 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Liu
Prompt-enhanced Hierarchical Transformer Elevating Cardiopulmonary Resuscitation Instruction via Temporal Action Segmentation
Aug 31, 2023
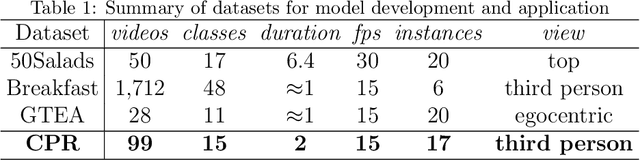
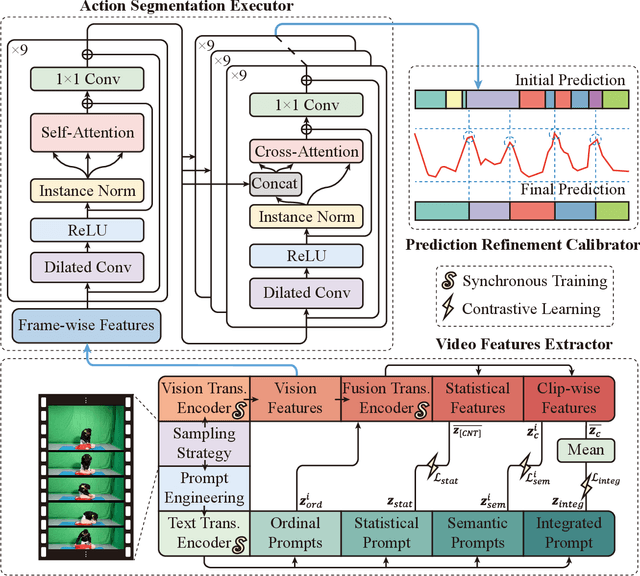
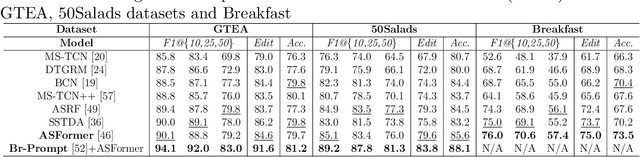

The vast majority of people who suffer unexpected cardiac arrest are performed cardiopulmonary resuscitation (CPR) by passersby in a desperate attempt to restore life, but endeavors turn out to be fruitless on account of disqualification. Fortunately, many pieces of research manifest that disciplined training will help to elevate the success rate of resuscitation, which constantly desires a seamless combination of novel techniques to yield further advancement. To this end, we collect a custom CPR video dataset in which trainees make efforts to behave resuscitation on mannequins independently in adherence to approved guidelines, thereby devising an auxiliary toolbox to assist supervision and rectification of intermediate potential issues via modern deep learning methodologies. Our research empirically views this problem as a temporal action segmentation (TAS) task in computer vision, which aims to segment an untrimmed video at a frame-wise level. Here, we propose a Prompt-enhanced hierarchical Transformer (PhiTrans) that integrates three indispensable modules, including a textual prompt-based Video Features Extractor (VFE), a transformer-based Action Segmentation Executor (ASE), and a regression-based Prediction Refinement Calibrator (PRC). The backbone of the model preferentially derives from applications in three approved public datasets (GTEA, 50Salads, and Breakfast) collected for TAS tasks, which accounts for the excavation of the segmentation pipeline on the CPR dataset. In general, we unprecedentedly probe into a feasible pipeline that genuinely elevates the CPR instruction qualification via action segmentation in conjunction with cutting-edge deep learning techniques. Associated experiments advocate our implementation with multiple metrics surpassing 91.0%.
