 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAD: HAllucination Detection Language Models Based on a Comprehensive Hallucination Taxonomy
Oct 22, 2025The increasing reliance on natural language generation (NLG) models, particularly large language models, has raised concerns about the reliability and accuracy of their outputs. A key challenge is hallucination, where models produce plausible but incorrect information. As a result, hallucination detection has become a critical task. In this work, we introduce a comprehensive hallucination taxonomy with 11 categories across various NLG tasks and propose the HAllucination Detection (HAD) models https://github.com/pku0xff/HAD, which integrate hallucination detection, span-level identification, and correction into a single inference process. Trained on an elaborate synthetic dataset of about 90K samples, our HAD models are versatile and can be applied to various NLG tasks. We also carefully annotate a test set for hallucination detection, called HADTest, which contains 2,248 samples. Evaluations on in-domain and out-of-domain test sets show that our HAD models generally outperform the existing baselines, achieving state-of-the-art results on HaluEval, FactCHD, and FaithBench, confirming their robustness and versatility.
LOTA: Bit-Planes Guided AI-Generated Image Detection
Oct 16, 2025The rapid advancement of GAN and Diffusion models makes it more difficult to distinguish AI-generated images from real ones. Recent studies often use image-based reconstruction errors as an important feature for determining whether an image is AI-generated. However, these approaches typically incur high computational costs and also fail to capture intrinsic noisy features present in the raw images. To solve these problems, we innovatively refine error extraction by using bit-plane-based image processing, as lower bit planes indeed represent noise patterns in images. We introduce an effective bit-planes guided noisy image generation and exploit various image normalization strategies, including scaling and thresholding. Then, to amplify the noise signal for easier AI-generated image detection, we design a maximum gradient patch selection that applies multi-directional gradients to compute the noise score and selects the region with the highest score. Finally, we propose a lightweight and effective classification head and explore two different structures: noise-based classifier and noise-guided classifier. Extensive experiments on the GenImage benchmark demonstrate the outstanding performance of our method, which achieves an average accuracy of \textbf{98.9\%} (\textbf{11.9}\%~$\uparrow$) and shows excellent cross-generator generalization capability. Particularly, our method achieves an accuracy of over 98.2\% from GAN to Diffusion and over 99.2\% from Diffusion to GAN. Moreover, it performs error extraction at the millisecond level, nearly a hundred times faster than existing methods. The code is at https://github.com/hongsong-wang/LOTA.
LMM-Incentive: Large Multimodal Model-based Incentive Design for User-Generated Content in Web 3.0
Oct 06, 2025Web 3.0 represents the next generation of the Internet, which is widely recognized as a decentralized ecosystem that focuses on value expression and data ownership. By leveraging blockchain and artificial intelligence technologies, Web 3.0 offers unprecedented opportunities for users to create, own, and monetize their content, thereby enabling User-Generated Content (UGC) to an entirely new level. However, some self-interested users may exploit the limitations of content curation mechanisms and generate low-quality content with less effort, obtaining platform rewards under information asymmetry. Such behavior can undermine Web 3.0 performance. To this end, we propose \textit{LMM-Incentive}, a novel Large Multimodal Model (LMM)-based incentive mechanism for UGC in Web 3.0. Specifically, we propose an LMM-based contract-theoretic model to motivate users to generate high-quality UGC, thereby mitigating the adverse selection problem from information asymmetry. To alleviate potential moral hazards after contract selection, we leverage LMM agents to evaluate UGC quality, which is the primary component of the contract, utilizing prompt engineering techniques to improve the evaluation performance of LMM agents. Recognizing that traditional contract design methods cannot effectively adapt to the dynamic environment of Web 3.0, we develop an improved Mixture of Experts (MoE)-based Proximal Policy Optimization (PPO) algorithm for optimal contract design. Simulation results demonstrate the superiority of the proposed MoE-based PPO algorithm over representative benchmarks in the context of contract design. Finally, we deploy the designed contract within an Ethereum smart contract framework, further validating the effectiveness of the proposed scheme.
