 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
ProsodyLM: Uncovering the Emerging Prosody Processing Capabilities in Speech Language Models
Jul 27, 2025Speech language models refer to language models with speech processing and understanding capabilities. One key desirable capability for speech language models is the ability to capture the intricate interdependency between content and prosody. The existing mainstream paradigm of training speech language models, which converts speech into discrete tokens before feeding them into LLMs, is sub-optimal in learning prosody information -- we find that the resulting LLMs do not exhibit obvious emerging prosody processing capabilities via pre-training alone. To overcome this, we propose ProsodyLM, which introduces a simple tokenization scheme amenable to learning prosody. Each speech utterance is first transcribed into text, followed by a sequence of word-level prosody tokens. Compared with conventional speech tokenization schemes, the proposed tokenization scheme retains more complete prosody information, and is more understandable to text-based LLMs. We find that ProsodyLM can learn surprisingly diverse emerging prosody processing capabilities through pre-training alone, ranging from harnessing the prosody nuances in generated speech, such as contrastive focus, understanding emotion and stress in an utterance, to maintaining prosody consistency in long contexts.
ArrayDPS: Unsupervised Blind Speech Separation with a Diffusion Prior
May 17, 2025



Blind Speech Separation (BSS) aims to separate multiple speech sources from audio mixtures recorded by a microphone array. The problem is challenging because it is a blind inverse problem, i.e., the microphone array geometry, the room impulse response (RIR), and the speech sources, are all unknown. We propose ArrayDPS to solve the BSS problem in an unsupervised, array-agnostic, and generative manner. The core idea builds on diffusion posterior sampling (DPS), but unlike DPS where the likelihood is tractable, ArrayDPS must approximate the likelihood by formulating a separate optimization problem. The solution to the optimization approximates room acoustics and the relative transfer functions between microphones. These approximations, along with the diffusion priors, iterate through the ArrayDPS sampling process and ultimately yield separated voice sources. We only need a simple single-speaker speech diffusion model as a prior along with the mixtures recorded at the microphones; no microphone array information is necessary. Evaluation results show that ArrayDPS outperforms all baseline unsupervised methods while being comparable to supervised methods in terms of SDR. Audio demos are provided at: https://arraydps.github.io/ArrayDPSDemo/.
Unsupervised Blind Speech Separation with a Diffusion Prior
May 08, 2025Blind Speech Separation (BSS) aims to separate multiple speech sources from audio mixtures recorded by a microphone array. The problem is challenging because it is a blind inverse problem, i.e., the microphone array geometry, the room impulse response (RIR), and the speech sources, are all unknown. We propose ArrayDPS to solve the BSS problem in an unsupervised, array-agnostic, and generative manner. The core idea builds on diffusion posterior sampling (DPS), but unlike DPS where the likelihood is tractable, ArrayDPS must approximate the likelihood by formulating a separate optimization problem. The solution to the optimization approximates room acoustics and the relative transfer functions between microphones. These approximations, along with the diffusion priors, iterate through the ArrayDPS sampling process and ultimately yield separated voice sources. We only need a simple single-speaker speech diffusion model as a prior along with the mixtures recorded at the microphones; no microphone array information is necessary. Evaluation results show that ArrayDPS outperforms all baseline unsupervised methods while being comparable to supervised methods in terms of SDR. Audio demos are provided at: https://arraydps.github.io/ArrayDPSDemo/.
SyncDiff: Diffusion-based Talking Head Synthesis with Bottlenecked Temporal Visual Prior for Improved Synchronization
Mar 17, 2025



Talking head synthesis, also known as speech-to-lip synthesis, reconstructs the facial motions that align with the given audio tracks. The synthesized videos are evaluated on mainly two aspects, lip-speech synchronization and image fidelity. Recent studies demonstrate that GAN-based and diffusion-based models achieve state-of-the-art (SOTA) performance on this task, with diffusion-based models achieving superior image fidelity but experiencing lower synchronization compared to their GAN-based counterparts. To this end, we propose SyncDiff, a simple yet effective approach to improve diffusion-based models using a temporal pose frame with information bottleneck and facial-informative audio features extracted from AVHuBERT, as conditioning input into the diffusion process. We evaluate SyncDiff on two canonical talking head datasets, LRS2 and LRS3 for direct comparison with other SOTA models. Experiments on LRS2/LRS3 datasets show that SyncDiff achieves a synchronization score 27.7%/62.3% relatively higher than previous diffusion-based methods, while preserving their high-fidelity characteristics.
Just ASR + LLM? A Study on Speech Large Language Models' Ability to Identify and Understand Speaker in Spoken Dialogue
Sep 07, 2024



In recent years, we have observed a rapid advancement in speech language models (SpeechLLMs), catching up with humans' listening and reasoning abilities. Remarkably, SpeechLLMs have demonstrated impressive spoken dialogue question-answering (SQA) performance in benchmarks like Gaokao, the English listening test of the college entrance exam in China, which seemingly requires understanding both the spoken content and voice characteristics of speakers in a conversation. However, after carefully examining Gaokao's questions, we find the correct answers to many questions can be inferred from the conversation context alone without identifying the speaker asked in the question. Our evaluation of state-of-the-art models Qwen-Audio and WavLLM in both Gaokao and our proposed "What Do You Like?" dataset shows a significantly higher accuracy in these context-based questions than in identity-critical questions, which can only be answered correctly with correct speaker identification. Our results and analysis suggest that when solving SQA, the current SpeechLLMs exhibit limited speaker awareness from the audio and behave similarly to an LLM reasoning from the conversation transcription without sound. We propose that our definitions and automated classification of context-based and identity-critical questions could offer a more accurate evaluation framework of SpeechLLMs in SQA tasks.
PromptRE: Weakly-Supervised Document-Level Relation Extraction via Prompting-Based Data Programming
Oct 13, 2023