ASTER: Automatic Speech Recognition System Accessibility Testing for Stutterers
Aug 30, 2023
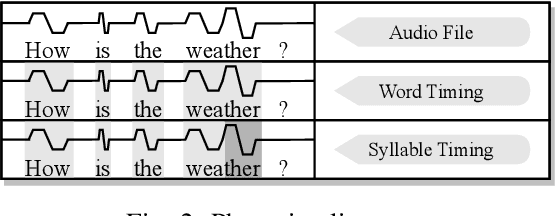
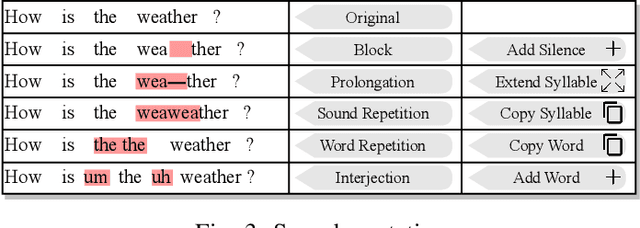
The popularity of automatic speech recognition (ASR) systems nowadays leads to an increasing need for improving their accessibility. Handling stuttering speech is an important feature for accessible ASR systems. To improve the accessibility of ASR systems for stutterers, we need to expose and analyze the failures of ASR systems on stuttering speech. The speech datasets recorded from stutterers are not diverse enough to expose most of the failures. Furthermore, these datasets lack ground truth information about the non-stuttered text, rendering them unsuitable as comprehensive test suites. Therefore, a methodology for generating stuttering speech as test inputs to test and analyze the performance of ASR systems is needed. However, generating valid test inputs in this scenario is challenging. The reason is that although the generated test inputs should mimic how stutterers speak, they should also be diverse enough to trigger more failures. To address the challenge, we propose ASTER, a technique for automatically testing the accessibility of ASR systems. ASTER can generate valid test cases by injecting five different types of stuttering. The generated test cases can both simulate realistic stuttering speech and expose failures in ASR systems. Moreover, ASTER can further enhance the quality of the test cases with a multi-objective optimization-based seed updating algorithm. We implemented ASTER as a framework and evaluated it on four open-source ASR models and three commercial ASR systems. We conduct a comprehensive evaluation of ASTER and find that it significantly increases the word error rate, match error rate, and word information loss in the evaluated ASR systems. Additionally, our user study demonstrates that the generated stuttering audio is indistinguishable from real-world stuttering audio clips.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023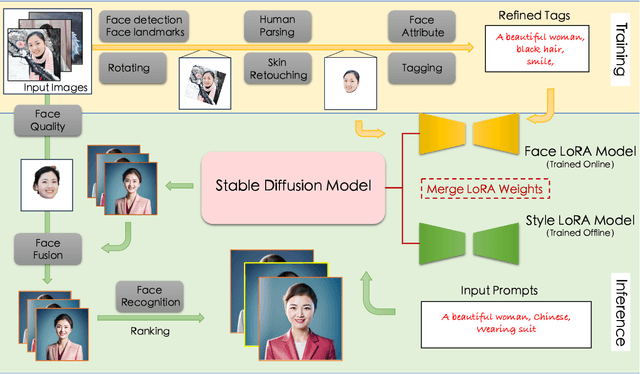

Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
Position-Enhanced Visual Instruction Tuning for Multimodal Large Language Models
Aug 25, 2023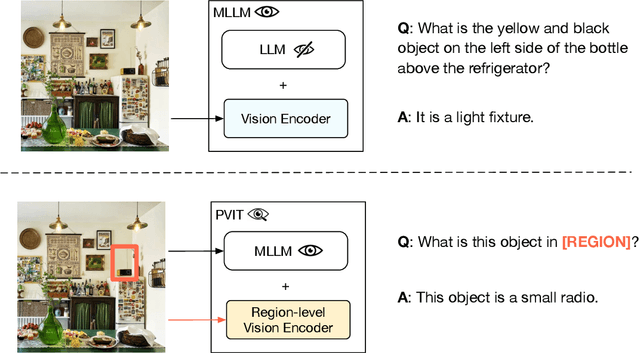
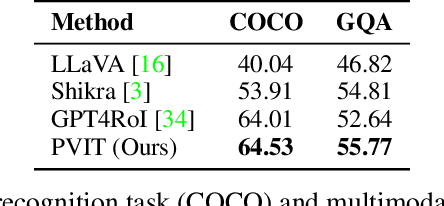
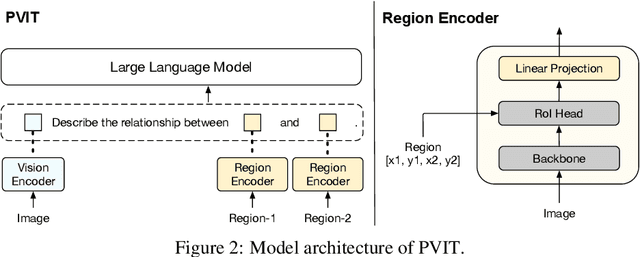

