 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsodyLM: Uncovering the Emerging Prosody Processing Capabilities in Speech Language Models
Jul 27, 2025Speech language models refer to language models with speech processing and understanding capabilities. One key desirable capability for speech language models is the ability to capture the intricate interdependency between content and prosody. The existing mainstream paradigm of training speech language models, which converts speech into discrete tokens before feeding them into LLMs, is sub-optimal in learning prosody information -- we find that the resulting LLMs do not exhibit obvious emerging prosody processing capabilities via pre-training alone. To overcome this, we propose ProsodyLM, which introduces a simple tokenization scheme amenable to learning prosody. Each speech utterance is first transcribed into text, followed by a sequence of word-level prosody tokens. Compared with conventional speech tokenization schemes, the proposed tokenization scheme retains more complete prosody information, and is more understandable to text-based LLMs. We find that ProsodyLM can learn surprisingly diverse emerging prosody processing capabilities through pre-training alone, ranging from harnessing the prosody nuances in generated speech, such as contrastive focus, understanding emotion and stress in an utterance, to maintaining prosody consistency in long contexts.
Continuous Speech Synthesis using per-token Latent Diffusion
Oct 21, 2024



The success of autoregressive transformer models with discrete tokens has inspired quantization-based approaches for continuous modalities, though these often limit reconstruction quality. We therefore introduce SALAD, a per-token latent diffusion model for zero-shot text-to-speech, that operates on continuous representations. SALAD builds upon the recently proposed expressive diffusion head for image generation, and extends it to generate variable-length outputs. Our approach utilizes semantic tokens for providing contextual information and determining the stopping condition. We suggest three continuous variants for our method, extending popular discrete speech synthesis techniques. Additionally, we implement discrete baselines for each variant and conduct a comparative analysis of discrete versus continuous speech modeling techniques. Our results demonstrate that both continuous and discrete approaches are highly competent, and that SALAD achieves a superior intelligibility score while obtaining speech quality and speaker similarity on par with the ground-truth audio.
Low Bitrate High-Quality RVQGAN-based Discrete Speech Tokenizer
Oct 10, 2024



Discrete Audio codecs (or audio tokenizers) have recently regained interest due to the ability of Large Language Models (LLMs) to learn their compressed acoustic representations. Various publicly available trainable discrete tokenizers recently demonstrated impressive results for audio tokenization, yet they mostly require high token rates to gain high-quality reconstruction. In this study, we fine-tuned an open-source general audio RVQGAN model using diverse open-source speech data, considering various recording conditions and quality levels. The resulting wideband (24kHz) speech-only model achieves speech reconstruction, which is nearly indistinguishable from PCM (pulse-code modulation) with a rate of 150-300 tokens per second (1500-3000 bps). The evaluation used comprehensive English speech data encompassing different recording conditions, including studio settings. Speech samples are made publicly available in http://ibm.biz/IS24SpeechRVQ . The model is officially released in https://huggingface.co/ibm/DAC.speech.v1.0
* You can download the model from https://huggingface.co/ibm/DAC.speech.v1.0
Speak While You Think: Streaming Speech Synthesis During Text Generation
Sep 20, 2023



Large Language Models (LLMs) demonstrate impressive capabilities, yet interaction with these models is mostly facilitated through text. Using Text-To-Speech to synthesize LLM outputs typically results in notable latency, which is impractical for fluent voice conversations. We propose LLM2Speech, an architecture to synthesize speech while text is being generated by an LLM which yields significant latency reduction. LLM2Speech mimics the predictions of a non-streaming teacher model while limiting the exposure to future context in order to enable streaming. It exploits the hidden embeddings of the LLM, a by-product of the text generation that contains informative semantic context. Experimental results show that LLM2Speech maintains the teacher's quality while reducing the latency to enable natural conversations.
A Neural TTS System with Parallel Prosody Transfer from Unseen Speakers
Sep 20, 2023



Modern neural TTS systems are capable of generating natural and expressive speech when provided with sufficient amounts of training data. Such systems can be equipped with prosody-control functionality, allowing for more direct shaping of the speech output at inference time. In some TTS applications, it may be desirable to have an option that guides the TTS system with an ad-hoc speech recording exemplar to impose an implicit fine-grained, user-preferred prosodic realization for certain input prompts. In this work we present a first-of-its-kind neural TTS system equipped with such functionality to transfer the prosody from a parallel text recording from an unseen speaker. We demonstrate that the proposed system can precisely transfer the speech prosody from novel speakers to various trained TTS voices with no quality degradation, while preserving the target TTS speakers' identity, as evaluated by a set of subjective listening experiments.
* Presented at Interspeech 2023
Transplantation of Conversational Speaking Style with Interjections in Sequence-to-Sequence Speech Synthesis
Jul 25, 2022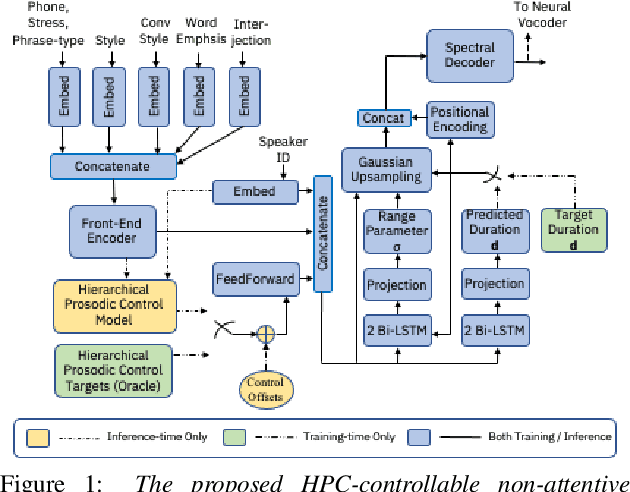

