 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE4: Energy-Efficient DNN Inference for Edge Video Analytics Via Early-Exit and DVFS
Mar 06, 2025



Deep neural network (DNN) models are increasingly popular in edge video analytic applications. However, the compute-intensive nature of DNN models pose challenges for energy-efficient inference on resource-constrained edge devices. Most existing solutions focus on optimizing DNN inference latency and accuracy, often overlooking energy efficiency. They also fail to account for the varying complexity of video frames, leading to sub-optimal performance in edge video analytics. In this paper, we propose an Energy-Efficient Early-Exit (E4) framework that enhances DNN inference efficiency for edge video analytics by integrating a novel early-exit mechanism with dynamic voltage and frequency scaling (DVFS) governors. It employs an attention-based cascade module to analyze video frame diversity and automatically determine optimal DNN exit points. Additionally, E4 features a just-in-time (JIT) profiler that uses coordinate descent search to co-optimize CPU and GPU clock frequencies for each layer before the DNN exit points. Extensive evaluations demonstrate that E4 outperforms current state-of-the-art methods, achieving up to 2.8x speedup and 26% average energy saving while maintaining high accuracy.
PVTree: Realistic and Controllable Palm Vein Generation for Recognition Tasks
Mar 04, 2025Palm vein recognition is an emerging biometric technology that offers enhanced security and privacy. However, acquiring sufficient palm vein data for training deep learning-based recognition models is challenging due to the high costs of data collection and privacy protection constraints. This has led to a growing interest in generating pseudo-palm vein data using generative models. Existing methods, however, often produce unrealistic palm vein patterns or struggle with controlling identity and style attributes. To address these issues, we propose a novel palm vein generation framework named PVTree. First, the palm vein identity is defined by a complex and authentic 3D palm vascular tree, created using an improved Constrained Constructive Optimization (CCO) algorithm. Second, palm vein patterns of the same identity are generated by projecting the same 3D vascular tree into 2D images from different views and converting them into realistic images using a generative model. As a result, PVTree satisfies the need for both identity consistency and intra-class diversity. Extensive experiments conducted on several publicly available datasets demonstrate that our proposed palm vein generation method surpasses existing methods and achieves a higher TAR@FAR=1e-4 under the 1:1 Open-set protocol. To the best of our knowledge, this is the first time that the performance of a recognition model trained on synthetic palm vein data exceeds that of the recognition model trained on real data, which indicates that palm vein image generation research has a promising future.
Efficient Jailbreaking of Large Models by Freeze Training: Lower Layers Exhibit Greater Sensitivity to Harmful Content
Feb 28, 2025



With the widespread application of Large Language Models across various domains, their security issues have increasingly garnered significant attention from both academic and industrial communities. This study conducts sampling and normalization of the parameters of the LLM to generate visual representations and heatmaps of parameter distributions, revealing notable discrepancies in parameter distributions among certain layers within the hidden layers. Further analysis involves calculating statistical metrics for each layer, followed by the computation of a Comprehensive Sensitivity Score based on these metrics, which identifies the lower layers as being particularly sensitive to the generation of harmful content. Based on this finding, we employ a Freeze training strategy, selectively performing Supervised Fine-Tuning only on the lower layers. Experimental results demonstrate that this method significantly reduces training duration and GPU memory consumption while maintaining a high jailbreak success rate and a high harm score, outperforming the results achieved by applying the LoRA method for SFT across all layers. Additionally, the method has been successfully extended to other open-source large models, validating its generality and effectiveness across different model architectures. Furthermore, we compare our method with ohter jailbreak method, demonstrating the superior performance of our approach. By innovatively proposing a method to statistically analyze and compare large model parameters layer by layer, this study provides new insights into the interpretability of large models. These discoveries emphasize the necessity of continuous research and the implementation of adaptive security measures in the rapidly evolving field of LLMs to prevent potential jailbreak attack risks, thereby promoting the development of more robust and secure LLMs.
Multimodal Inconsistency Reasoning (MMIR): A New Benchmark for Multimodal Reasoning Models
Feb 22, 2025Existing Multimodal Large Language Models (MLLMs) are predominantly trained and tested on consistent visual-textual inputs, leaving open the question of whether they can handle inconsistencies in real-world, layout-rich content. To bridge this gap, we propose the Multimodal Inconsistency Reasoning (MMIR) benchmark to assess MLLMs' ability to detect and reason about semantic mismatches in artifacts such as webpages, presentation slides, and posters. MMIR comprises 534 challenging samples, each containing synthetically injected errors across five reasoning-heavy categories: Factual Contradiction, Identity Misattribution, Contextual Mismatch, Quantitative Discrepancy, and Temporal/Spatial Incoherence. We evaluate six state-of-the-art MLLMs, showing that models with dedicated multimodal reasoning capabilities, such as o1, substantially outperform their counterparts while open-source models remain particularly vulnerable to inconsistency errors. Detailed error analyses further show that models excel in detecting inconsistencies confined to a single modality, particularly in text, but struggle with cross-modal conflicts and complex layouts. Probing experiments reveal that single-modality prompting, including Chain-of-Thought (CoT) and Set-of-Mark (SoM) methods, yields marginal gains, revealing a key bottleneck in cross-modal reasoning. Our findings highlight the need for advanced multimodal reasoning and point to future research on multimodal inconsistency.