Recently, Multimodal Large Language Models (MLLMs) that enable Large Language Models (LLMs) to interpret images through visual instruction tuning have achieved significant success. However, existing visual instruction tuning methods only utilize image-language instruction data to align the language and image modalities, lacking a more fine-grained cross-modal alignment. In this paper, we propose Position-enhanced Visual Instruction Tuning (PVIT), which extends the functionality of MLLMs by integrating an additional region-level vision encoder. This integration promotes a more detailed comprehension of images for the MLLM. In addition, to efficiently achieve a fine-grained alignment between the vision modules and the LLM, we design multiple data generation strategies to construct an image-region-language instruction dataset. Finally, we present both quantitative experiments and qualitative analysis that demonstrate the superiority of the proposed model. Code and data will be released at https://github.com/THUNLP-MT/PVIT.
Physics-Inspired Neural Graph ODE for Long-term Dynamical Simulation
Aug 25, 2023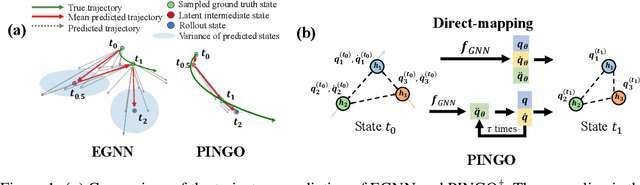
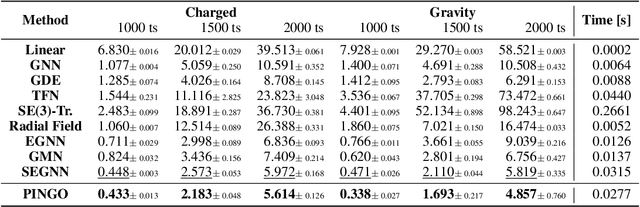
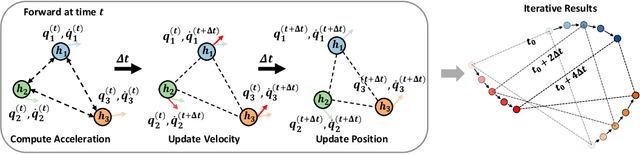
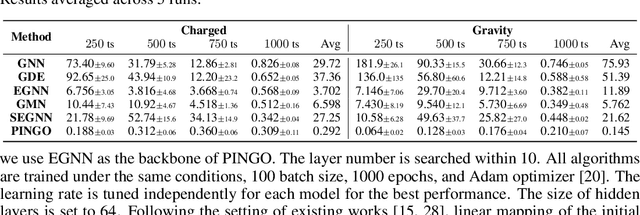
Simulating and modeling the long-term dynamics of multi-object physical systems is an essential and challenging task. Current studies model the physical systems utilizing Graph Neural Networks (GNNs) with equivariant properties. Specifically, they model the dynamics as a sequence of discrete states with a fixed time interval and learn a direct mapping for all the two adjacent states. However, this direct mapping overlooks the continuous nature between the two states. Namely, we have verified that there are countless possible trajectories between two discrete dynamic states in current GNN-based direct mapping models. This issue greatly hinders the model generalization ability, leading to poor performance of the long-term simulation. In this paper, to better model the latent trajectory through discrete supervision signals, we propose a Physics-Inspired Neural Graph ODE (PINGO) algorithm. In PINGO, to ensure the uniqueness of the trajectory, we construct a Physics-Inspired Neural ODE framework to update the latent trajectory. Meanwhile, to effectively capture intricate interactions among objects, we use a GNN-based model to parameterize Neural ODE in a plug-and-play manner. Furthermore, we prove that the discrepancy between the learned trajectory of PIGNO and the true trajectory can be theoretically bounded. Extensive experiments verify our theoretical findings and demonstrate that our model yields an order-of-magnitude improvement over the state-of-the-art baselines, especially on long-term predictions and roll-out errors.