JADES: A Universal Framework for Jailbreak Assessment via Decompositional Scoring
Aug 28, 2025Accurately determining whether a jailbreak attempt has succeeded is a fundamental yet unresolved challenge. Existing evaluation methods rely on misaligned proxy indicators or naive holistic judgments. They frequently misinterpret model responses, leading to inconsistent and subjective assessments that misalign with human perception. To address this gap, we introduce JADES (Jailbreak Assessment via Decompositional Scoring), a universal jailbreak evaluation framework. Its key mechanism is to automatically decompose an input harmful question into a set of weighted sub-questions, score each sub-answer, and weight-aggregate the sub-scores into a final decision. JADES also incorporates an optional fact-checking module to strengthen the detection of hallucinations in jailbreak responses. We validate JADES on JailbreakQR, a newly introduced benchmark proposed in this work, consisting of 400 pairs of jailbreak prompts and responses, each meticulously annotated by humans. In a binary setting (success/failure), JADES achieves 98.5% agreement with human evaluators, outperforming strong baselines by over 9%. Re-evaluating five popular attacks on four LLMs reveals substantial overestimation (e.g., LAA's attack success rate on GPT-3.5-Turbo drops from 93% to 69%). Our results show that JADES could deliver accurate, consistent, and interpretable evaluations, providing a reliable basis for measuring future jailbreak attacks.
Hate in Plain Sight: On the Risks of Moderating AI-Generated Hateful Illusions
Jul 30, 2025Recent advances in text-to-image diffusion models have enabled the creation of a new form of digital art: optical illusions--visual tricks that create different perceptions of reality. However, adversaries may misuse such techniques to generate hateful illusions, which embed specific hate messages into harmless scenes and disseminate them across web communities. In this work, we take the first step toward investigating the risks of scalable hateful illusion generation and the potential for bypassing current content moderation models. Specifically, we generate 1,860 optical illusions using Stable Diffusion and ControlNet, conditioned on 62 hate messages. Of these, 1,571 are hateful illusions that successfully embed hate messages, either overtly or subtly, forming the Hateful Illusion dataset. Using this dataset, we evaluate the performance of six moderation classifiers and nine vision language models (VLMs) in identifying hateful illusions. Experimental results reveal significant vulnerabilities in existing moderation models: the detection accuracy falls below 0.245 for moderation classifiers and below 0.102 for VLMs. We further identify a critical limitation in their vision encoders, which mainly focus on surface-level image details while overlooking the secondary layer of information, i.e., hidden messages. To address this risk, we explore preliminary mitigation measures and identify the most effective approaches from the perspectives of image transformations and training-level strategies.
Latent Inter-User Difference Modeling for LLM Personalization
Jul 28, 2025Large language models (LLMs) are increasingly integrated into users' daily lives, leading to a growing demand for personalized outputs. Previous work focuses on leveraging a user's own history, overlooking inter-user differences that are crucial for effective personalization. While recent work has attempted to model such differences, the reliance on language-based prompts often hampers the effective extraction of meaningful distinctions. To address these issues, we propose Difference-aware Embedding-based Personalization (DEP), a framework that models inter-user differences in the latent space instead of relying on language prompts. DEP constructs soft prompts by contrasting a user's embedding with those of peers who engaged with similar content, highlighting relative behavioral signals. A sparse autoencoder then filters and compresses both user-specific and difference-aware embeddings, preserving only task-relevant features before injecting them into a frozen LLM. Experiments on personalized review generation show that DEP consistently outperforms baseline methods across multiple metrics. Our code is available at https://github.com/SnowCharmQ/DEP.
ProsodyLM: Uncovering the Emerging Prosody Processing Capabilities in Speech Language Models
Jul 27, 2025Speech language models refer to language models with speech processing and understanding capabilities. One key desirable capability for speech language models is the ability to capture the intricate interdependency between content and prosody. The existing mainstream paradigm of training speech language models, which converts speech into discrete tokens before feeding them into LLMs, is sub-optimal in learning prosody information -- we find that the resulting LLMs do not exhibit obvious emerging prosody processing capabilities via pre-training alone. To overcome this, we propose ProsodyLM, which introduces a simple tokenization scheme amenable to learning prosody. Each speech utterance is first transcribed into text, followed by a sequence of word-level prosody tokens. Compared with conventional speech tokenization schemes, the proposed tokenization scheme retains more complete prosody information, and is more understandable to text-based LLMs. We find that ProsodyLM can learn surprisingly diverse emerging prosody processing capabilities through pre-training alone, ranging from harnessing the prosody nuances in generated speech, such as contrastive focus, understanding emotion and stress in an utterance, to maintaining prosody consistency in long contexts.
SplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling
Jul 22, 2025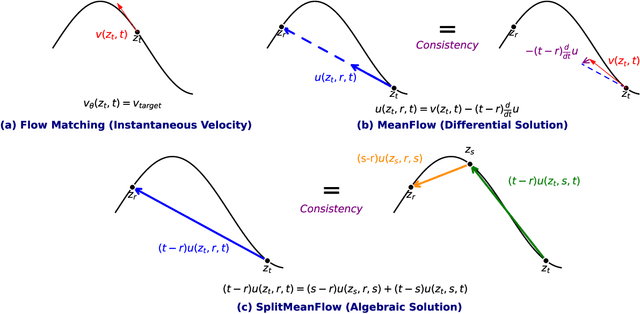


Generative models like Flow Matching have achieved state-of-the-art performance but are often hindered by a computationally expensive iterative sampling process. To address this, recent work has focused on few-step or one-step generation by learning the average velocity field, which directly maps noise to data. MeanFlow, a leading method in this area, learns this field by enforcing a differential identity that connects the average and instantaneous velocities. In this work, we argue that this differential formulation is a limiting special case of a more fundamental principle. We return to the first principles of average velocity and leverage the additivity property of definite integrals. This leads us to derive a novel, purely algebraic identity we term Interval Splitting Consistency. This identity establishes a self-referential relationship for the average velocity field across different time intervals without resorting to any differential operators. Based on this principle, we introduce SplitMeanFlow, a new training framework that enforces this algebraic consistency directly as a learning objective. We formally prove that the differential identity at the core of MeanFlow is recovered by taking the limit of our algebraic consistency as the interval split becomes infinitesimal. This establishes SplitMeanFlow as a direct and more general foundation for learning average velocity fields. From a practical standpoint, our algebraic approach is significantly more efficient, as it eliminates the need for JVP computations, resulting in simpler implementation, more stable training, and broader hardware compatibility. One-step and two-step SplitMeanFlow models have been successfully deployed in large-scale speech synthesis products (such as Doubao), achieving speedups of 20x.
The Evolving Role of Large Language Models in Scientific Innovation: Evaluator, Collaborator, and Scientist
Jul 16, 2025Scientific innovation is undergoing a paradigm shift driven by the rapid advancement of Large Language Models (LLMs). As science faces mounting challenges including information overload, disciplinary silos, and diminishing returns on conventional research methods, LLMs are emerging as powerful agents capable not only of enhancing scientific workflows but also of participating in and potentially leading the innovation process. Existing surveys mainly focus on different perspectives, phrases, and tasks in scientific research and discovery, while they have limitations in understanding the transformative potential and role differentiation of LLM. This survey proposes a comprehensive framework to categorize the evolving roles of LLMs in scientific innovation across three hierarchical levels: Evaluator, Collaborator, and Scientist. We distinguish between LLMs' contributions to structured scientific research processes and open-ended scientific discovery, thereby offering a unified taxonomy that clarifies capability boundaries, evaluation criteria, and human-AI interaction patterns at each level. Through an extensive analysis of current methodologies, benchmarks, systems, and evaluation metrics, this survey delivers an in-depth and systematic synthesis on LLM-driven scientific innovation. We present LLMs not only as tools for automating existing processes, but also as catalysts capable of reshaping the epistemological foundations of science itself. This survey offers conceptual clarity, practical guidance, and theoretical foundations for future research, while also highlighting open challenges and ethical considerations in the pursuit of increasingly autonomous AI-driven science. Resources related to this survey can be accessed on GitHub at: https://github.com/haoxuan-unt2024/llm4innovation.
Spline Deformation Field
Jul 10, 2025



Trajectory modeling of dense points usually employs implicit deformation fields, represented as neural networks that map coordinates to relate canonical spatial positions to temporal offsets. However, the inductive biases inherent in neural networks can hinder spatial coherence in ill-posed scenarios. Current methods focus either on enhancing encoding strategies for deformation fields, often resulting in opaque and less intuitive models, or adopt explicit techniques like linear blend skinning, which rely on heuristic-based node initialization. Additionally, the potential of implicit representations for interpolating sparse temporal signals remains under-explored. To address these challenges, we propose a spline-based trajectory representation, where the number of knots explicitly determines the degrees of freedom. This approach enables efficient analytical derivation of velocities, preserving spatial coherence and accelerations, while mitigating temporal fluctuations. To model knot characteristics in both spatial and temporal domains, we introduce a novel low-rank time-variant spatial encoding, replacing conventional coupled spatiotemporal techniques. Our method demonstrates superior performance in temporal interpolation for fitting continuous fields with sparse inputs. Furthermore, it achieves competitive dynamic scene reconstruction quality compared to state-of-the-art methods while enhancing motion coherence without relying on linear blend skinning or as-rigid-as-possible constraints.