 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-Image Technical Report
May 25, 2026We introduce ERNIE-Image, an open-source text-to-image generation model built upon an 8B single-stream DiT architecture. ERNIE-Image aims to bridge the gap between current open-source models and leading closed-source systems through more effective mining of large-scale pre-training data and improved supervision quality throughout training. During pre-training, we adopt a bottom-up data construction pipeline that combines fine-grained image categorization, rich caption annotation, aesthetic assessment, and hierarchical sampling. This strategy reduces data noise while preserving long-tail concepts and detailed real-world knowledge, providing a stronger foundation for complex generation tasks. In the post-training stage, we use a top-down data construction pipeline for high-demand scenarios, diversify prompt annotations to better match real user inputs, and apply a stabilized DPO strategy to align the model with human aesthetic preferences. We further train ERNIE-Image-Turbo for efficient 8-NFE generation and propose MT-DMD to mitigate capability drift during distillation. To make the model easier to use in practical scenarios, we equip it with a lightweight Prompt Enhancer that expands concise user intents into structured visual descriptions. In addition, we develop ERNIE-Image-Aes, an industrial-grade aesthetic model, together with ERNIE-Image-Aes-1K, a human-annotated benchmark for realistic aesthetic evaluation. Extensive qualitative and quantitative experiments show that ERNIE-Image achieves leading performance among open-source models and approaches top-tier commercial models in instruction following, text rendering, and aesthetic quality. We release the trained models and aesthetic resources to facilitate further academic research and technical progress in the AIGC community.
RAVES-Calib: Robust, Accurate and Versatile Extrinsic Self Calibration Using Optimal Geometric Features
Dec 09, 2025



In this paper, we present a user-friendly LiDAR-camera calibration toolkit that is compatible with various LiDAR and camera sensors and requires only a single pair of laser points and a camera image in targetless environments. Our approach eliminates the need for an initial transform and remains robust even with large positional and rotational LiDAR-camera extrinsic parameters. We employ the Gluestick pipeline to establish 2D-3D point and line feature correspondences for a robust and automatic initial guess. To enhance accuracy, we quantitatively analyze the impact of feature distribution on calibration results and adaptively weight the cost of each feature based on these metrics. As a result, extrinsic parameters are optimized by filtering out the adverse effects of inferior features. We validated our method through extensive experiments across various LiDAR-camera sensors in both indoor and outdoor settings. The results demonstrate that our method provides superior robustness and accuracy compared to SOTA techniques. Our code is open-sourced on GitHub to benefit the community.
TeaRAG: A Token-Efficient Agentic Retrieval-Augmented Generation Framework
Nov 07, 2025Retrieval-Augmented Generation (RAG) utilizes external knowledge to augment Large Language Models' (LLMs) reliability. For flexibility, agentic RAG employs autonomous, multi-round retrieval and reasoning to resolve queries. Although recent agentic RAG has improved via reinforcement learning, they often incur substantial token overhead from search and reasoning processes. This trade-off prioritizes accuracy over efficiency. To address this issue, this work proposes TeaRAG, a token-efficient agentic RAG framework capable of compressing both retrieval content and reasoning steps. 1) First, the retrieved content is compressed by augmenting chunk-based semantic retrieval with a graph retrieval using concise triplets. A knowledge association graph is then built from semantic similarity and co-occurrence. Finally, Personalized PageRank is leveraged to highlight key knowledge within this graph, reducing the number of tokens per retrieval. 2) Besides, to reduce reasoning steps, Iterative Process-aware Direct Preference Optimization (IP-DPO) is proposed. Specifically, our reward function evaluates the knowledge sufficiency by a knowledge matching mechanism, while penalizing excessive reasoning steps. This design can produce high-quality preference-pair datasets, supporting iterative DPO to improve reasoning conciseness. Across six datasets, TeaRAG improves the average Exact Match by 4% and 2% while reducing output tokens by 61% and 59% on Llama3-8B-Instruct and Qwen2.5-14B-Instruct, respectively. Code is available at https://github.com/Applied-Machine-Learning-Lab/TeaRAG.
