
Jul 13, 2024



The versatility and adaptability of human grasping catalyze advancing dexterous robotic manipulation. While significant strides have been made in dexterous grasp generation, current research endeavors pivot towards optimizing object manipulation while ensuring functional integrity, emphasizing the synthesis of functional grasps following desired affordance instructions. This paper addresses the challenge of synthesizing functional grasps tailored to diverse dexterous robotic hands by proposing DexGrasp-Diffusion, an end-to-end modularized diffusion-based pipeline. DexGrasp-Diffusion integrates MultiHandDiffuser, a novel unified data-driven diffusion model for multi-dexterous hands grasp estimation, with DexDiscriminator, which employs a Physics Discriminator and a Functional Discriminator with open-vocabulary setting to filter physically plausible functional grasps based on object affordances. The experimental evaluation conducted on the MultiDex dataset provides substantiating evidence supporting the superior performance of MultiHandDiffuser over the baseline model in terms of success rate, grasp diversity, and collision depth. Moreover, we demonstrate the capacity of DexGrasp-Diffusion to reliably generate functional grasps for household objects aligned with specific affordance instructions.
Learning-based Block-wise Planar Channel Estimation for Time-Varying MIMO OFDM
May 18, 2024



In this paper, we propose a learning-based block-wise planar channel estimator (LBPCE) with high accuracy and low complexity to estimate the time-varying frequency-selective channel of a multiple-input multiple-output (MIMO) orthogonal frequency-division multiplexing (OFDM) system. First, we establish a block-wise planar channel model (BPCM) to characterize the correlation of the channel across subcarriers and OFDM symbols. Specifically, adjacent subcarriers and OFDM symbols are divided into several sub-blocks, and an affine function (i.e., a plane) with only three variables (namely, mean, time-domain slope, and frequency-domain slope) is used to approximate the channel in each sub-block, which significantly reduces the number of variables to be determined in channel estimation. Second, we design a 3D dilated residual convolutional network (3D-DRCN) that leverages the time-frequency-space-domain correlations of the channel to further improve the channel estimates of each user. Numerical results demonstrate that the proposed significantly outperforms the state-of-the-art estimators and maintains a relatively low computational complexity.
QuadraNet: Improving High-Order Neural Interaction Efficiency with Hardware-Aware Quadratic Neural Networks
Nov 29, 2023Recent progress in computer vision-oriented neural network designs is mostly driven by capturing high-order neural interactions among inputs and features. And there emerged a variety of approaches to accomplish this, such as Transformers and its variants. However, these interactions generate a large amount of intermediate state and/or strong data dependency, leading to considerable memory consumption and computing cost, and therefore compromising the overall runtime performance. To address this challenge, we rethink the high-order interactive neural network design with a quadratic computing approach. Specifically, we propose QuadraNet -- a comprehensive model design methodology from neuron reconstruction to structural block and eventually to the overall neural network implementation. Leveraging quadratic neurons' intrinsic high-order advantages and dedicated computation optimization schemes, QuadraNet could effectively achieve optimal cognition and computation performance. Incorporating state-of-the-art hardware-aware neural architecture search and system integration techniques, QuadraNet could also be well generalized in different hardware constraint settings and deployment scenarios. The experiment shows thatQuadraNet achieves up to 1.5$\times$ throughput, 30% less memory footprint, and similar cognition performance, compared with the state-of-the-art high-order approaches.