DOEI: Dual Optimization of Embedding Information for Attention-Enhanced Class Activation Maps
Feb 21, 2025Weakly supervised semantic segmentation (WSSS) typically utilizes limited semantic annotations to obtain initial Class Activation Maps (CAMs). However, due to the inadequate coupling between class activation responses and semantic information in high-dimensional space, the CAM is prone to object co-occurrence or under-activation, resulting in inferior recognition accuracy. To tackle this issue, we propose DOEI, Dual Optimization of Embedding Information, a novel approach that reconstructs embedding representations through semantic-aware attention weight matrices to optimize the expression capability of embedding information. Specifically, DOEI amplifies tokens with high confidence and suppresses those with low confidence during the class-to-patch interaction. This alignment of activation responses with semantic information strengthens the propagation and decoupling of target features, enabling the generated embeddings to more accurately represent target features in high-level semantic space. In addition, we propose a hybrid-feature alignment module in DOEI that combines RGB values, embedding-guided features, and self-attention weights to increase the reliability of candidate tokens. Comprehensive experiments show that DOEI is an effective plug-and-play module that empowers state-of-the-art visual transformer-based WSSS models to significantly improve the quality of CAMs and segmentation performance on popular benchmarks, including PASCAL VOC (+3.6%, +1.5%, +1.2% mIoU) and MS COCO (+1.2%, +1.6% mIoU). Code will be available at https://github.com/AIGeeksGroup/DOEI.
PedDet: Adaptive Spectral Optimization for Multimodal Pedestrian Detection
Feb 21, 2025



Pedestrian detection in intelligent transportation systems has made significant progress but faces two critical challenges: (1) insufficient fusion of complementary information between visible and infrared spectra, particularly in complex scenarios, and (2) sensitivity to illumination changes, such as low-light or overexposed conditions, leading to degraded performance. To address these issues, we propose PedDet, an adaptive spectral optimization complementarity framework specifically enhanced and optimized for multispectral pedestrian detection. PedDet introduces the Multi-scale Spectral Feature Perception Module (MSFPM) to adaptively fuse visible and infrared features, enhancing robustness and flexibility in feature extraction. Additionally, the Illumination Robustness Feature Decoupling Module (IRFDM) improves detection stability under varying lighting by decoupling pedestrian and background features. We further design a contrastive alignment to enhance intermodal feature discrimination. Experiments on LLVIP and MSDS datasets demonstrate that PedDet achieves state-of-the-art performance, improving the mAP by 6.6% with superior detection accuracy even in low-light conditions, marking a significant step forward for road safety. Code will be available at https://github.com/AIGeeksGroup/PedDet.
Poster: SpiderSim: Multi-Agent Driven Theoretical Cybersecurity Simulation for Industrial Digitalization
Feb 19, 2025Rapid industrial digitalization has created intricate cybersecurity demands that necessitate effective validation methods. While cyber ranges and simulation platforms are widely deployed, they frequently face limitations in scenario diversity and creation efficiency. In this paper, we present SpiderSim, a theoretical cybersecurity simulation platform enabling rapid and lightweight scenario generation for industrial digitalization security research. At its core, our platform introduces three key innovations: a structured framework for unified scenario modeling, a multi-agent collaboration mechanism for automated generation, and modular atomic security capabilities for flexible scenario composition. Extensive implementation trials across multiple industrial digitalization contexts, including marine ranch monitoring systems, validate our platform's capacity for broad scenario coverage with efficient generation processes. Built on solid theoretical foundations and released as open-source software, SpiderSim facilitates broader research and development in automated security testing for industrial digitalization.