Towards CausalGPT: A Multi-Agent Approach for Faithful Knowledge Reasoning via Promoting Causal Consistency in LLMs
Aug 23, 2023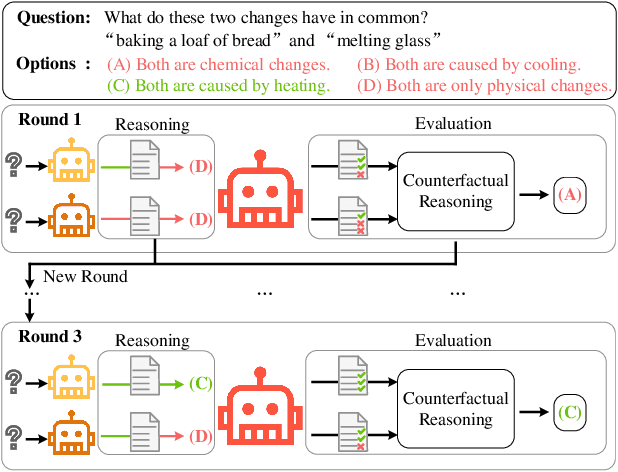
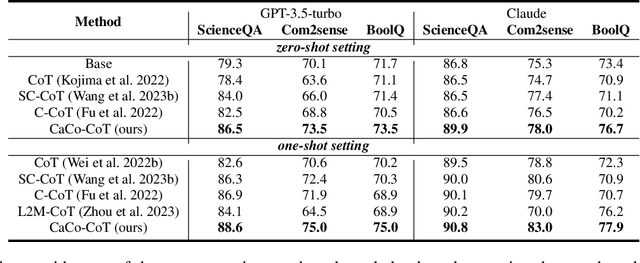
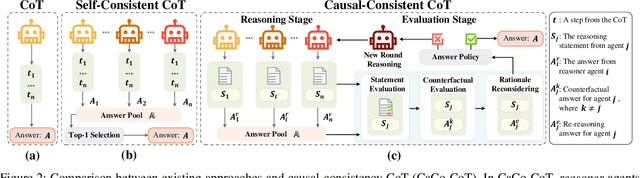
Despite advancements in LLMs, knowledge-based reasoning remains a longstanding issue due to the fragility of knowledge recall and inference. Existing methods primarily encourage LLMs to autonomously plan and solve problems or to extensively sample reasoning chains without addressing the conceptual and inferential fallacies. Attempting to alleviate inferential fallacies and drawing inspiration from multi-agent collaboration, we present a framework to increase faithfulness and causality for knowledge-based reasoning. Specifically, we propose to employ multiple intelligent agents (i.e., reasoner and causal evaluator) to work collaboratively in a reasoning-and-consensus paradigm for elevated reasoning faithfulness. The reasoners focus on providing solutions with human-like causality to solve open-domain problems. On the other hand, the causal evaluator agent scrutinizes if the answer in a solution is causally deducible from the question and vice versa, with a counterfactual answer replacing the original. According to the extensive and comprehensive evaluations on a variety of knowledge reasoning tasks (e.g., science question answering and commonsense reasoning), our framework outperforms all compared state-of-the-art approaches by large margins.
