 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Counterfactual Learning for Audio-Visual Segmentation
Jul 28, 2025



Audio-visual segmentation (AVS) aims to segment objects in videos based on audio cues. Existing AVS methods are primarily designed to enhance interaction efficiency but pay limited attention to modality representation discrepancies and imbalances. To overcome this, we propose the implicit counterfactual framework (ICF) to achieve unbiased cross-modal understanding. Due to the lack of semantics, heterogeneous representations may lead to erroneous matches, especially in complex scenes with ambiguous visual content or interference from multiple audio sources. We introduce the multi-granularity implicit text (MIT) involving video-, segment- and frame-level as the bridge to establish the modality-shared space, reducing modality gaps and providing prior guidance. Visual content carries more information and typically dominates, thereby marginalizing audio features in the decision-making. To mitigate knowledge preference, we propose the semantic counterfactual (SC) to learn orthogonal representations in the latent space, generating diverse counterfactual samples, thus avoiding biases introduced by complex functional designs and explicit modifications of text structures or attributes. We further formulate the collaborative distribution-aware contrastive learning (CDCL), incorporating factual-counterfactual and inter-modality contrasts to align representations, promoting cohesion and decoupling. Extensive experiments on three public datasets validate that the proposed method achieves state-of-the-art performance.
Adapting Large VLMs with Iterative and Manual Instructions for Generative Low-light Enhancement
Jul 24, 2025Most existing low-light image enhancement (LLIE) methods rely on pre-trained model priors, low-light inputs, or both, while neglecting the semantic guidance available from normal-light images. This limitation hinders their effectiveness in complex lighting conditions. In this paper, we propose VLM-IMI, a novel framework that leverages large vision-language models (VLMs) with iterative and manual instructions (IMIs) for LLIE. VLM-IMI incorporates textual descriptions of the desired normal-light content as enhancement cues, enabling semantically informed restoration. To effectively integrate cross-modal priors, we introduce an instruction prior fusion module, which dynamically aligns and fuses image and text features, promoting the generation of detailed and semantically coherent outputs. During inference, we adopt an iterative and manual instruction strategy to refine textual instructions, progressively improving visual quality. This refinement enhances structural fidelity, semantic alignment, and the recovery of fine details under extremely low-light conditions. Extensive experiments across diverse scenarios demonstrate that VLM-IMI outperforms state-of-the-art methods in both quantitative metrics and perceptual quality. The source code is available at https://github.com/sunxiaoran01/VLM-IMI.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Multimodal Mathematical Reasoning with Diverse Solving Perspective
Jul 03, 2025



Recent progress in large-scale reinforcement learning (RL) has notably enhanced the reasoning capabilities of large language models (LLMs), especially in mathematical domains. However, current multimodal LLMs (MLLMs) for mathematical reasoning often rely on one-to-one image-text pairs and single-solution supervision, overlooking the diversity of valid reasoning perspectives and internal reflections. In this work, we introduce MathV-DP, a novel dataset that captures multiple diverse solution trajectories for each image-question pair, fostering richer reasoning supervision. We further propose Qwen-VL-DP, a model built upon Qwen-VL, fine-tuned with supervised learning and enhanced via group relative policy optimization (GRPO), a rule-based RL approach that integrates correctness discrimination and diversity-aware reward functions. Our method emphasizes learning from varied reasoning perspectives and distinguishing between correct yet distinct solutions. Extensive experiments on the MathVista's minitest and Math-V benchmarks demonstrate that Qwen-VL-DP significantly outperforms prior base MLLMs in both accuracy and generative diversity, highlighting the importance of incorporating diverse perspectives and reflective reasoning in multimodal mathematical reasoning.
