 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANS: Accelerating Multiuser Collaborative Edge Inference via Cooperative Autodidactic NeuroSurgeon
Jun 08, 2026Recently, mobile edge computing (MEC)-enabled collaborative deep neural network (DNN) inference has emerged as a promising approach for delivering intelligent services to resource-constrained mobile devices. A representative scenario is multi-user collaborative edge inference, where distinct devices independently partition their DNN models and offload backend computation to a common edge server over wireless networks. However, determining the optimal DNN partition for each device is challenging due to unknown and time-varying system conditions, including fluctuating wireless links and diverse device capabilities. To address this problem, we propose Cooperative Autodidactic NeuroSurgeon (CANS), a collaborative edge inference framework that enables devices to adaptively learn optimal DNN partitions by sharing informative feedback during online inference. To handle the challenge of device heterogeneity and better leverage offline inference experience, we integrate a novel FedLinUCB-DW algorithm that groups devices of the same type and warm-starts online exploration using local offline early-exit inference experience. Furthermore, we provide theoretical guarantees for FedLinUCB-DW by deriving the regret upper bound. We also validate our method on both a simulated environment and a hardware prototype system. Empirical evaluations demonstrate that CANS achieves lower inference latency compared to state-of-the-art baselines. Especially, in prototype experiments on two edge devices, the proposed CANS reduced average inference latency by up to 50% compared to the non-cooperative baseline.
E4: Energy-Efficient DNN Inference for Edge Video Analytics Via Early-Exit and DVFS
Mar 06, 2025



Deep neural network (DNN) models are increasingly popular in edge video analytic applications. However, the compute-intensive nature of DNN models pose challenges for energy-efficient inference on resource-constrained edge devices. Most existing solutions focus on optimizing DNN inference latency and accuracy, often overlooking energy efficiency. They also fail to account for the varying complexity of video frames, leading to sub-optimal performance in edge video analytics. In this paper, we propose an Energy-Efficient Early-Exit (E4) framework that enhances DNN inference efficiency for edge video analytics by integrating a novel early-exit mechanism with dynamic voltage and frequency scaling (DVFS) governors. It employs an attention-based cascade module to analyze video frame diversity and automatically determine optimal DNN exit points. Additionally, E4 features a just-in-time (JIT) profiler that uses coordinate descent search to co-optimize CPU and GPU clock frequencies for each layer before the DNN exit points. Extensive evaluations demonstrate that E4 outperforms current state-of-the-art methods, achieving up to 2.8x speedup and 26% average energy saving while maintaining high accuracy.
