 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Gao
MVP-SEG: Multi-View Prompt Learning for Open-Vocabulary Semantic Segmentation
Apr 14, 2023
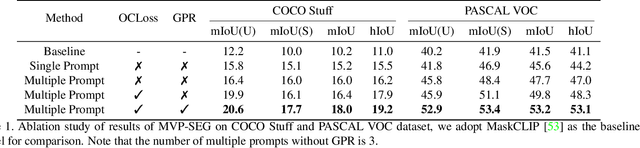
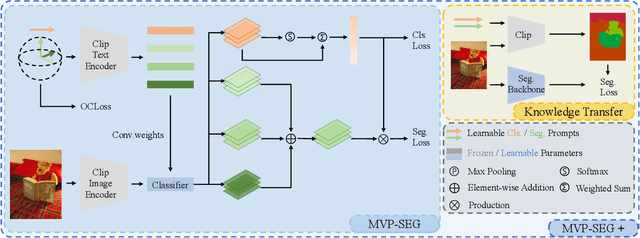
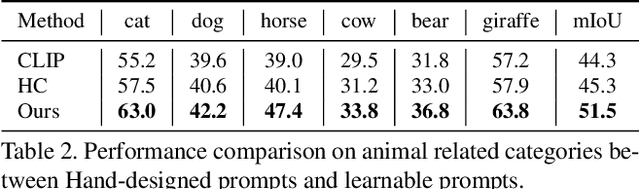
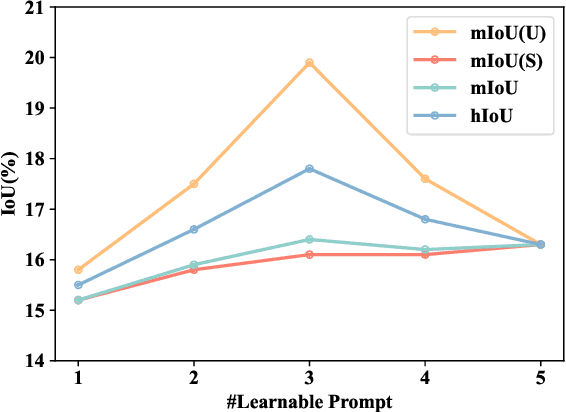
CLIP (Contrastive Language-Image Pretraining) is well-developed for open-vocabulary zero-shot image-level recognition, while its applications in pixel-level tasks are less investigated, where most efforts directly adopt CLIP features without deliberative adaptations. In this work, we first demonstrate the necessity of image-pixel CLIP feature adaption, then provide Multi-View Prompt learning (MVP-SEG) as an effective solution to achieve image-pixel adaptation and to solve open-vocabulary semantic segmentation. Concretely, MVP-SEG deliberately learns multiple prompts trained by our Orthogonal Constraint Loss (OCLoss), by which each prompt is supervised to exploit CLIP feature on different object parts, and collaborative segmentation masks generated by all prompts promote better segmentation. Moreover, MVP-SEG introduces Global Prompt Refining (GPR) to further eliminate class-wise segmentation noise. Experiments show that the multi-view prompts learned from seen categories have strong generalization to unseen categories, and MVP-SEG+ which combines the knowledge transfer stage significantly outperforms previous methods on several benchmarks. Moreover, qualitative results justify that MVP-SEG does lead to better focus on different local parts.