Fed2: Feature-Aligned Federated Learning
Nov 28, 2021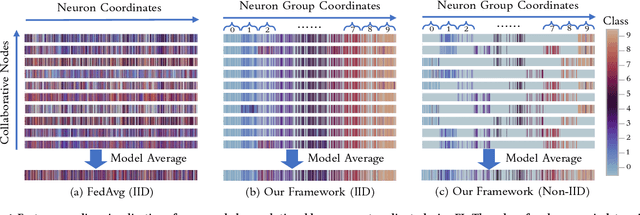
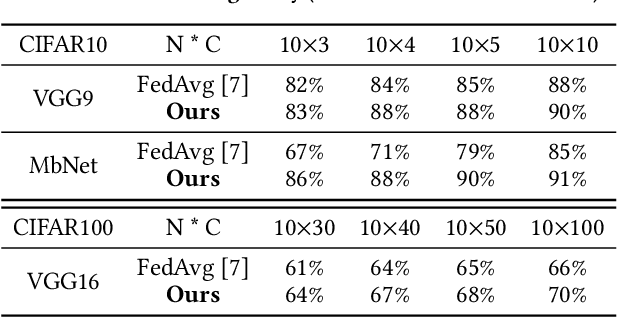
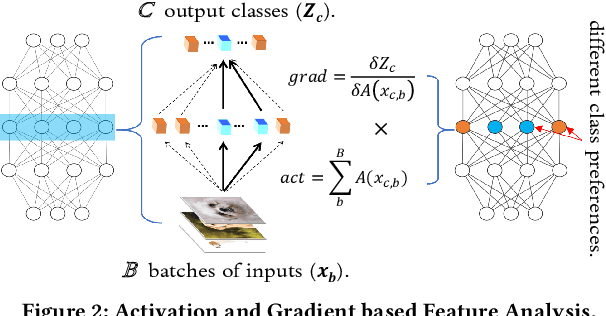
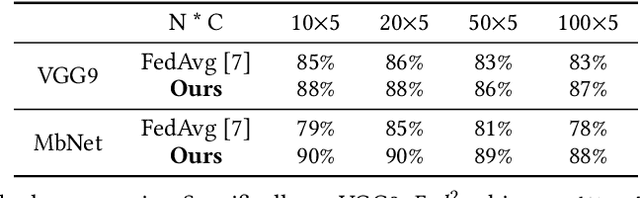
Federated learning learns from scattered data by fusing collaborative models from local nodes. However, the conventional coordinate-based model averaging by FedAvg ignored the random information encoded per parameter and may suffer from structural feature misalignment. In this work, we propose Fed2, a feature-aligned federated learning framework to resolve this issue by establishing a firm structure-feature alignment across the collaborative models. Fed2 is composed of two major designs: First, we design a feature-oriented model structure adaptation method to ensure explicit feature allocation in different neural network structures. Applying the structure adaptation to collaborative models, matchable structures with similar feature information can be initialized at the very early training stage. During the federated learning process, we then propose a feature paired averaging scheme to guarantee aligned feature distribution and maintain no feature fusion conflicts under either IID or non-IID scenarios. Eventually, Fed2 could effectively enhance the federated learning convergence performance under extensive homo- and heterogeneous settings, providing excellent convergence speed, accuracy, and computation/communication efficiency.
A Survey of Large-Scale Deep Learning Serving System Optimization: Challenges and Opportunities
Nov 28, 2021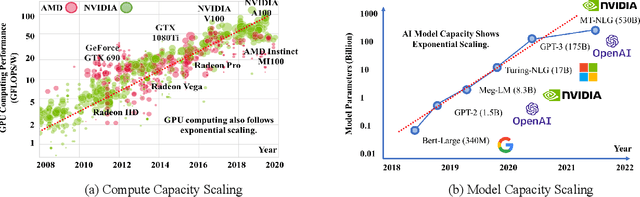
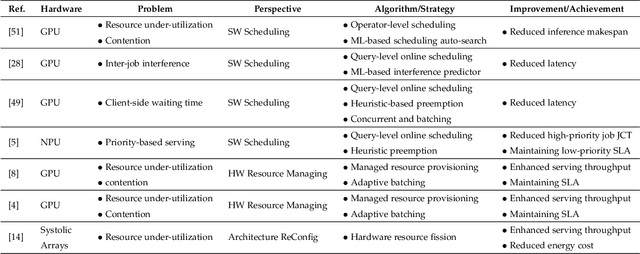
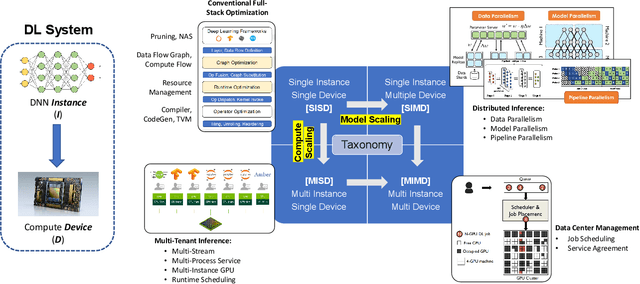
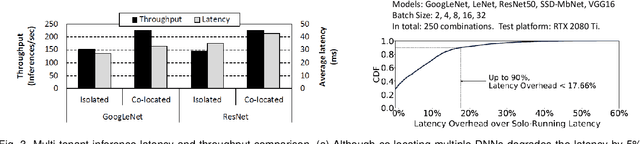
Deep Learning (DL) models have achieved superior performance in many application domains, including vision, language, medical, commercial ads, entertainment, etc. With the fast development, both DL applications and the underlying serving hardware have demonstrated strong scaling trends, i.e., Model Scaling and Compute Scaling, for example, the recent pre-trained model with hundreds of billions of parameters with ~TB level memory consumption, as well as the newest GPU accelerators providing hundreds of TFLOPS. With both scaling trends, new problems and challenges emerge in DL inference serving systems, which gradually trends towards Large-scale Deep learning Serving systems (LDS). This survey aims to summarize and categorize the emerging challenges and optimization opportunities for large-scale deep learning serving systems. By providing a novel taxonomy, summarizing the computing paradigms, and elaborating the recent technique advances, we hope that this survey could shed light on new optimization perspectives and motivate novel works in large-scale deep learning system optimization.
