 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Amplitude Anchors and Phase Priors for Target-Scarce Higher-Frequency Wave Prediction
May 26, 2026Learning-based surrogates have become increasingly effective for wave-field prediction, and neural operators in particular have shown strong performance within observed frequency regimes. However, higher-frequency prediction under scarce target supervision remains comparatively underexplored, especially in wave problems where higher-frequency data are substantially more expensive to simulate or measure than lower-frequency data. A central difficulty is that cross-frequency transfer is inherently asymmetric: coarse amplitude structure remains relatively stable across frequencies, whereas phase-sensitive oscillatory structure deteriorates much more rapidly as frequency increases. Motivated by this asymmetry, we propose APEX, Amplitude-anchored and Phase-prior-guided Enhancement from eXtrapolated coarse predictions, a framework for target-scarce higher-frequency wave-field prediction. A lower-frequency neural operator first provides a coarse prediction in the target-frequency regime, from which we retain only the amplitude as a transferable structural anchor. A conditional flow-matching enhancer then reconstructs the target higher-frequency field under the guidance of a Green's-function-inspired phase prior. Experiments on SimpleWave, Helmholtz, and Maxwell benchmarks show that APEX consistently outperforms direct lower-to-higher extrapolation, target-adapted operator, and joint generative baselines under limited target-frequency supervision. Our results suggest that reliable higher-frequency prediction of oscillatory wave fields should not rely on direct end-to-end transfer of the full complex field, but instead on explicitly reusing transferable coarse structure while separately recovering the missing oscillatory detail.
Performance Monitoring of Proton Exchange Membrane Water Electrolyzer by Transformers-Based Machine Learning Model
May 18, 2026Green hydrogen plays an essential role in decarbonization, with capacity projected to scale to 560 GW by 2030 (vs. 1.39 GW in 2023) in net-zero settings. Proton exchange membrane (PEM) electrolysis is one of the most promising technology routes to green hydrogen production, and real-time system health monitoring of PEM electrolyzers is essential for their scalable deployment. In lab settings, performance degradation can be characterized through electrochemical testing protocols by periodic pauses of normal operation. Such interruption is not practical for full-scale stack deployments, limiting system operators' ability to make real-time assessments of state-of-health (SoH). We present a machine learning (ML) framework that performs virtual electrochemical characterization during normal operation. The method uses an encoder-decoder transformer, conditioned on operational data, to reconstruct characterization outputs, focusing here on polarization curves. Inspired by patch-based sequence tokenization, we segment the inputs into patches and encode them to form meaningful tokens, which substantially improves learning efficiency. Across four longitudinal runs, lasting up to 478 hours on different test cells and loading cycles, the model accurately reconstructed polarization curves and achieved 10x reduction in mean squared error (MSE) compared to a vanilla transformer. This proof-of-concept demonstrates that ML models can enable continuous performance monitoring for PEM electrolyzers and that the encoder captures meaningful latent representations of SoH, opening up opportunities to derive interpretable indicators in future work.
SAGER: Self-Evolving User Policy Skills for Recommendation Agent
Apr 16, 2026Large language model (LLM) based recommendation agents personalize what they know through evolving per-user semantic memory, yet how they reason remains a universal, static system prompt shared identically across all users. This asymmetry is a fundamental bottleneck: when a recommendation fails, the agent updates its memory of user preferences but never interrogates the decision logic that produced the failure, leaving its reasoning process structurally unchanged regardless of how many mistakes it accumulates. To address this bottleneck, we propose SAGER (Self-Evolving Agent for Personalized Recommendation), the first recommendation agent framework in which each user is equipped with a dedicated policy skill, a structured natural-language document encoding personalized decision principles that evolves continuously through interaction. SAGER introduces a two-representation skill architecture that decouples a rich evolution substrate from a minimal inference-time injection, an incremental contrastive chain-of-thought engine that diagnoses reasoning flaws by contrasting accepted against unchosen items while preserving accumulated priors, and skill-augmented listwise reasoning that creates fine-grained decision boundaries where the evolved skill provides genuine discriminative value. Experiments on four public benchmarks demonstrate that SAGER achieves state-of-the-art performance, with gains orthogonal to memory accumulation, confirming that personalizing the reasoning process itself is a qualitatively distinct source of recommendation improvement.
When Bayesian Tensor Completion Meets Multioutput Gaussian Processes: Functional Universality and Rank Learning
Dec 25, 2025Functional tensor decomposition can analyze multi-dimensional data with real-valued indices, paving the path for applications in machine learning and signal processing. A limitation of existing approaches is the assumption that the tensor rank-a critical parameter governing model complexity-is known. However, determining the optimal rank is a non-deterministic polynomial-time hard (NP-hard) task and there is a limited understanding regarding the expressive power of functional low-rank tensor models for continuous signals. We propose a rank-revealing functional Bayesian tensor completion (RR-FBTC) method. Modeling the latent functions through carefully designed multioutput Gaussian processes, RR-FBTC handles tensors with real-valued indices while enabling automatic tensor rank determination during the inference process. We establish the universal approximation property of the model for continuous multi-dimensional signals, demonstrating its expressive power in a concise format. To learn this model, we employ the variational inference framework and derive an efficient algorithm with closed-form updates. Experiments on both synthetic and real-world datasets demonstrate the effectiveness and superiority of the RR-FBTC over state-of-the-art approaches. The code is available at https://github.com/OceanSTARLab/RR-FBTC.
