 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpline Deformation Field
Jul 10, 2025



Trajectory modeling of dense points usually employs implicit deformation fields, represented as neural networks that map coordinates to relate canonical spatial positions to temporal offsets. However, the inductive biases inherent in neural networks can hinder spatial coherence in ill-posed scenarios. Current methods focus either on enhancing encoding strategies for deformation fields, often resulting in opaque and less intuitive models, or adopt explicit techniques like linear blend skinning, which rely on heuristic-based node initialization. Additionally, the potential of implicit representations for interpolating sparse temporal signals remains under-explored. To address these challenges, we propose a spline-based trajectory representation, where the number of knots explicitly determines the degrees of freedom. This approach enables efficient analytical derivation of velocities, preserving spatial coherence and accelerations, while mitigating temporal fluctuations. To model knot characteristics in both spatial and temporal domains, we introduce a novel low-rank time-variant spatial encoding, replacing conventional coupled spatiotemporal techniques. Our method demonstrates superior performance in temporal interpolation for fitting continuous fields with sparse inputs. Furthermore, it achieves competitive dynamic scene reconstruction quality compared to state-of-the-art methods while enhancing motion coherence without relying on linear blend skinning or as-rigid-as-possible constraints.
Stylized Structural Patterns for Improved Neural Network Pre-training
Jun 24, 2025Modern deep learning models in computer vision require large datasets of real images, which are difficult to curate and pose privacy and legal concerns, limiting their commercial use. Recent works suggest synthetic data as an alternative, yet models trained with it often underperform. This paper proposes a two-step approach to bridge this gap. First, we propose an improved neural fractal formulation through which we introduce a new class of synthetic data. Second, we propose reverse stylization, a technique that transfers visual features from a small, license-free set of real images onto synthetic datasets, enhancing their effectiveness. We analyze the domain gap between our synthetic datasets and real images using Kernel Inception Distance (KID) and show that our method achieves a significantly lower distributional gap compared to existing synthetic datasets. Furthermore, our experiments across different tasks demonstrate the practical impact of this reduced gap. We show that pretraining the EDM2 diffusion model on our synthetic dataset leads to an 11% reduction in FID during image generation, compared to models trained on existing synthetic datasets, and a 20% decrease in autoencoder reconstruction error, indicating improved performance in data representation. Furthermore, a ViT-S model trained for classification on this synthetic data achieves over a 10% improvement in ImageNet-100 accuracy. Our work opens up exciting possibilities for training practical models when sufficiently large real training sets are not available.
Designing Effective Inter-Pixel Information Flow for Natural Image Matting
Jul 17, 2017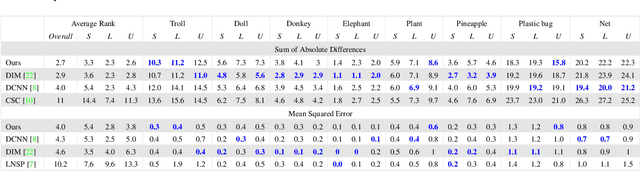


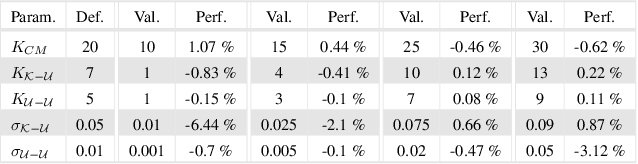
We present a novel, purely affinity-based natural image matting algorithm. Our method relies on carefully defined pixel-to-pixel connections that enable effective use of information available in the image. We control the information flow from the known-opacity regions into the unknown region, as well as within the unknown region itself, by utilizing multiple definitions of pixel affinities. Among other forms of information flow, we introduce color-mixture flow, which builds upon local linear embedding and effectively encapsulates the relation between different pixel opacities. Our resulting novel linear system formulation can be solved in closed-form and is robust against several fundamental challenges of natural matting such as holes and remote intricate structures. Our evaluation using the alpha matting benchmark suggests a significant performance improvement over the current methods. While our method is primarily designed as a standalone matting tool, we show that it can also be used for regularizing mattes obtained by sampling-based methods. We extend our formulation to layer color estimation and show that the use of multiple channels of flow increases the layer color quality. We also demonstrate our performance in green-screen keying and further analyze the characteristics of the affinities used in our method.