DVFO: Learning-Based DVFS for Energy-Efficient Edge-Cloud Collaborative Inference
Jun 23, 2023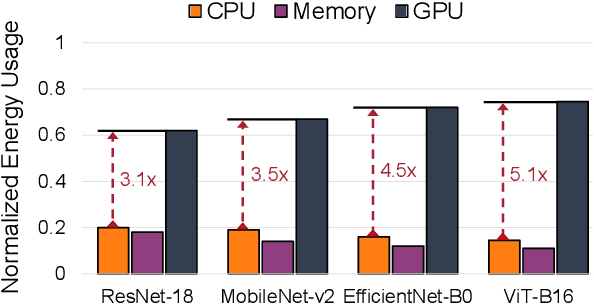
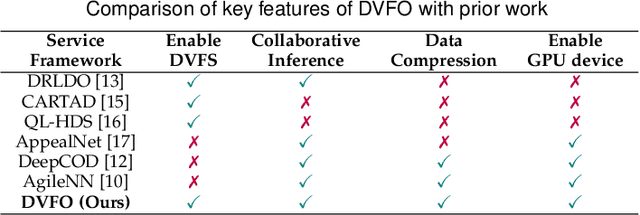
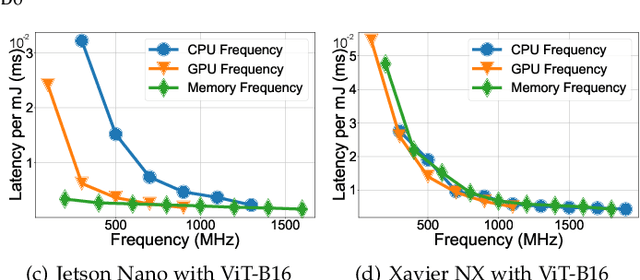
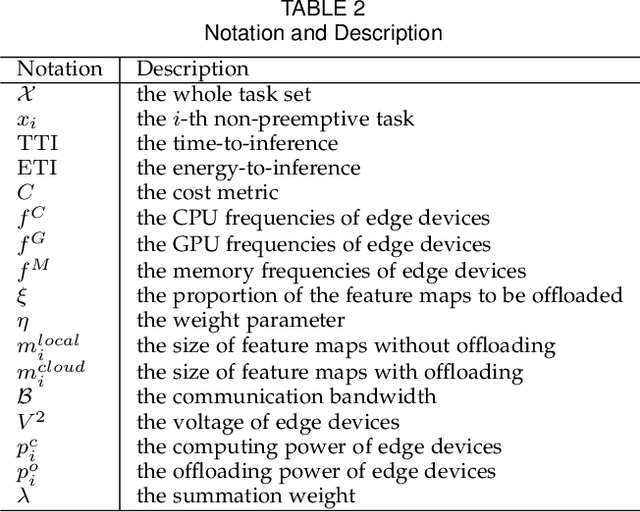
Due to limited resources on edge and different characteristics of deep neural network (DNN) models, it is a big challenge to optimize DNN inference performance in terms of energy consumption and end-to-end latency on edge devices. In addition to the dynamic voltage frequency scaling (DVFS) technique, the edge-cloud architecture provides a collaborative approach for efficient DNN inference. However, current edge-cloud collaborative inference methods have not optimized various compute resources on edge devices. Thus, we propose DVFO, a novel DVFS-enabled edge-cloud collaborative inference framework, which co-optimizes DVFS and offloading parameters via deep reinforcement learning (DRL). Specifically, DVFO automatically co-optimizes 1) the CPU, GPU and memory frequencies of edge devices, and 2) the feature maps to be offloaded to cloud servers. In addition, it leverages a thinking-while-moving concurrent mechanism to accelerate the DRL learning process, and a spatial-channel attention mechanism to extract DNN feature maps of secondary importance for workload offloading. This approach improves inference performance for different DNN models under various edge-cloud network conditions. Extensive evaluations using two datasets and six widely-deployed DNN models on three heterogeneous edge devices show that DVFO significantly reduces the energy consumption by 33% on average, compared to state-of-the-art schemes. Moreover, DVFO achieves up to 28.6%-59.1% end-to-end latency reduction, while maintaining accuracy within 1% loss on average.
BCEdge: SLO-Aware DNN Inference Services with Adaptive Batching on Edge Platforms
May 01, 2023



As deep neural networks (DNNs) are being applied to a wide range of edge intelligent applications, it is critical for edge inference platforms to have both high-throughput and low-latency at the same time. Such edge platforms with multiple DNN models pose new challenges for scheduler designs. First, each request may have different service level objectives (SLOs) to improve quality of service (QoS). Second, the edge platforms should be able to efficiently schedule multiple heterogeneous DNN models so that system utilization can be improved. To meet these two goals, this paper proposes BCEdge, a novel learning-based scheduling framework that takes adaptive batching and concurrent execution of DNN inference services on edge platforms. We define a utility function to evaluate the trade-off between throughput and latency. The scheduler in BCEdge leverages maximum entropy-based deep reinforcement learning (DRL) to maximize utility by 1) co-optimizing batch size and 2) the number of concurrent models automatically. Our prototype implemented on different edge platforms shows that the proposed BCEdge enhances utility by up to 37.6% on average, compared to state-of-the-art solutions, while satisfying SLOs.