Less Is More: Generating Time Series with LLaMA-Style Autoregression in Simple Factorized Latent Spaces
Nov 07, 2025Generative models for multivariate time series are essential for data augmentation, simulation, and privacy preservation, yet current state-of-the-art diffusion-based approaches are slow and limited to fixed-length windows. We propose FAR-TS, a simple yet effective framework that combines disentangled factorization with an autoregressive Transformer over a discrete, quantized latent space to generate time series. Each time series is decomposed into a data-adaptive basis that captures static cross-channel correlations and temporal coefficients that are vector-quantized into discrete tokens. A LLaMA-style autoregressive Transformer then models these token sequences, enabling fast and controllable generation of sequences with arbitrary length. Owing to its streamlined design, FAR-TS achieves orders-of-magnitude faster generation than Diffusion-TS while preserving cross-channel correlations and an interpretable latent space, enabling high-quality and flexible time series synthesis.
Radar-Camera Fused Multi-Object Tracking: Online Calibration and Common Feature
Oct 23, 2025
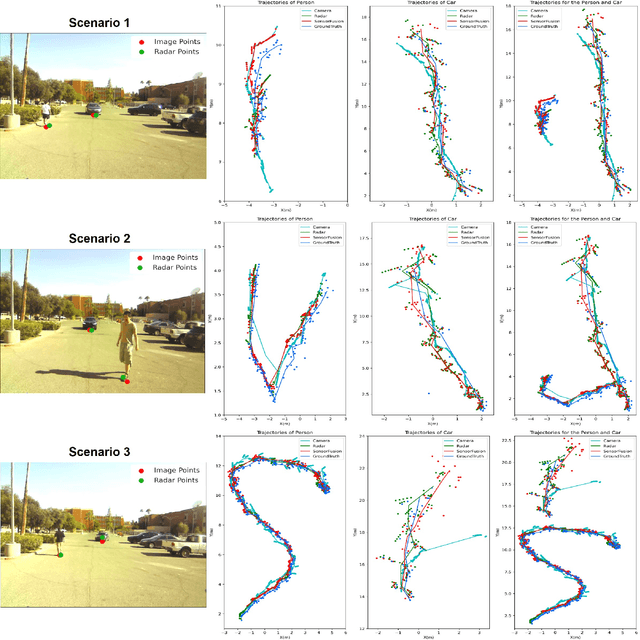

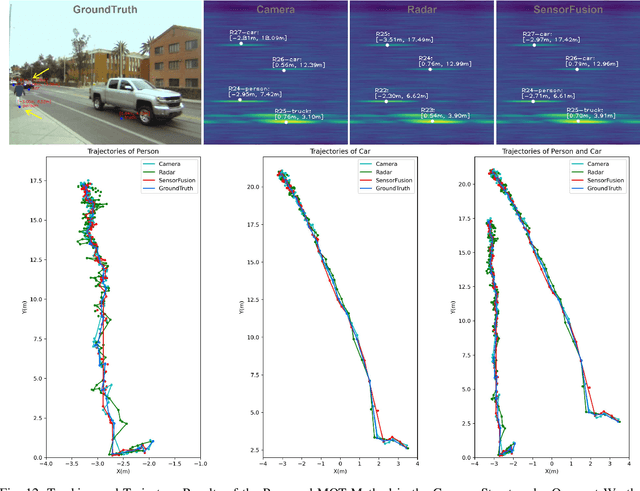
This paper presents a Multi-Object Tracking (MOT) framework that fuses radar and camera data to enhance tracking efficiency while minimizing manual interventions. Contrary to many studies that underutilize radar and assign it a supplementary role--despite its capability to provide accurate range/depth information of targets in a world 3D coordinate system--our approach positions radar in a crucial role. Meanwhile, this paper utilizes common features to enable online calibration to autonomously associate detections from radar and camera. The main contributions of this work include: (1) the development of a radar-camera fusion MOT framework that exploits online radar-camera calibration to simplify the integration of detection results from these two sensors, (2) the utilization of common features between radar and camera data to accurately derive real-world positions of detected objects, and (3) the adoption of feature matching and category-consistency checking to surpass the limitations of mere position matching in enhancing sensor association accuracy. To the best of our knowledge, we are the first to investigate the integration of radar-camera common features and their use in online calibration for achieving MOT. The efficacy of our framework is demonstrated by its ability to streamline the radar-camera mapping process and improve tracking precision, as evidenced by real-world experiments conducted in both controlled environments and actual traffic scenarios. Code is available at https://github.com/radar-lab/Radar_Camera_MOT
Deep Tensor Learning for Reliable Channel Charting from Incomplete and Noisy Measurements
Sep 16, 2025Channel charting has emerged as a powerful tool for user equipment localization and wireless environment sensing. Its efficacy lies in mapping high-dimensional channel data into low-dimensional features that preserve the relative similarities of the original data. However, existing channel charting methods are largely developed using simulated or indoor measurements, often assuming clean and complete channel data across all frequency bands. In contrast, real-world channels collected from base stations are typically incomplete due to frequency hopping and are significantly noisy, particularly at cell edges. These challenging conditions greatly degrade the performance of current methods. To address this, we propose a deep tensor learning method that leverages the inherent tensor structure of wireless channels to effectively extract informative while low-dimensional features (i.e., channel charts) from noisy and incomplete measurements. Experimental results demonstrate the reliability and effectiveness of the proposed approach in these challenging scenarios.