Multi-view reconstruction of bullet time effect based on improved NSFF model
Apr 01, 2023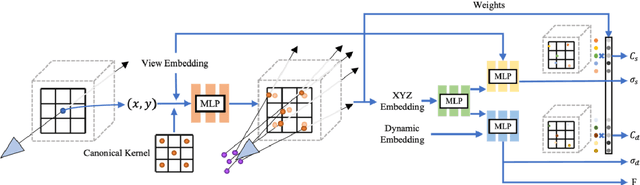
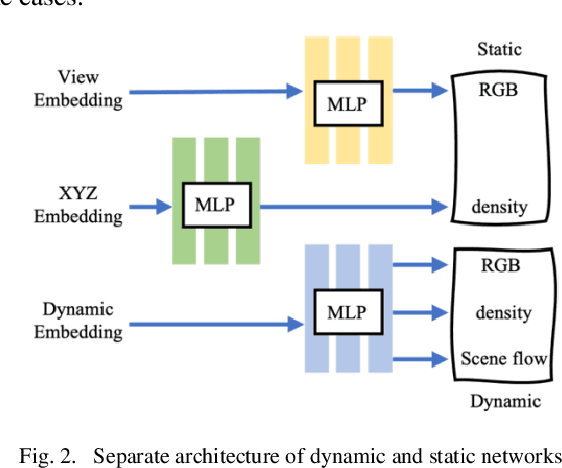
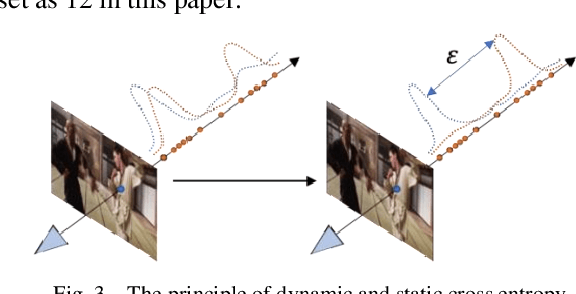

Bullet time is a type of visual effect commonly used in film, television and games that makes time seem to slow down or stop while still preserving dynamic details in the scene. It usually requires multiple sets of cameras to move slowly with the subject and is synthesized using post-production techniques, which is costly and one-time. The dynamic scene perspective reconstruction technology based on neural rendering field can be used to solve this requirement, but most of the current methods are poor in reconstruction accuracy due to the blurred input image and overfitting of dynamic and static regions. Based on the NSFF algorithm, this paper reconstructed the common time special effects scenes in movies and television from a new perspective. To improve the accuracy of the reconstructed images, fuzzy kernel was added to the network for reconstruction and analysis of the fuzzy process, and the clear perspective after analysis was input into the NSFF to improve the accuracy. By using the optical flow prediction information to suppress the dynamic network timely, the network is forced to improve the reconstruction effect of dynamic and static networks independently, and the ability to understand and reconstruct dynamic and static scenes is improved. To solve the overfitting problem of dynamic and static scenes, a new dynamic and static cross entropy loss is designed. Experimental results show that compared with original NSFF and other new perspective reconstruction algorithms of dynamic scenes, the improved NSFF-RFCT improves the reconstruction accuracy and enhances the understanding ability of dynamic and static scenes.
Adaptive Approximate Implicitization of Planar Parametric Curves via Weak Gradient Constraints
Feb 23, 2023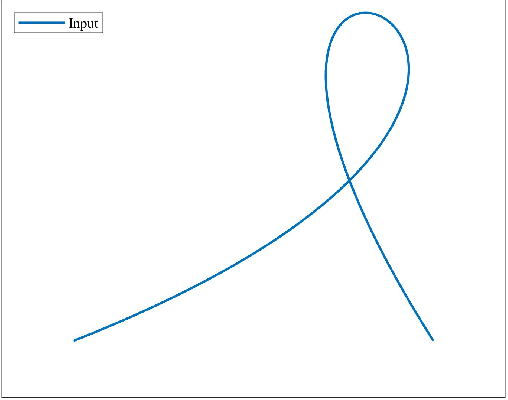


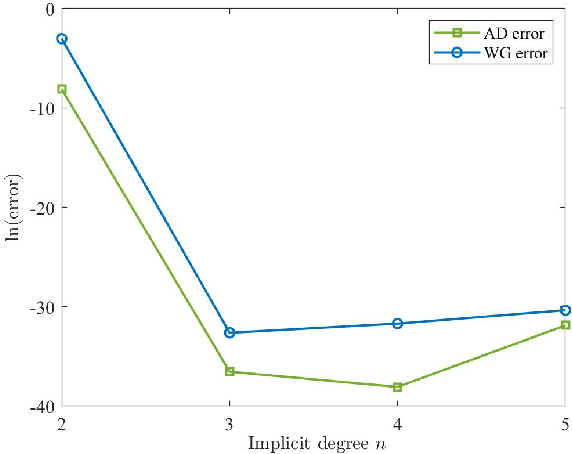
Converting a parametric curve into the implicit form, which is called implicitization, has always been a popular but challenging problem in geometric modeling and related applications. However, the existing methods mostly suffer from the problems of maintaining geometric features and choosing a reasonable implicit degree. The present paper has two contributions. We first introduce a new regularization constraint(called the weak gradient constraint) for both polynomial and non-polynomial curves, which efficiently possesses shape preserving. We then propose two adaptive algorithms of approximate implicitization for polynomial and non-polynomial curves respectively, which find the ``optimal'' implicit degree based on the behavior of the weak gradient constraint. More precisely, the idea is gradually increasing the implicit degree, until there is no obvious improvement in the weak gradient loss of the outputs. Experimental results have shown the effectiveness and high quality of our proposed methods.