Relation extraction aims to classify the relationships between two entities into pre-defined categories. While previous research has mainly focused on sentence-level relation extraction, recent studies have expanded the scope to document-level relation extraction. Traditional relation extraction methods heavily rely on human-annotated training data, which is time-consuming and labor-intensive. To mitigate the need for manual annotation, recent weakly-supervised approaches have been developed for sentence-level relation extraction while limited work has been done on document-level relation extraction. Weakly-supervised document-level relation extraction faces significant challenges due to an imbalanced number "no relation" instances and the failure of directly probing pretrained large language models for document relation extraction. To address these challenges, we propose PromptRE, a novel weakly-supervised document-level relation extraction method that combines prompting-based techniques with data programming. Furthermore, PromptRE incorporates the label distribution and entity types as prior knowledge to improve the performance. By leveraging the strengths of both prompting and data programming, PromptRE achieves improved performance in relation classification and effectively handles the "no relation" problem. Experimental results on ReDocRED, a benchmark dataset for document-level relation extraction, demonstrate the superiority of PromptRE over baseline approaches.
Dual-path Attention is All You Need for Audio-Visual Speech Extraction
Jul 09, 2022
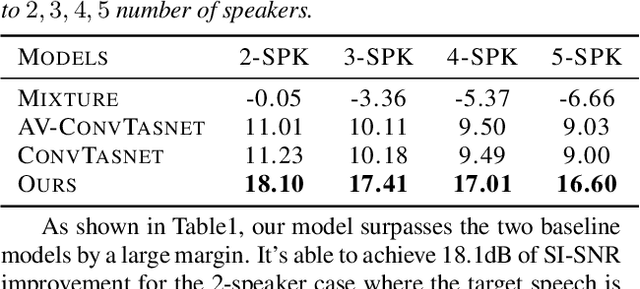
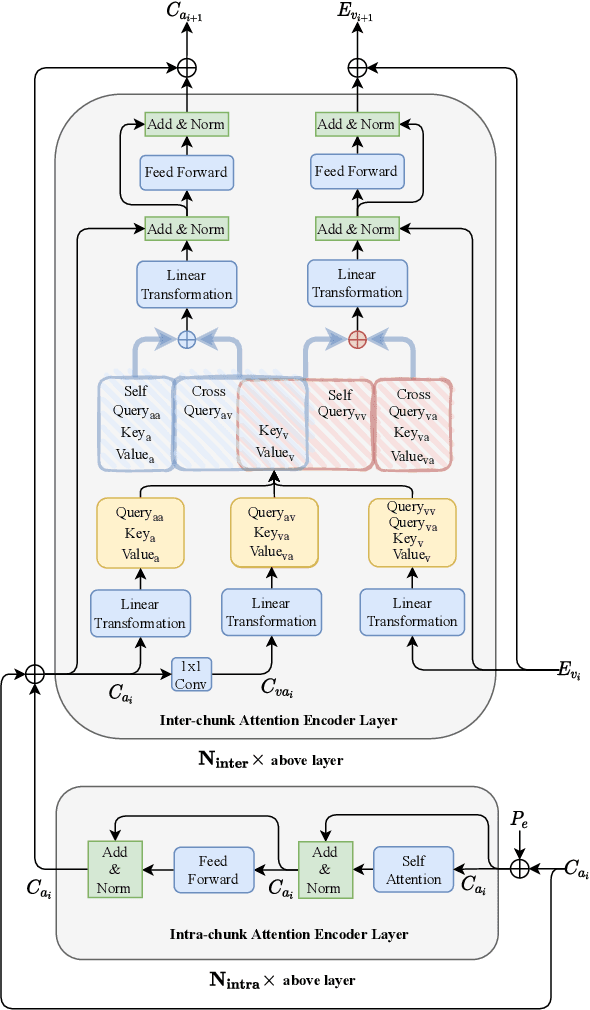
Audio-visual target speech extraction, which aims to extract a certain speaker's speech from the noisy mixture by looking at lip movements, has made significant progress combining time-domain speech separation models and visual feature extractors (CNN). One problem of fusing audio and video information is that they have different time resolutions. Most current research upsamples the visual features along the time dimension so that audio and video features are able to align in time. However, we believe that lip movement should mostly contain long-term, or phone-level information. Based on this assumption, we propose a new way to fuse audio-visual features. We observe that for DPRNN \cite{dprnn}, the interchunk dimension's time resolution could be very close to the time resolution of video frames. Like \cite{sepformer}, the LSTM in DPRNN is replaced by intra-chunk and inter-chunk self-attention, but in the proposed algorithm, inter-chunk attention incorporates the visual features as an additional feature stream. This prevents the upsampling of visual cues, resulting in more efficient audio-visual fusion. The result shows we achieve superior results compared with other time-domain based audio-visual fusion models.