 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebChallenger: A Reliable and Efficient Generalist Web Agent
Jun 09, 2026Autonomous web navigation remains challenging for LLM agents, and the strongest generalist systems rely on proprietary reasoning models whose inference cost is prohibitive for the repetitive tasks where such agents would be most useful. We argue this gap stems not from insufficient model capability but from agent architectures that fail to replicate three human cognitive advantages: selective attention to relevant page regions, persistent memory of website structure, and procedural fluency with common interaction patterns. We introduce WebChallenger, a web agent framework that addresses each gap through architecture design rather than model scale, built around PageMem: a structured page representation deterministically constructed from the DOM that exposes each page as a hierarchy of semantic sections with short summaries. On this shared substrate we build three mechanisms that mirror the three cognitive advantages: a divide-and-conquer observation pipeline that lets the agent skim section summaries and extract details only from task-relevant regions; a lightweight exploration and memory system that traverses each website once to build a reusable map of pages and element behaviors; and compound action workflows that collapse common multi-step interactions into single agent actions, handling partial state changes automatically. Because all three operate over PageMem, the framework generalizes across websites without site-specific adapters. Using off-the-shelf open-weight models without fine-tuning, our system achieves 56.3% on WebArena, 48.7% on VisualWebArena, 51.0% on Online-Mind2Web, and 70.9% on WorkArena, approaching frontier proprietary systems at a fraction of the cost. Our code is released at https://github.com/jayoohwang1/webchallenger
FlowForge: A Staged Local Rollout Engine for Flow-Field Prediction
Apr 21, 2026Deep learning surrogates for CFD flow-field prediction often rely on large, complex models, which can be slow and fragile when data are noisy or incomplete. We introduce FlowForge, a staged local rollout engine that predicts future flow fields by compiling a locality-preserving update schedule and executing it with a shared lightweight local predictor. Rather than producing the next frame in a single global pass, FlowForge rewrites spatial sites stage by stage so that each update conditions only on bounded local context exposed by earlier stages. This compile-execute design aligns inference with short-range physical dependence, keeps latency predictable, and limits error amplification from global mixing. Across PDEBench, CFDBench, and BubbleML, FlowForge matches or improves upon strong baselines in pointwise accuracy, delivers consistently better robustness to noise and missing observations, and maintains stable multi-step rollout behavior while reducing per-step latency.
HyMem: Hybrid Memory Architecture with Dynamic Retrieval Scheduling
Feb 15, 2026Large language model (LLM) agents demonstrate strong performance in short-text contexts but often underperform in extended dialogues due to inefficient memory management. Existing approaches face a fundamental trade-off between efficiency and effectiveness: memory compression risks losing critical details required for complex reasoning, while retaining raw text introduces unnecessary computational overhead for simple queries. The crux lies in the limitations of monolithic memory representations and static retrieval mechanisms, which fail to emulate the flexible and proactive memory scheduling capabilities observed in humans, thus struggling to adapt to diverse problem scenarios. Inspired by the principle of cognitive economy, we propose HyMem, a hybrid memory architecture that enables dynamic on-demand scheduling through multi-granular memory representations. HyMem adopts a dual-granular storage scheme paired with a dynamic two-tier retrieval system: a lightweight module constructs summary-level context for efficient response generation, while an LLM-based deep module is selectively activated only for complex queries, augmented by a reflection mechanism for iterative reasoning refinement. Experiments show that HyMem achieves strong performance on both the LOCOMO and LongMemEval benchmarks, outperforming full-context while reducing computational cost by 92.6\%, establishing a state-of-the-art balance between efficiency and performance in long-term memory management.