OvarNet: Towards Open-vocabulary Object Attribute Recognition
Jan 23, 2023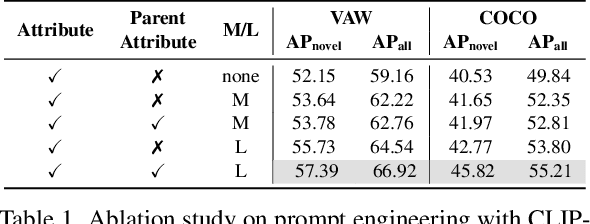
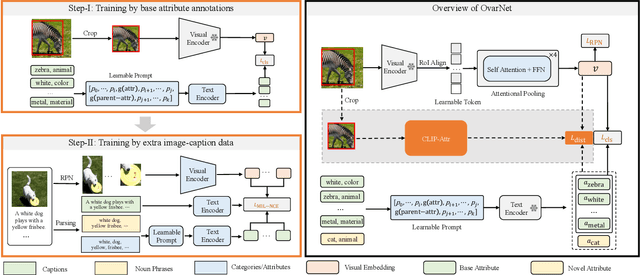
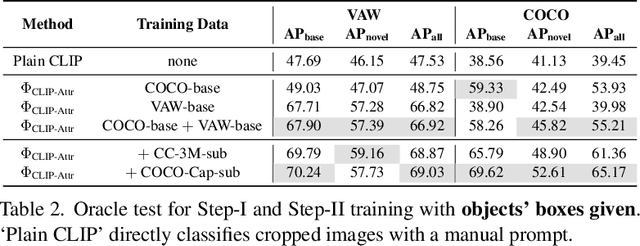
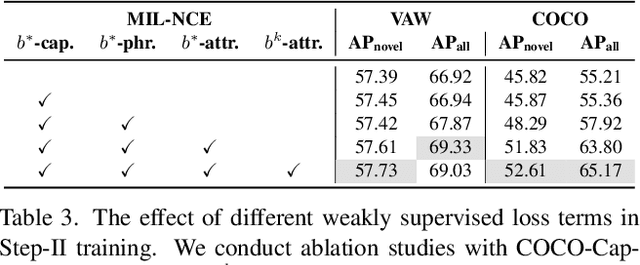
In this paper, we consider the problem of simultaneously detecting objects and inferring their visual attributes in an image, even for those with no manual annotations provided at the training stage, resembling an open-vocabulary scenario. To achieve this goal, we make the following contributions: (i) we start with a naive two-stage approach for open-vocabulary object detection and attribute classification, termed CLIP-Attr. The candidate objects are first proposed with an offline RPN and later classified for semantic category and attributes; (ii) we combine all available datasets and train with a federated strategy to finetune the CLIP model, aligning the visual representation with attributes, additionally, we investigate the efficacy of leveraging freely available online image-caption pairs under weakly supervised learning; (iii) in pursuit of efficiency, we train a Faster-RCNN type model end-to-end with knowledge distillation, that performs class-agnostic object proposals and classification on semantic categories and attributes with classifiers generated from a text encoder; Finally, (iv) we conduct extensive experiments on VAW, MS-COCO, LSA, and OVAD datasets, and show that recognition of semantic category and attributes is complementary for visual scene understanding, i.e., jointly training object detection and attributes prediction largely outperform existing approaches that treat the two tasks independently, demonstrating strong generalization ability to novel attributes and categories.