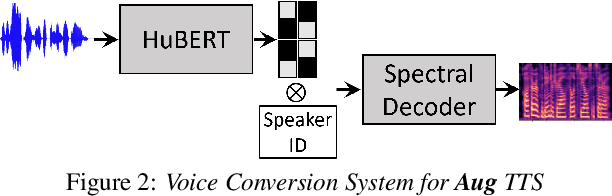

Sequence-to-Sequence Text-to-Speech architectures that directly generate low level acoustic features from phonetic sequences are known to produce natural and expressive speech when provided with adequate amounts of training data. Such systems can learn and transfer desired speaking styles from one seen speaker to another (in multi-style multi-speaker settings), which is highly desirable for creating scalable and customizable Human-Computer Interaction systems. In this work we explore one-to-many style transfer from a dedicated single-speaker conversational corpus with style nuances and interjections. We elaborate on the corpus design and explore the feasibility of such style transfer when assisted with Voice-Conversion-based data augmentation. In a set of subjective listening experiments, this approach resulted in high-fidelity style transfer with no quality degradation. However, a certain voice persona shift was observed, requiring further improvements in voice conversion.
Supervised and Unsupervised Approaches for Controlling Narrow Lexical Focus in Sequence-to-Sequence Speech Synthesis
Jan 25, 2021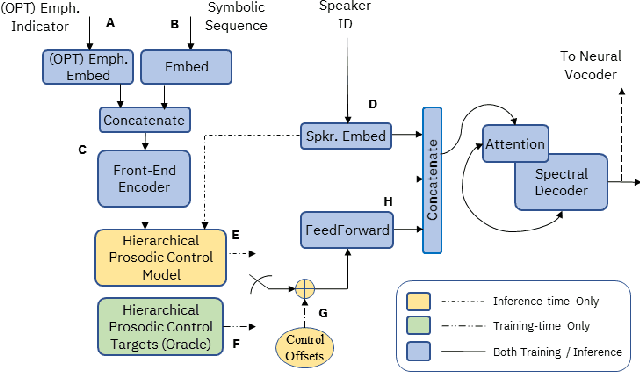
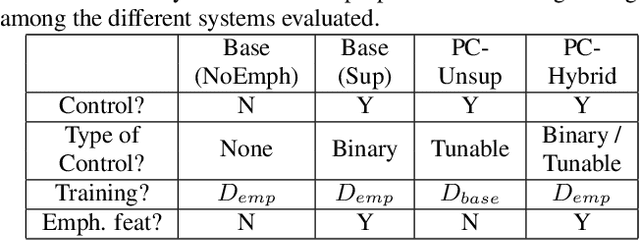
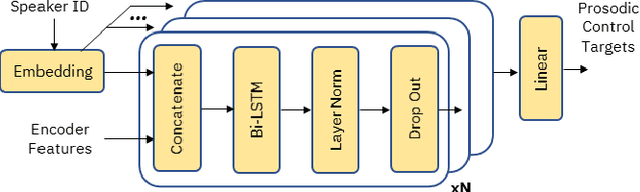
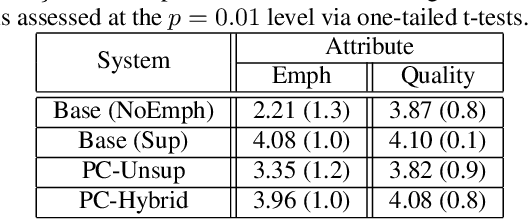
Although Sequence-to-Sequence (S2S) architectures have become state-of-the-art in speech synthesis, capable of generating outputs that approach the perceptual quality of natural samples, they are limited by a lack of flexibility when it comes to controlling the output. In this work we present a framework capable of controlling the prosodic output via a set of concise, interpretable, disentangled parameters. We apply this framework to the realization of emphatic lexical focus, proposing a variety of architectures designed to exploit different levels of supervision based on the availability of labeled resources. We evaluate these approaches via listening tests that demonstrate we are able to successfully realize controllable focus while maintaining the same, or higher, naturalness over an established baseline, and we explore how the different approaches compare when synthesizing in a target voice with or without labeled data.