Protect Federated Learning Against Backdoor Attacks via Data-Free Trigger Generation
Aug 22, 2023
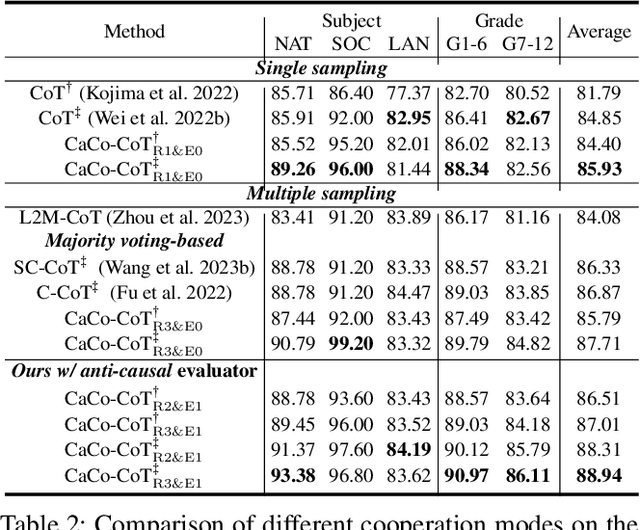
As a distributed machine learning paradigm, Federated Learning (FL) enables large-scale clients to collaboratively train a model without sharing their raw data. However, due to the lack of data auditing for untrusted clients, FL is vulnerable to poisoning attacks, especially backdoor attacks. By using poisoned data for local training or directly changing the model parameters, attackers can easily inject backdoors into the model, which can trigger the model to make misclassification of targeted patterns in images. To address these issues, we propose a novel data-free trigger-generation-based defense approach based on the two characteristics of backdoor attacks: i) triggers are learned faster than normal knowledge, and ii) trigger patterns have a greater effect on image classification than normal class patterns. Our approach generates the images with newly learned knowledge by identifying the differences between the old and new global models, and filters trigger images by evaluating the effect of these generated images. By using these trigger images, our approach eliminates poisoned models to ensure the updated global model is benign. Comprehensive experiments demonstrate that our approach can defend against almost all the existing types of backdoor attacks and outperform all the seven state-of-the-art defense methods with both IID and non-IID scenarios. Especially, our approach can successfully defend against the backdoor attack even when 80\% of the clients are malicious.
When Less is Enough: Positive and Unlabeled Learning Model for Vulnerability Detection
Aug 21, 2023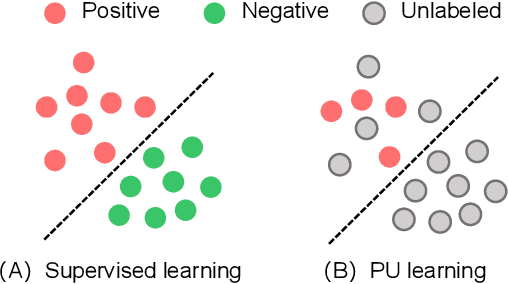