Towards Knowledge-Intensive Text-to-SQL Semantic Parsing with Formulaic Knowledge
Jan 03, 2023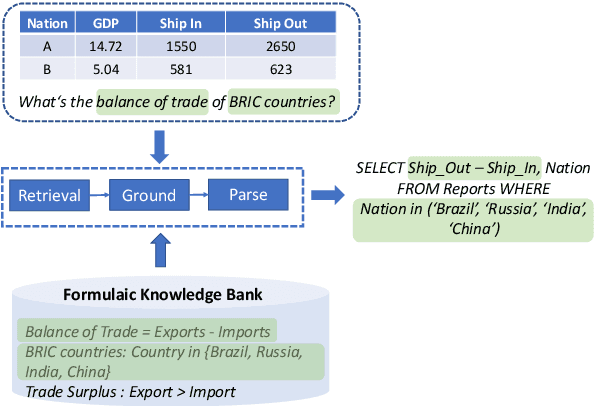
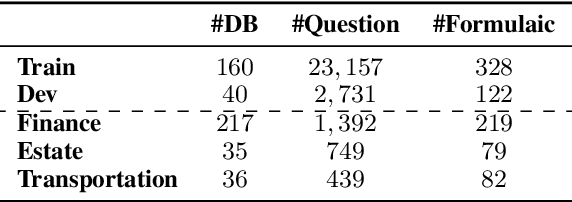
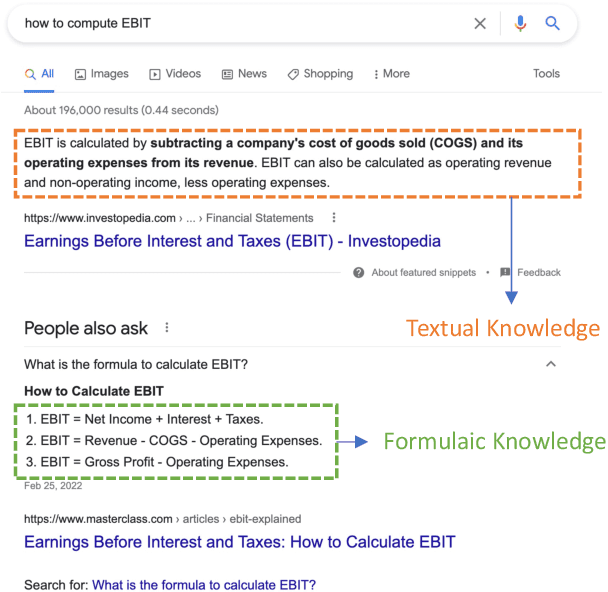

In this paper, we study the problem of knowledge-intensive text-to-SQL, in which domain knowledge is necessary to parse expert questions into SQL queries over domain-specific tables. We formalize this scenario by building a new Chinese benchmark KnowSQL consisting of domain-specific questions covering various domains. We then address this problem by presenting formulaic knowledge, rather than by annotating additional data examples. More concretely, we construct a formulaic knowledge bank as a domain knowledge base and propose a framework (ReGrouP) to leverage this formulaic knowledge during parsing. Experiments using ReGrouP demonstrate a significant 28.2% improvement overall on KnowSQL.