A Learnable Fully Interacted Two-Tower Model for Pre-Ranking System
Sep 16, 2025Pre-ranking plays a crucial role in large-scale recommender systems by significantly improving the efficiency and scalability within the constraints of providing high-quality candidate sets in real time. The two-tower model is widely used in pre-ranking systems due to a good balance between efficiency and effectiveness with decoupled architecture, which independently processes user and item inputs before calculating their interaction (e.g. dot product or similarity measure). However, this independence also leads to the lack of information interaction between the two towers, resulting in less effectiveness. In this paper, a novel architecture named learnable Fully Interacted Two-tower Model (FIT) is proposed, which enables rich information interactions while ensuring inference efficiency. FIT mainly consists of two parts: Meta Query Module (MQM) and Lightweight Similarity Scorer (LSS). Specifically, MQM introduces a learnable item meta matrix to achieve expressive early interaction between user and item features. Moreover, LSS is designed to further obtain effective late interaction between the user and item towers. Finally, experimental results on several public datasets show that our proposed FIT significantly outperforms the state-of-the-art baseline pre-ranking models.
FieldFormer: Self-supervised Reconstruction of Physical Fields via Tensor Attention Prior
Jun 13, 2025Reconstructing physical field tensors from \textit{in situ} observations, such as radio maps and ocean sound speed fields, is crucial for enabling environment-aware decision making in various applications, e.g., wireless communications and underwater acoustics. Field data reconstruction is often challenging, due to the limited and noisy nature of the observations, necessitating the incorporation of prior information to aid the reconstruction process. Deep neural network-based data-driven structural constraints (e.g., ``deeply learned priors'') have showed promising performance. However, this family of techniques faces challenges such as model mismatches between training and testing phases. This work introduces FieldFormer, a self-supervised neural prior learned solely from the limited {\it in situ} observations without the need of offline training. Specifically, the proposed framework starts with modeling the fields of interest using the tensor Tucker model of a high multilinear rank, which ensures a universal approximation property for all fields. In the sequel, an attention mechanism is incorporated to learn the sparsity pattern that underlies the core tensor in order to reduce the solution space. In this way, a ``complexity-adaptive'' neural representation, grounded in the Tucker decomposition, is obtained that can flexibly represent various types of fields. A theoretical analysis is provided to support the recoverability of the proposed design. Moreover, extensive experiments, using various physical field tensors, demonstrate the superiority of the proposed approach compared to state-of-the-art baselines.
Generating Full-field Evolution of Physical Dynamics from Irregular Sparse Observations
May 14, 2025Modeling and reconstructing multidimensional physical dynamics from sparse and off-grid observations presents a fundamental challenge in scientific research. Recently, diffusion-based generative modeling shows promising potential for physical simulation. However, current approaches typically operate on on-grid data with preset spatiotemporal resolution, but struggle with the sparsely observed and continuous nature of real-world physical dynamics. To fill the gaps, we present SDIFT, Sequential DIffusion in Functional Tucker space, a novel framework that generates full-field evolution of physical dynamics from irregular sparse observations. SDIFT leverages the functional Tucker model as the latent space representer with proven universal approximation property, and represents observations as latent functions and Tucker core sequences. We then construct a sequential diffusion model with temporally augmented UNet in the functional Tucker space, denoising noise drawn from a Gaussian process to generate the sequence of core tensors. At the posterior sampling stage, we propose a Message-Passing Posterior Sampling mechanism, enabling conditional generation of the entire sequence guided by observations at limited time steps. We validate SDIFT on three physical systems spanning astronomical (supernova explosions, light-year scale), environmental (ocean sound speed fields, kilometer scale), and molecular (organic liquid, millimeter scale) domains, demonstrating significant improvements in both reconstruction accuracy and computational efficiency compared to state-of-the-art approaches.