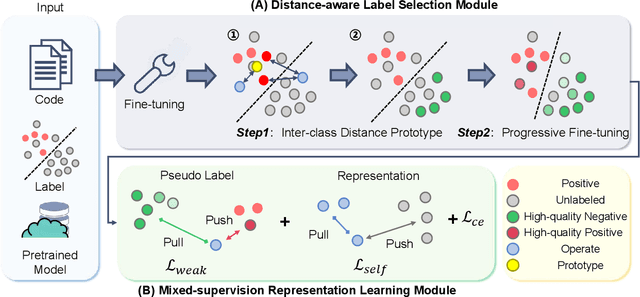

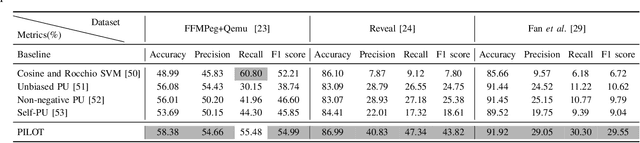
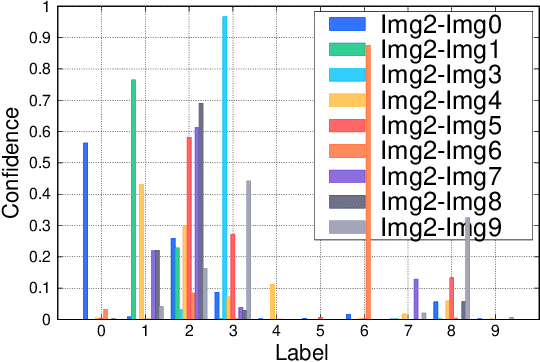
Automated code vulnerability detection has gained increasing attention in recent years. The deep learning (DL)-based methods, which implicitly learn vulnerable code patterns, have proven effective in vulnerability detection. The performance of DL-based methods usually relies on the quantity and quality of labeled data. However, the current labeled data are generally automatically collected, such as crawled from human-generated commits, making it hard to ensure the quality of the labels. Prior studies have demonstrated that the non-vulnerable code (i.e., negative labels) tends to be unreliable in commonly-used datasets, while vulnerable code (i.e., positive labels) is more determined. Considering the large numbers of unlabeled data in practice, it is necessary and worth exploring to leverage the positive data and large numbers of unlabeled data for more accurate vulnerability detection. In this paper, we focus on the Positive and Unlabeled (PU) learning problem for vulnerability detection and propose a novel model named PILOT, i.e., PositIve and unlabeled Learning mOdel for vulnerability deTection. PILOT only learns from positive and unlabeled data for vulnerability detection. It mainly contains two modules: (1) A distance-aware label selection module, aiming at generating pseudo-labels for selected unlabeled data, which involves the inter-class distance prototype and progressive fine-tuning; (2) A mixed-supervision representation learning module to further alleviate the influence of noise and enhance the discrimination of representations.
TransFace: Calibrating Transformer Training for Face Recognition from a Data-Centric Perspective