MultiSpider: Towards Benchmarking Multilingual Text-to-SQL Semantic Parsing
Dec 27, 2022
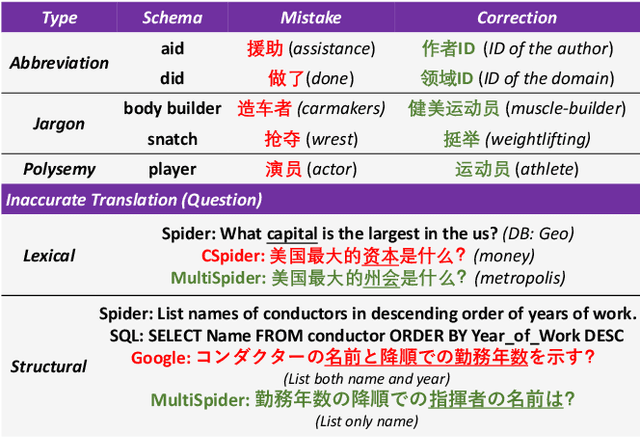
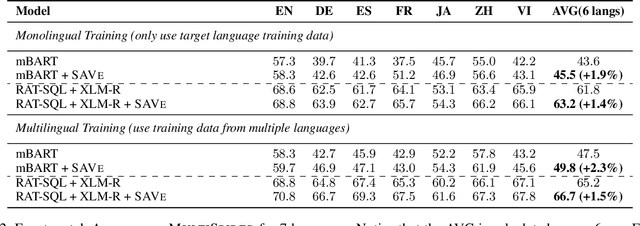

Text-to-SQL semantic parsing is an important NLP task, which greatly facilitates the interaction between users and the database and becomes the key component in many human-computer interaction systems. Much recent progress in text-to-SQL has been driven by large-scale datasets, but most of them are centered on English. In this work, we present MultiSpider, the largest multilingual text-to-SQL dataset which covers seven languages (English, German, French, Spanish, Japanese, Chinese, and Vietnamese). Upon MultiSpider, we further identify the lexical and structural challenges of text-to-SQL (caused by specific language properties and dialect sayings) and their intensity across different languages. Experimental results under three typical settings (zero-shot, monolingual and multilingual) reveal a 6.1% absolute drop in accuracy in non-English languages. Qualitative and quantitative analyses are conducted to understand the reason for the performance drop of each language. Besides the dataset, we also propose a simple schema augmentation framework SAVe (Schema-Augmentation-with-Verification), which significantly boosts the overall performance by about 1.8% and closes the 29.5% performance gap across languages.
Distributed Control within a Trapezoid Virtual Tube Containing Obstacles for UAV Swarm Subject to Speed Constraints
Dec 24, 2022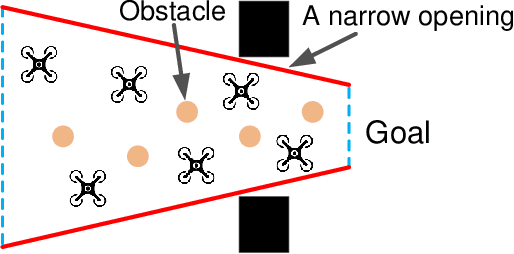
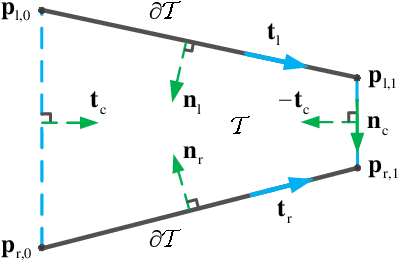
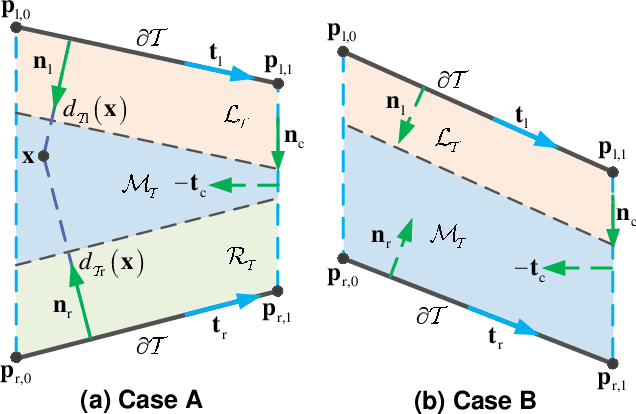
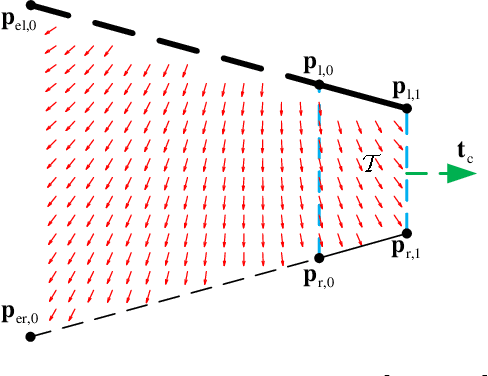