A Survey on Fundamental Limits of Integrated Sensing and Communication
Apr 22, 2021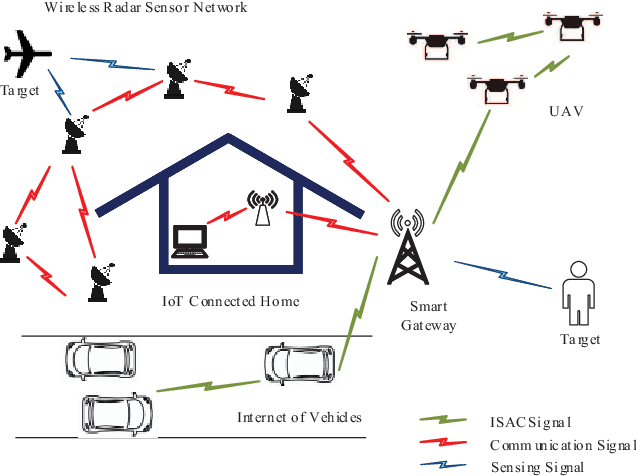
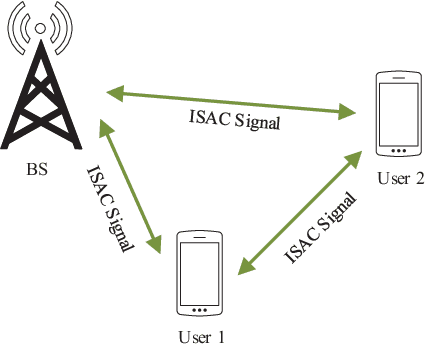
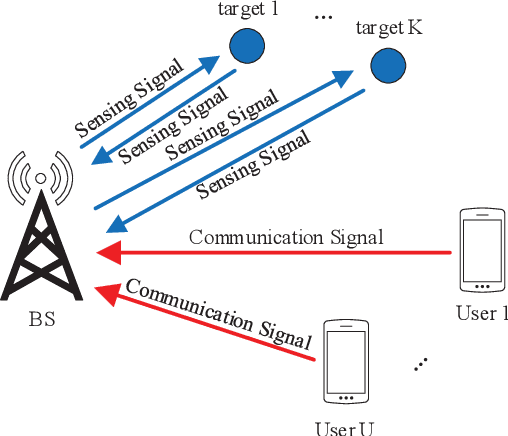
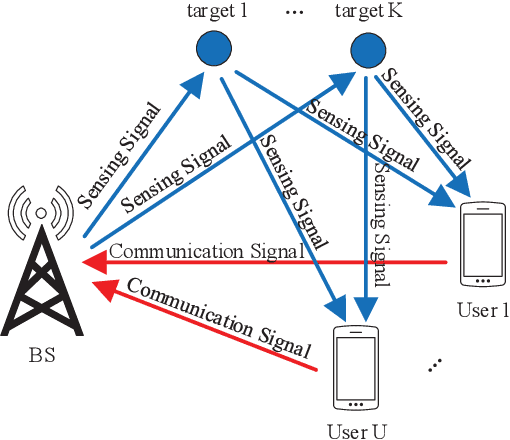
The integrated sensing and communication (ISAC), in which the sensing and communication share the same frequency band and hardware, has emerged as a key technology in future wireless systems. Early works on ISAC have been focused on the design, analysis and optimization of practical ISAC technologies for various ISAC systems. While this line of works are necessary, it is equally important to study the fundamental limits of ISAC in order to understand the gap between the current state-of-the-art technologies and the performance limits, and provide useful insights and guidance for the development of better ISAC technologies that can approach the performance limits. In this paper, we aim to provide a comprehensive survey for the current research progress on the fundamental limits of ISAC. Particularly, we first propose a systematic classification method for both traditional radio sensing (such as radar sensing and wireless localization) and ISAC so that they can be naturally incorporated into a unified framework. Then we summarize the major performance metrics and bounds used in sensing, communications and ISAC, respectively. After that, we present the current research progresses on fundamental limits of each class of the traditional sensing and ISAC systems. Finally, the open problems and future research directions are discussed.