Bootstrapping MLLM for Weakly-Supervised Class-Agnostic Object Counting
Feb 13, 2026Object counting is a fundamental task in computer vision, with broad applicability in many real-world scenarios. Fully-supervised counting methods require costly point-level annotations per object. Few weakly-supervised methods leverage only image-level object counts as supervision and achieve fairly promising results. They are, however, often limited to counting a single category, e.g. person. In this paper, we propose WS-COC, the first MLLM-driven weakly-supervised framework for class-agnostic object counting. Instead of directly fine-tuning MLLMs to predict object counts, which can be challenging due to the modality gap, we incorporate three simple yet effective strategies to bootstrap the counting paradigm in both training and testing: First, a divide-and-discern dialogue tuning strategy is proposed to guide the MLLM to determine whether the object count falls within a specific range and progressively break down the range through multi-round dialogue. Second, a compare-and-rank count optimization strategy is introduced to train the MLLM to optimize the relative ranking of multiple images according to their object counts. Third, a global-and-local counting enhancement strategy aggregates and fuses local and global count predictions to improve counting performance in dense scenes. Extensive experiments on FSC-147, CARPK, PUCPR+, and ShanghaiTech show that WS-COC matches or even surpasses many state-of-art fully-supervised methods while significantly reducing annotation costs. Code is available at https://github.com/viscom-tongji/WS-COC.
STVG-R1: Incentivizing Instance-Level Reasoning and Grounding in Videos via Reinforcement Learning
Feb 12, 2026In vision-language models (VLMs), misalignment between textual descriptions and visual coordinates often induces hallucinations. This issue becomes particularly severe in dense prediction tasks such as spatial-temporal video grounding (STVG). Prior approaches typically focus on enhancing visual-textual alignment or attaching auxiliary decoders. However, these strategies inevitably introduce additional trainable modules, leading to significant annotation costs and computational overhead. In this work, we propose a novel visual prompting paradigm that avoids the difficult problem of aligning coordinates across modalities. Specifically, we reformulate per-frame coordinate prediction as a compact instance-level identification problem by assigning each object a unique, temporally consistent ID. These IDs are embedded into the video as visual prompts, providing explicit and interpretable inputs to the VLMs. Furthermore, we introduce STVG-R1, the first reinforcement learning framework for STVG, which employs a task-driven reward to jointly optimize temporal accuracy, spatial consistency, and structural format regularization. Extensive experiments on six benchmarks demonstrate the effectiveness of our approach. STVG-R1 surpasses the baseline Qwen2.5-VL-7B by a remarkable margin of 20.9% on m_IoU on the HCSTVG-v2 benchmark, establishing a new state of the art (SOTA). Surprisingly, STVG-R1 also exhibits strong zero-shot generalization to multi-object referring video object segmentation tasks, achieving a SOTA 47.3% J&F on MeViS.
AdaptMMBench: Benchmarking Adaptive Multimodal Reasoning for Mode Selection and Reasoning Process
Feb 02, 2026Adaptive multimodal reasoning has emerged as a promising frontier in Vision-Language Models (VLMs), aiming to dynamically modulate between tool-augmented visual reasoning and text reasoning to enhance both effectiveness and efficiency. However, existing evaluations rely on static difficulty labels and simplistic metrics, which fail to capture the dynamic nature of difficulty relative to varying model capacities. Consequently, they obscure the distinction between adaptive mode selection and general performance while neglecting fine-grained process analyses. In this paper, we propose AdaptMMBench, a comprehensive benchmark for adaptive multimodal reasoning across five domains: real-world, OCR, GUI, knowledge, and math, encompassing both direct perception and complex reasoning tasks. AdaptMMBench utilizes a Matthews Correlation Coefficient (MCC) metric to evaluate the selection rationality of different reasoning modes, isolating this meta-cognition ability by dynamically identifying task difficulties based on models' capability boundaries. Moreover, AdaptMMBench facilitates multi-dimensional process evaluation across key step coverage, tool effectiveness, and computational efficiency. Our evaluation reveals that while adaptive mode selection scales with model capacity, it notably decouples from final accuracy. Conversely, key step coverage aligns with performance, though tool effectiveness remains highly inconsistent across model architectures.