ScalingNote: Scaling up Retrievers with Large Language Models for Real-World Dense Retrieval
Nov 24, 2024



Dense retrieval in most industries employs dual-tower architectures to retrieve query-relevant documents. Due to online deployment requirements, existing real-world dense retrieval systems mainly enhance performance by designing negative sampling strategies, overlooking the advantages of scaling up. Recently, Large Language Models (LLMs) have exhibited superior performance that can be leveraged for scaling up dense retrieval. However, scaling up retrieval models significantly increases online query latency. To address this challenge, we propose ScalingNote, a two-stage method to exploit the scaling potential of LLMs for retrieval while maintaining online query latency. The first stage is training dual towers, both initialized from the same LLM, to unlock the potential of LLMs for dense retrieval. Then, we distill only the query tower using mean squared error loss and cosine similarity to reduce online costs. Through theoretical analysis and comprehensive offline and online experiments, we show the effectiveness and efficiency of ScalingNote. Our two-stage scaling method outperforms end-to-end models and verifies the scaling law of dense retrieval with LLMs in industrial scenarios, enabling cost-effective scaling of dense retrieval systems. Our online method incorporating ScalingNote significantly enhances the relevance between retrieved documents and queries.
Vript: A Video Is Worth Thousands of Words
Jun 10, 2024



Advancements in multimodal learning, particularly in video understanding and generation, require high-quality video-text datasets for improved model performance. Vript addresses this issue with a meticulously annotated corpus of 12K high-resolution videos, offering detailed, dense, and script-like captions for over 420K clips. Each clip has a caption of ~145 words, which is over 10x longer than most video-text datasets. Unlike captions only documenting static content in previous datasets, we enhance video captioning to video scripting by documenting not just the content, but also the camera operations, which include the shot types (medium shot, close-up, etc) and camera movements (panning, tilting, etc). By utilizing the Vript, we explore three training paradigms of aligning more text with the video modality rather than clip-caption pairs. This results in Vriptor, a top-performing video captioning model among open-source models, comparable to GPT-4V in performance. Vriptor is also a powerful model capable of end-to-end generation of dense and detailed captions for long videos. Moreover, we introduce Vript-Hard, a benchmark consisting of three video understanding tasks that are more challenging than existing benchmarks: Vript-HAL is the first benchmark evaluating action and object hallucinations in video LLMs, Vript-RR combines reasoning with retrieval resolving question ambiguity in long-video QAs, and Vript-ERO is a new task to evaluate the temporal understanding of events in long videos rather than actions in short videos in previous works. All code, models, and datasets are available in https://github.com/mutonix/Vript.
NoteLLM-2: Multimodal Large Representation Models for Recommendation
May 27, 2024



Large Language Models (LLMs) have demonstrated exceptional text understanding. Existing works explore their application in text embedding tasks. However, there are few works utilizing LLMs to assist multimodal representation tasks. In this work, we investigate the potential of LLMs to enhance multimodal representation in multimodal item-to-item (I2I) recommendations. One feasible method is the transfer of Multimodal Large Language Models (MLLMs) for representation tasks. However, pre-training MLLMs usually requires collecting high-quality, web-scale multimodal data, resulting in complex training procedures and high costs. This leads the community to rely heavily on open-source MLLMs, hindering customized training for representation scenarios. Therefore, we aim to design an end-to-end training method that customizes the integration of any existing LLMs and vision encoders to construct efficient multimodal representation models. Preliminary experiments show that fine-tuned LLMs in this end-to-end method tend to overlook image content. To overcome this challenge, we propose a novel training framework, NoteLLM-2, specifically designed for multimodal representation. We propose two ways to enhance the focus on visual information. The first method is based on the prompt viewpoint, which separates multimodal content into visual content and textual content. NoteLLM-2 adopts the multimodal In-Content Learning method to teach LLMs to focus on both modalities and aggregate key information. The second method is from the model architecture, utilizing a late fusion mechanism to directly fuse visual information into textual information. Extensive experiments have been conducted to validate the effectiveness of our method.
From Image to Video, what do we need in multimodal LLMs?
Apr 18, 2024Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
NoteLLM: A Retrievable Large Language Model for Note Recommendation
Mar 04, 2024



People enjoy sharing "notes" including their experiences within online communities. Therefore, recommending notes aligned with user interests has become a crucial task. Existing online methods only input notes into BERT-based models to generate note embeddings for assessing similarity. However, they may underutilize some important cues, e.g., hashtags or categories, which represent the key concepts of notes. Indeed, learning to generate hashtags/categories can potentially enhance note embeddings, both of which compress key note information into limited content. Besides, Large Language Models (LLMs) have significantly outperformed BERT in understanding natural languages. It is promising to introduce LLMs into note recommendation. In this paper, we propose a novel unified framework called NoteLLM, which leverages LLMs to address the item-to-item (I2I) note recommendation. Specifically, we utilize Note Compression Prompt to compress a note into a single special token, and further learn the potentially related notes' embeddings via a contrastive learning approach. Moreover, we use NoteLLM to summarize the note and generate the hashtag/category automatically through instruction tuning. Extensive validations on real scenarios demonstrate the effectiveness of our proposed method compared with the online baseline and show major improvements in the recommendation system of Xiaohongshu.