Aug 20, 2023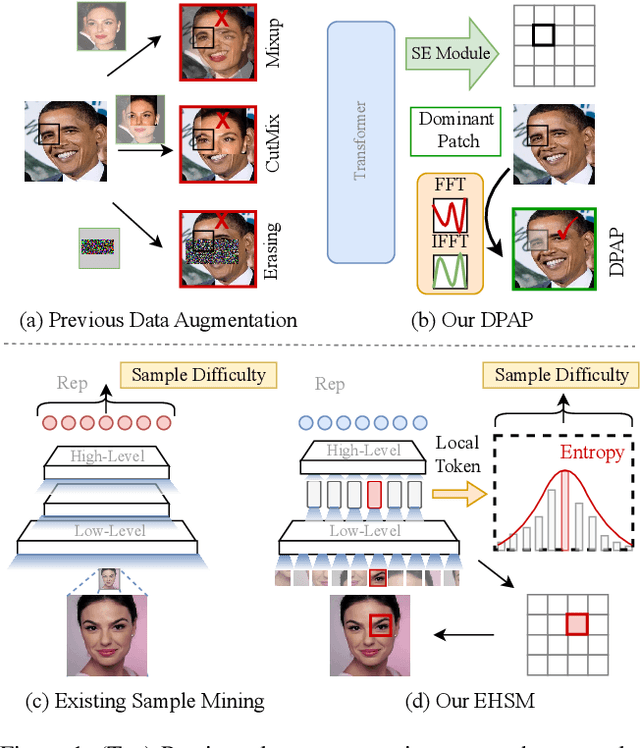
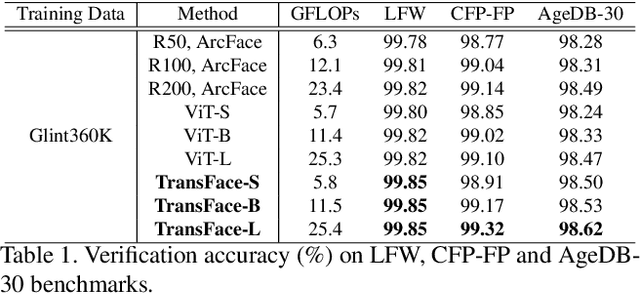
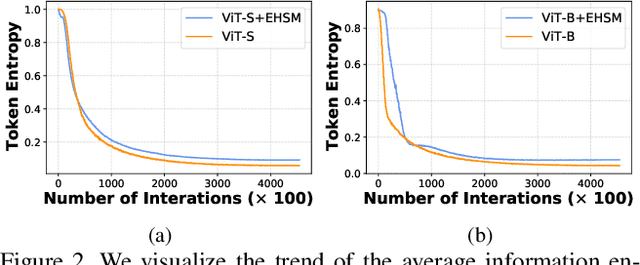
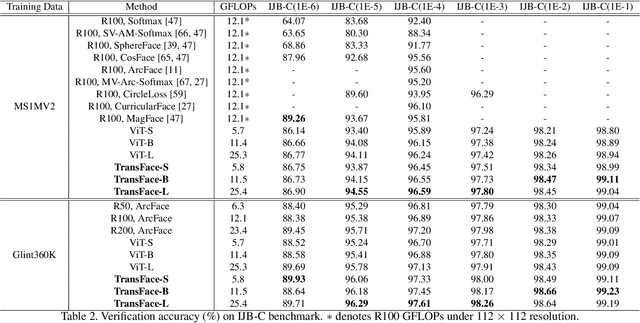
Vision Transformers (ViTs) have demonstrated powerful representation ability in various visual tasks thanks to their intrinsic data-hungry nature. However, we unexpectedly find that ViTs perform vulnerably when applied to face recognition (FR) scenarios with extremely large datasets. We investigate the reasons for this phenomenon and discover that the existing data augmentation approach and hard sample mining strategy are incompatible with ViTs-based FR backbone due to the lack of tailored consideration on preserving face structural information and leveraging each local token information. To remedy these problems, this paper proposes a superior FR model called TransFace, which employs a patch-level data augmentation strategy named DPAP and a hard sample mining strategy named EHSM. Specially, DPAP randomly perturbs the amplitude information of dominant patches to expand sample diversity, which effectively alleviates the overfitting problem in ViTs. EHSM utilizes the information entropy in the local tokens to dynamically adjust the importance weight of easy and hard samples during training, leading to a more stable prediction. Experiments on several benchmarks demonstrate the superiority of our TransFace. Code and models are available at https://github.com/DanJun6737/TransFace.
Microstructure-Empowered Stock Factor Extraction and Utilization
Aug 16, 2023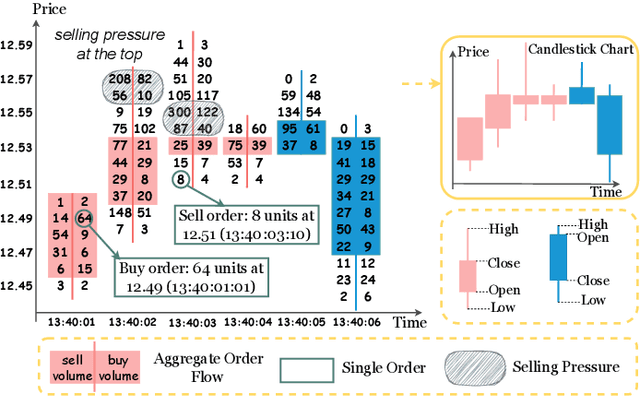
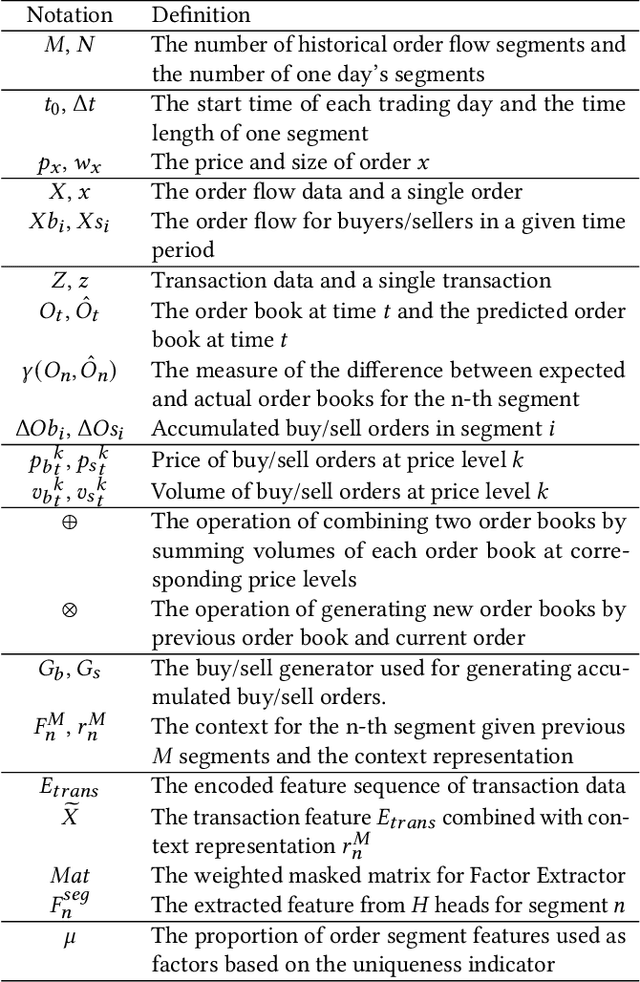
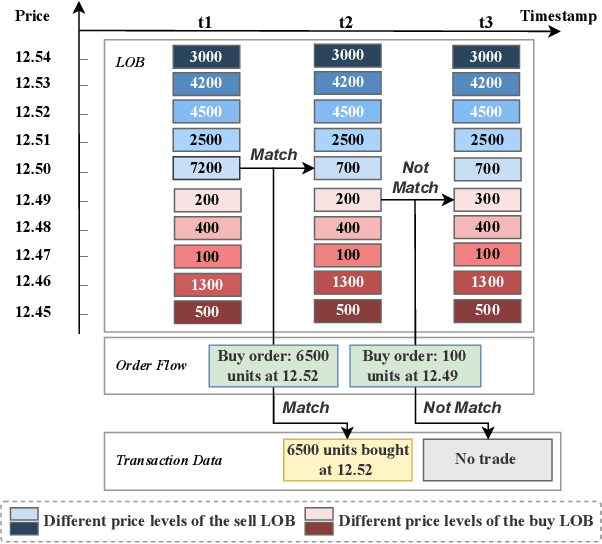
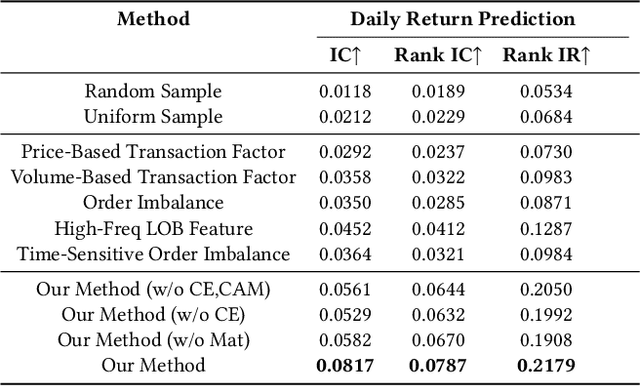
High-frequency quantitative investment is a crucial aspect of stock investment. Notably, order flow data plays a critical role as it provides the most detailed level of information among high-frequency trading data, including comprehensive data from the order book and transaction records at the tick level. The order flow data is extremely valuable for market analysis as it equips traders with essential insights for making informed decisions. However, extracting and effectively utilizing order flow data present challenges due to the large volume of data involved and the limitations of traditional factor mining techniques, which are primarily designed for coarser-level stock data. To address these challenges, we propose a novel framework that aims to effectively extract essential factors from order flow data for diverse downstream tasks across different granularities and scenarios. Our method consists of a Context Encoder and an Factor Extractor. The Context Encoder learns an embedding for the current order flow data segment's context by considering both the expected and actual market state. In addition, the Factor Extractor uses unsupervised learning methods to select such important signals that are most distinct from the majority within the given context. The extracted factors are then utilized for downstream tasks. In empirical studies, our proposed framework efficiently handles an entire year of stock order flow data across diverse scenarios, offering a broader range of applications compared to existing tick-level approaches that are limited to only a few days of stock data. We demonstrate that our method extracts superior factors from order flow data, enabling significant improvement for stock trend prediction and order execution tasks at the second and minute level.