Text-promptable Object Counting via Quantity Awareness Enhancement
Jul 09, 2025



Recent advances in large vision-language models (VLMs) have shown remarkable progress in solving the text-promptable object counting problem. Representative methods typically specify text prompts with object category information in images. This however is insufficient for training the model to accurately distinguish the number of objects in the counting task. To this end, we propose QUANet, which introduces novel quantity-oriented text prompts with a vision-text quantity alignment loss to enhance the model's quantity awareness. Moreover, we propose a dual-stream adaptive counting decoder consisting of a Transformer stream, a CNN stream, and a number of Transformer-to-CNN enhancement adapters (T2C-adapters) for density map prediction. The T2C-adapters facilitate the effective knowledge communication and aggregation between the Transformer and CNN streams. A cross-stream quantity ranking loss is proposed in the end to optimize the ranking orders of predictions from the two streams. Extensive experiments on standard benchmarks such as FSC-147, CARPK, PUCPR+, and ShanghaiTech demonstrate our model's strong generalizability for zero-shot class-agnostic counting. Code is available at https://github.com/viscom-tongji/QUANet
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL
May 21, 2025



Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.
TTRD3: Texture Transfer Residual Denoising Dual Diffusion Model for Remote Sensing Image Super-Resolution
Apr 17, 2025Remote Sensing Image Super-Resolution (RSISR) reconstructs high-resolution (HR) remote sensing images from low-resolution inputs to support fine-grained ground object interpretation. Existing methods face three key challenges: (1) Difficulty in extracting multi-scale features from spatially heterogeneous RS scenes, (2) Limited prior information causing semantic inconsistency in reconstructions, and (3) Trade-off imbalance between geometric accuracy and visual quality. To address these issues, we propose the Texture Transfer Residual Denoising Dual Diffusion Model (TTRD3) with three innovations: First, a Multi-scale Feature Aggregation Block (MFAB) employing parallel heterogeneous convolutional kernels for multi-scale feature extraction. Second, a Sparse Texture Transfer Guidance (STTG) module that transfers HR texture priors from reference images of similar scenes. Third, a Residual Denoising Dual Diffusion Model (RDDM) framework combining residual diffusion for deterministic reconstruction and noise diffusion for diverse generation. Experiments on multi-source RS datasets demonstrate TTRD3's superiority over state-of-the-art methods, achieving 1.43% LPIPS improvement and 3.67% FID enhancement compared to best-performing baselines. Code/model: https://github.com/LED-666/TTRD3.
SeNM-VAE: Semi-Supervised Noise Modeling with Hierarchical Variational Autoencoder
Mar 26, 2024

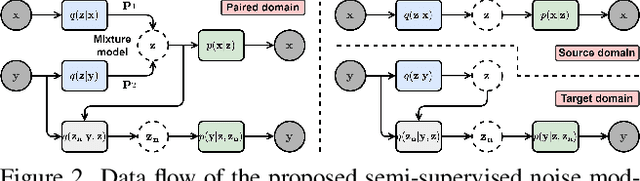

The data bottleneck has emerged as a fundamental challenge in learning based image restoration methods. Researchers have attempted to generate synthesized training data using paired or unpaired samples to address this challenge. This study proposes SeNM-VAE, a semi-supervised noise modeling method that leverages both paired and unpaired datasets to generate realistic degraded data. Our approach is based on modeling the conditional distribution of degraded and clean images with a specially designed graphical model. Under the variational inference framework, we develop an objective function for handling both paired and unpaired data. We employ our method to generate paired training samples for real-world image denoising and super-resolution tasks. Our approach excels in the quality of synthetic degraded images compared to other unpaired and paired noise modeling methods. Furthermore, our approach demonstrates remarkable performance in downstream image restoration tasks, even with limited paired data. With more paired data, our method achieves the best performance on the SIDD dataset.