Single-Channel EEG Based Arousal Level Estimation Using Multitaper Spectrum Estimation at Low-Power Wearable Devices
Jul 31, 2021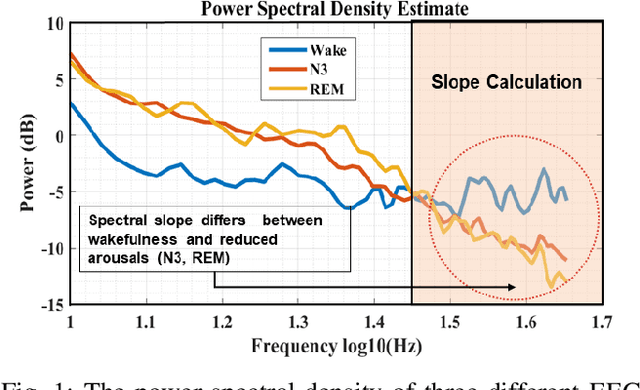
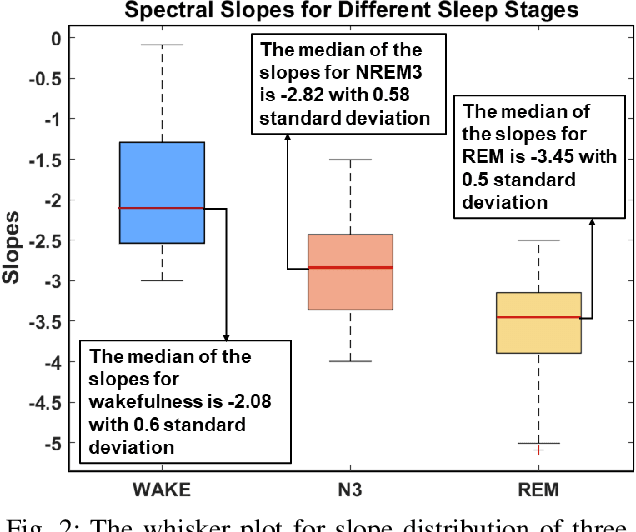
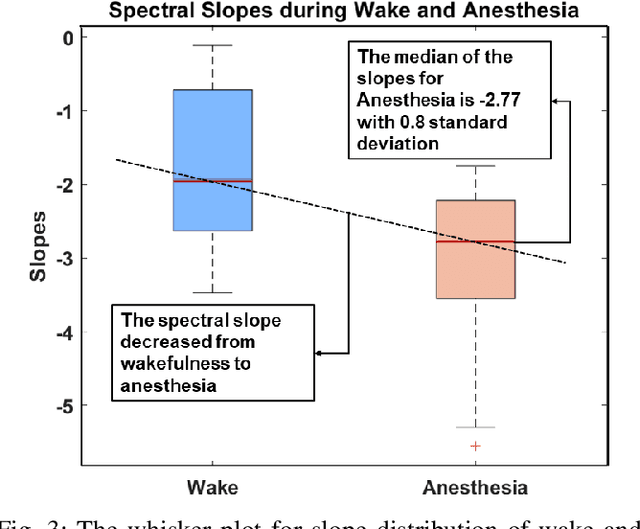
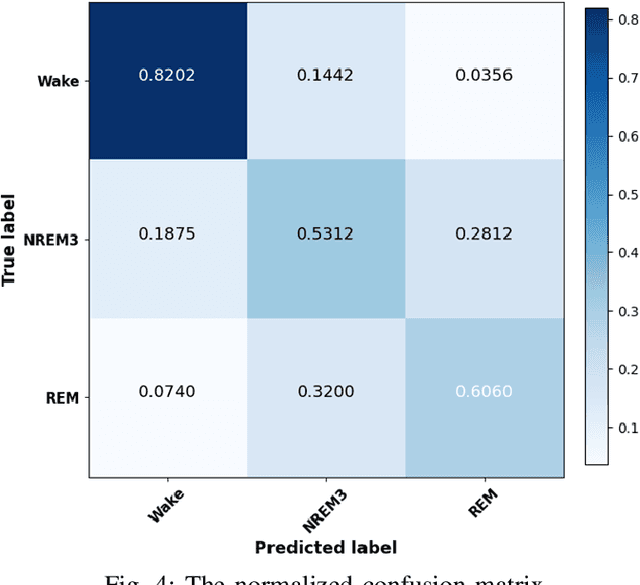
This paper proposes a novel lightweight method using the multitaper power spectrum to estimate arousal levels at wearable devices. We show that the spectral slope (1/f) of the electrophysiological power spectrum reflects the scale-free neural activity. To evaluate the proposed feature's performance, we used scalp EEG recorded during anesthesia and sleep with technician-scored Hypnogram annotations. It is shown that the proposed methodology discriminates wakefulness from reduced arousal solely based on the neurophysiological brain state with more than 80% accuracy. Therefore, our findings describe a common electrophysiological marker that tracks reduced arousal states, which can be applied to different applications (e.g., emotion detection, driver drowsiness). Evaluation on hardware shows that the proposed methodology can be implemented for devices with a minimum RAM of 512 KB with 55 mJ average energy consumption.