For guiding the UAV swarm to pass through narrow openings, a trapezoid virtual tube is designed in our previous work. In this paper, we generalize its application range to the condition that there exist obstacles inside the trapezoid virtual tube and UAVs have strict speed constraints. First, a distributed vector field controller is proposed for the trapezoid virtual tube with no obstacle inside. The relationship between the trapezoid virtual tube and the speed constraints is also presented. Then, a switching logic for the obstacle avoidance is put forward. The key point is to divide the trapezoid virtual tube containing obstacles into several sub trapezoid virtual tubes with no obstacle inside. Formal analyses and proofs are made to show that all UAVs are able to pass through the trapezoid virtual tube safely. Besides, the effectiveness of the proposed method is validated by numerical simulations and real experiments.
Towards Robustness of Text-to-SQL Models Against Natural and Realistic Adversarial Table Perturbation
Dec 20, 2022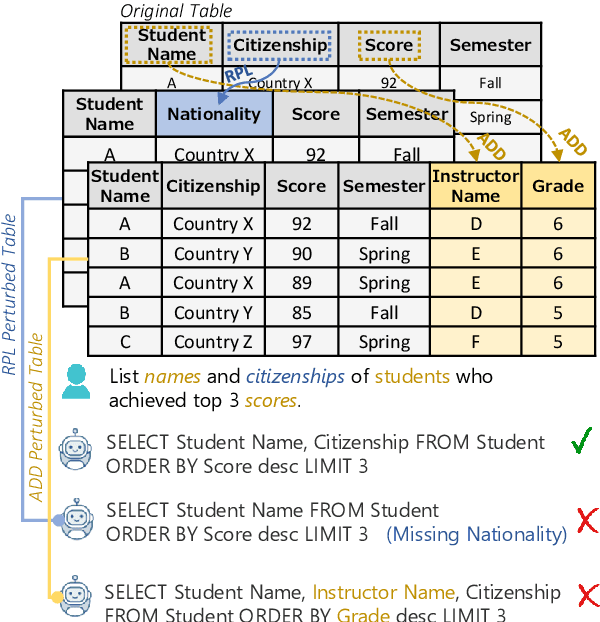
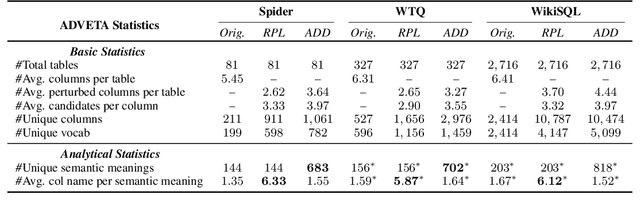
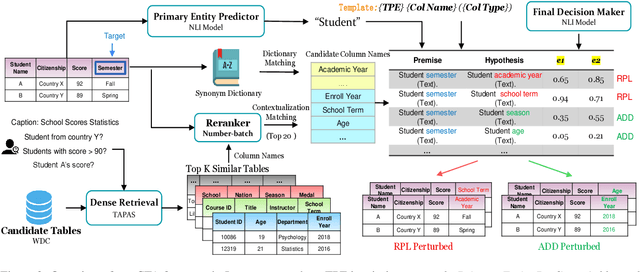
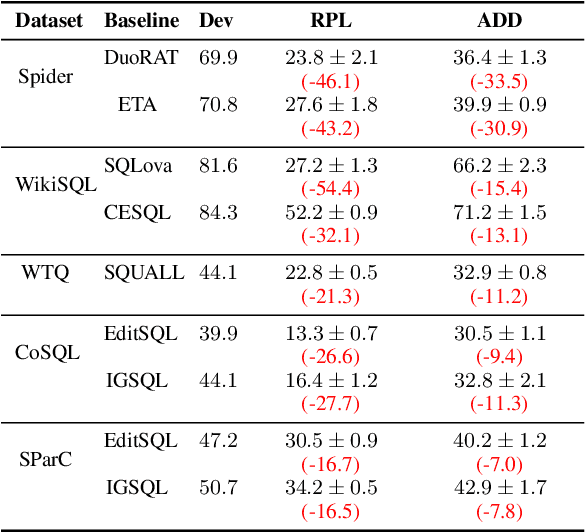
The robustness of Text-to-SQL parsers against adversarial perturbations plays a crucial role in delivering highly reliable applications. Previous studies along this line primarily focused on perturbations in the natural language question side, neglecting the variability of tables. Motivated by this, we propose the Adversarial Table Perturbation (ATP) as a new attacking paradigm to measure the robustness of Text-to-SQL models. Following this proposition, we curate ADVETA, the first robustness evaluation benchmark featuring natural and realistic ATPs. All tested state-of-the-art models experience dramatic performance drops on