Uncertainty-aware Reward Design Process
Jul 03, 2025Designing effective reward functions is a cornerstone of reinforcement learning (RL), yet it remains a challenging process due to the inefficiencies and inconsistencies inherent in conventional reward engineering methodologies. Recent advances have explored leveraging large language models (LLMs) to automate reward function design. However, their suboptimal performance in numerical optimization often yields unsatisfactory reward quality, while the evolutionary search paradigm demonstrates inefficient utilization of simulation resources, resulting in prohibitively lengthy design cycles with disproportionate computational overhead. To address these challenges, we propose the Uncertainty-aware Reward Design Process (URDP), a novel framework that integrates large language models to streamline reward function design and evaluation in RL environments. URDP quantifies candidate reward function uncertainty based on self-consistency analysis, enabling simulation-free identification of ineffective reward components while discovering novel reward components. Furthermore, we introduce uncertainty-aware Bayesian optimization (UABO), which incorporates uncertainty estimation to significantly enhance hyperparameter configuration efficiency. Finally, we construct a bi-level optimization architecture by decoupling the reward component optimization and the hyperparameter tuning. URDP orchestrates synergistic collaboration between the reward logic reasoning of the LLMs and the numerical optimization strengths of the Bayesian Optimization. We conduct a comprehensive evaluation of URDP across 35 diverse tasks spanning three benchmark environments. Our experimental results demonstrate that URDP not only generates higher-quality reward functions but also achieves significant improvements in the efficiency of automated reward design compared to existing approaches.
PanTS: The Pancreatic Tumor Segmentation Dataset
Jul 02, 2025PanTS is a large-scale, multi-institutional dataset curated to advance research in pancreatic CT analysis. It contains 36,390 CT scans from 145 medical centers, with expert-validated, voxel-wise annotations of over 993,000 anatomical structures, covering pancreatic tumors, pancreas head, body, and tail, and 24 surrounding anatomical structures such as vascular/skeletal structures and abdominal/thoracic organs. Each scan includes metadata such as patient age, sex, diagnosis, contrast phase, in-plane spacing, slice thickness, etc. AI models trained on PanTS achieve significantly better performance in pancreatic tumor detection, localization, and segmentation compared to those trained on existing public datasets. Our analysis indicates that these gains are directly attributable to the 16x larger-scale tumor annotations and indirectly supported by the 24 additional surrounding anatomical structures. As the largest and most comprehensive resource of its kind, PanTS offers a new benchmark for developing and evaluating AI models in pancreatic CT analysis.
Lightweight Task-Oriented Semantic Communication Empowered by Large-Scale AI Models
Jun 16, 2025Recent studies have focused on leveraging large-scale artificial intelligence (LAI) models to improve semantic representation and compression capabilities. However, the substantial computational demands of LAI models pose significant challenges for real-time communication scenarios. To address this, this paper proposes utilizing knowledge distillation (KD) techniques to extract and condense knowledge from LAI models, effectively reducing model complexity and computation latency. Nevertheless, the inherent complexity of LAI models leads to prolonged inference times during distillation, while their lack of channel awareness compromises the distillation performance. These limitations make standard KD methods unsuitable for task-oriented semantic communication scenarios. To address these issues, we propose a fast distillation method featuring a pre-stored compression mechanism that eliminates the need for repetitive inference, significantly improving efficiency. Furthermore, a channel adaptive module is incorporated to dynamically adjust the transmitted semantic information based on varying channel conditions, enhancing communication reliability and adaptability. In addition, an information bottleneck-based loss function is derived to guide the fast distillation process. Simulation results verify that the proposed scheme outperform baselines in term of task accuracy, model size, computation latency, and training data requirements.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
STOAT: Spatial-Temporal Probabilistic Causal Inference Network
Jun 12, 2025Spatial-temporal causal time series (STC-TS) involve region-specific temporal observations driven by causally relevant covariates and interconnected across geographic or network-based spaces. Existing methods often model spatial and temporal dynamics independently and overlook causality-driven probabilistic forecasting, limiting their predictive power. To address this, we propose STOAT (Spatial-Temporal Probabilistic Causal Inference Network), a novel framework for probabilistic forecasting in STC-TS. The proposed method extends a causal inference approach by incorporating a spatial relation matrix that encodes interregional dependencies (e.g. proximity or connectivity), enabling spatially informed causal effect estimation. The resulting latent series are processed by deep probabilistic models to estimate the parameters of the distributions, enabling calibrated uncertainty modeling. We further explore multiple output distributions (e.g., Gaussian, Student's-$t$, Laplace) to capture region-specific variability. Experiments on COVID-19 data across six countries demonstrate that STOAT outperforms state-of-the-art probabilistic forecasting models (DeepAR, DeepVAR, Deep State Space Model, etc.) in key metrics, particularly in regions with strong spatial dependencies. By bridging causal inference and geospatial probabilistic forecasting, STOAT offers a generalizable framework for complex spatial-temporal tasks, such as epidemic management.
Unleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation
Jun 06, 2025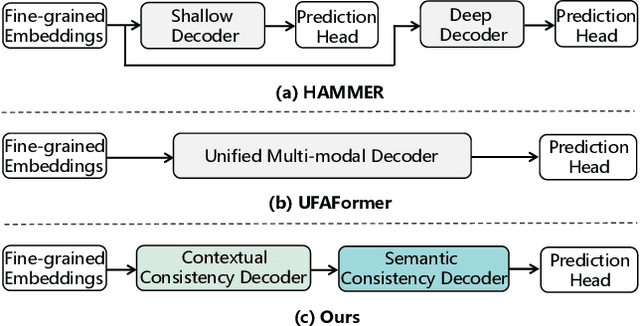
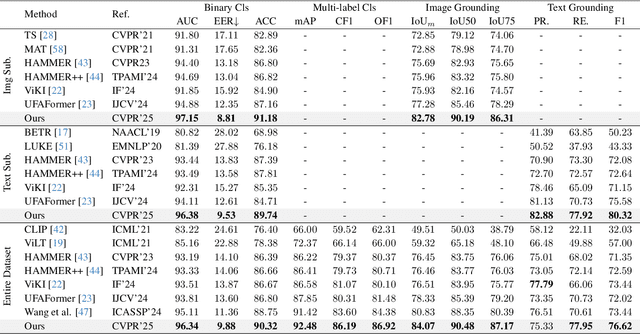
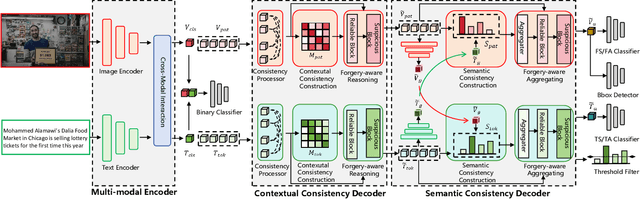
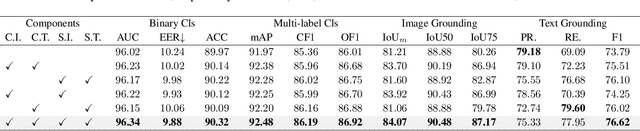
To tackle the threat of fake news, the task of detecting and grounding multi-modal media manipulation DGM4 has received increasing attention. However, most state-of-the-art methods fail to explore the fine-grained consistency within local content, usually resulting in an inadequate perception of detailed forgery and unreliable results. In this paper, we propose a novel approach named Contextual-Semantic Consistency Learning (CSCL) to enhance the fine-grained perception ability of forgery for DGM4. Two branches for image and text modalities are established, each of which contains two cascaded decoders, i.e., Contextual Consistency Decoder (CCD) and Semantic Consistency Decoder (SCD), to capture within-modality contextual consistency and across-modality semantic consistency, respectively. Both CCD and SCD adhere to the same criteria for capturing fine-grained forgery details. To be specific, each module first constructs consistency features by leveraging additional supervision from the heterogeneous information of each token pair. Then, the forgery-aware reasoning or aggregating is adopted to deeply seek forgery cues based on the consistency features. Extensive experiments on DGM4 datasets prove that CSCL achieves new state-of-the-art performance, especially for the results of grounding manipulated content. Codes and weights are avaliable at https://github.com/liyih/CSCL.