3DMolFormer: A Dual-channel Framework for Structure-based Drug Discovery
Feb 07, 2025



Structure-based drug discovery, encompassing the tasks of protein-ligand docking and pocket-aware 3D drug design, represents a core challenge in drug discovery. However, no existing work can deal with both tasks to effectively leverage the duality between them, and current methods for each task are hindered by challenges in modeling 3D information and the limitations of available data. To address these issues, we propose 3DMolFormer, a unified dual-channel transformer-based framework applicable to both docking and 3D drug design tasks, which exploits their duality by utilizing docking functionalities within the drug design process. Specifically, we represent 3D pocket-ligand complexes using parallel sequences of discrete tokens and continuous numbers, and we design a corresponding dual-channel transformer model to handle this format, thereby overcoming the challenges of 3D information modeling. Additionally, we alleviate data limitations through large-scale pre-training on a mixed dataset, followed by supervised and reinforcement learning fine-tuning techniques respectively tailored for the two tasks. Experimental results demonstrate that 3DMolFormer outperforms previous approaches in both protein-ligand docking and pocket-aware 3D drug design, highlighting its promising application in structure-based drug discovery. The code is available at: https://github.com/HXYfighter/3DMolFormer .
GENIE: Generative Note Information Extraction model for structuring EHR data
Jan 30, 2025
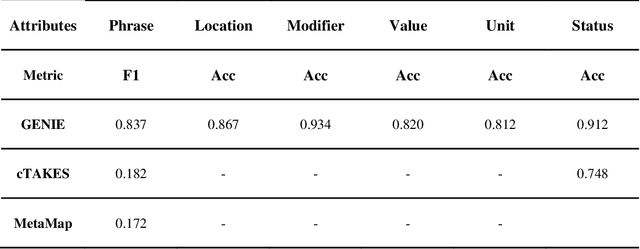
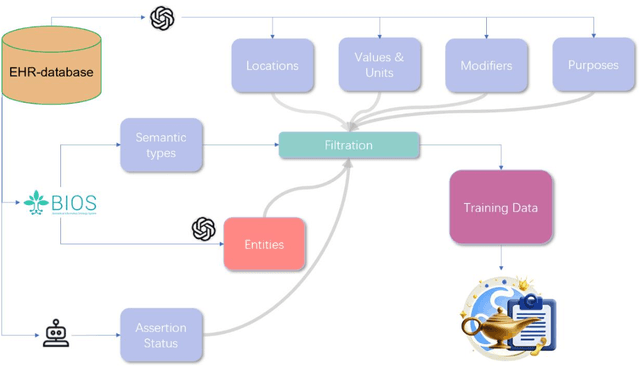
Electronic Health Records (EHRs) hold immense potential for advancing healthcare, offering rich, longitudinal data that combines structured information with valuable insights from unstructured clinical notes. However, the unstructured nature of clinical text poses significant challenges for secondary applications. Traditional methods for structuring EHR free-text data, such as rule-based systems and multi-stage pipelines, are often limited by their time-consuming configurations and inability to adapt across clinical notes from diverse healthcare settings. Few systems provide a comprehensive attribute extraction for terminologies. While giant large language models (LLMs) like GPT-4 and LLaMA 405B excel at structuring tasks, they are slow, costly, and impractical for large-scale use. To overcome these limitations, we introduce GENIE, a Generative Note Information Extraction system that leverages LLMs to streamline the structuring of unstructured clinical text into usable data with standardized format. GENIE processes entire paragraphs in a single pass, extracting entities, assertion statuses, locations, modifiers, values, and purposes with high accuracy. Its unified, end-to-end approach simplifies workflows, reduces errors, and eliminates the need for extensive manual intervention. Using a robust data preparation pipeline and fine-tuned small scale LLMs, GENIE achieves competitive performance across multiple information extraction tasks, outperforming traditional tools like cTAKES and MetaMap and can handle extra attributes to be extracted. GENIE strongly enhances real-world applicability and scalability in healthcare systems. By open-sourcing the model and test data, we aim to encourage collaboration and drive further advancements in EHR structurization.
Movable Antenna-Aided Cooperative ISAC Network with Time Synchronization error and Imperfect CSI
Jan 26, 2025Cooperative-integrated sensing and communication (C-ISAC) networks have emerged as promising solutions for communication and target sensing. However, imperfect channel state information (CSI) estimation and time synchronization (TS) errors degrade performance, affecting communication and sensing accuracy. This paper addresses these challenges {by employing} {movable antennas} (MAs) to enhance C-ISAC robustness. We analyze the impact of CSI errors on achievable rates and introduce a hybrid Cramer-Rao lower bound (HCRLB) to evaluate the effect of TS errors on target localization accuracy. Based on these models, we derive the worst-case achievable rate and sensing precision under such errors. We optimize cooperative beamforming, {base station (BS)} selection factor and MA position to minimize power consumption while ensuring accuracy. {We then propose a} constrained deep reinforcement learning (C-DRL) approach to solve this non-convex optimization problem, using a modified deep deterministic policy gradient (DDPG) algorithm with a Wolpertinger architecture for efficient training under complex constraints. {Simulation results show that the proposed method significantly improves system robustness against CSI and TS errors, where robustness mean reliable data transmission under poor channel conditions.} These findings demonstrate the potential of MA technology to reduce power consumption in imperfect CSI and TS environments.