ADVETA, revealing models' vulnerability in real-world practices. To defend against ATP, we build a systematic adversarial training example generation framework tailored for better contextualization of tabular data. Experiments show that our approach not only brings the best robustness improvement against table-side perturbations but also substantially empowers models against NL-side perturbations. We release our benchmark and code at: https://github.com/microsoft/ContextualSP.
Know What I don't Know: Handling Ambiguous and Unanswerable Questions for Text-to-SQL
Dec 17, 2022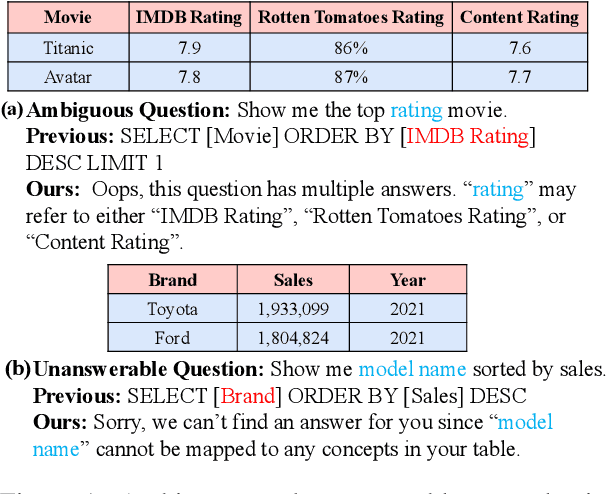

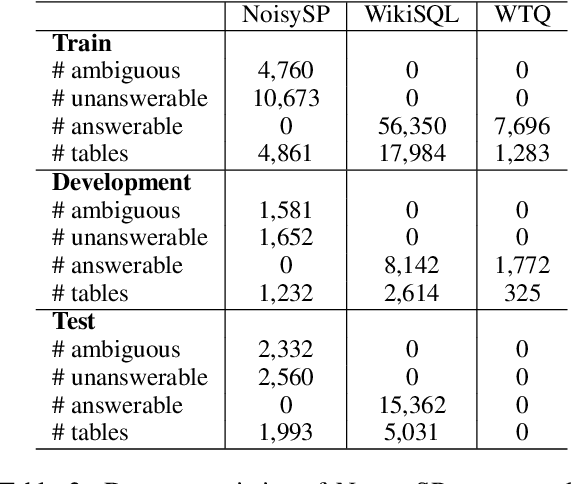

The task of text-to-SQL is to convert a natural language question to its corresponding SQL query in the context of relational tables. Existing text-to-SQL parsers generate a "plausible" SQL query for an arbitrary user question, thereby failing to correctly handle problematic user questions. To formalize this problem, we conduct a preliminary study on the observed ambiguous and unanswerable cases in text-to-SQL and summarize them into 6 feature categories. Correspondingly, we identify the causes behind each category and propose requirements for handling ambiguous and unanswerable questions. Following this study, we propose a simple yet effective counterfactual example generation approach for the automatic generation of ambiguous and unanswerable text-to-SQL examples. Furthermore, we propose a weakly supervised model DTE (Detecting-Then-Explaining) for error detection, localization, and explanation. Experimental results show that our model achieves the best result on both real-world examples and generated examples compared with various baselines. We will release data and code for future research.
Federated Learning for Inference at Anytime and Anywhere
Dec 08, 2022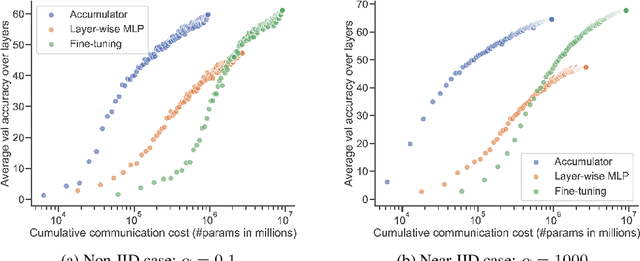
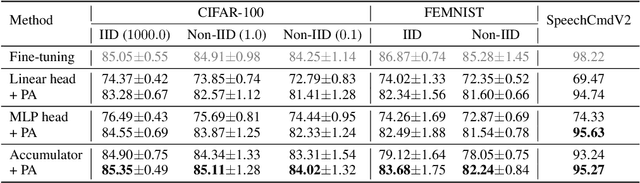
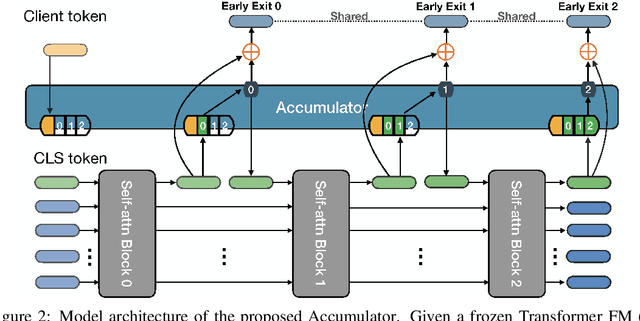
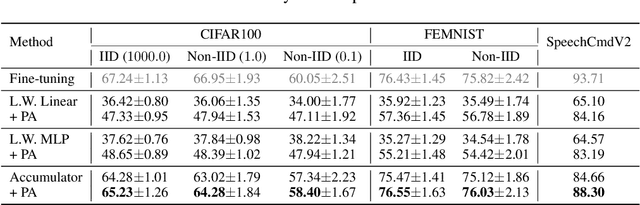
Federated learning has been predominantly concerned with collaborative training of deep networks from scratch, and especially the many challenges that arise, such as communication cost, robustness to heterogeneous data, and support for diverse device capabilities. However, there is no unified framework that addresses all these problems together. This paper studies the challenges and opportunities of exploiting pre-trained Transformer models in FL. In particular, we propose to efficiently adapt such pre-trained models by injecting a novel attention-based adapter module at each transformer block that both modulates the forward pass and makes an early prediction. Training only the lightweight adapter by FL leads to fast and communication-efficient learning even in the presence of heterogeneous data and devices. Extensive experiments on standard FL benchmarks, including CIFAR-100, FEMNIST and SpeechCommandsv2 demonstrate that this simple framework provides fast and accurate FL while supporting heterogenous device capabilities, efficient personalization, and scalable-cost anytime inference.