A multi-branch convolutional neural network for detecting double JPEG compression
Oct 16, 2017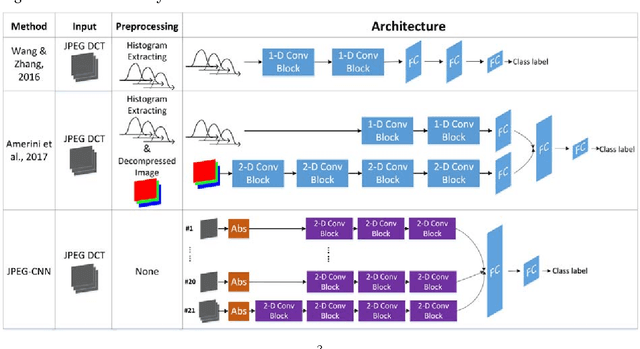
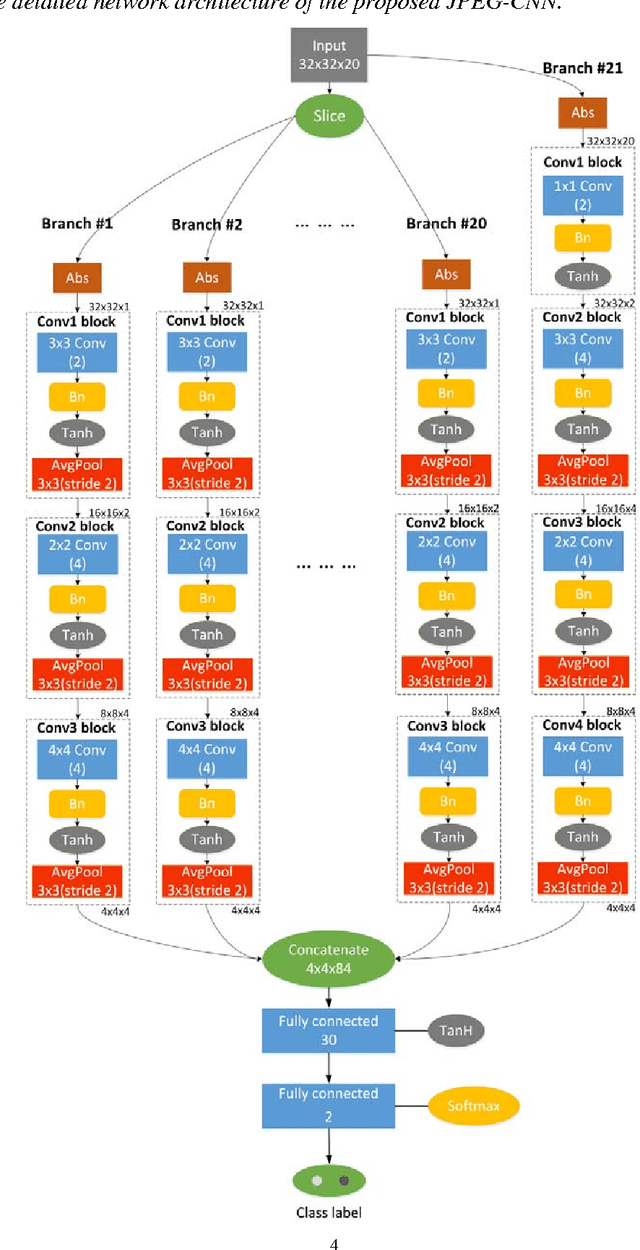
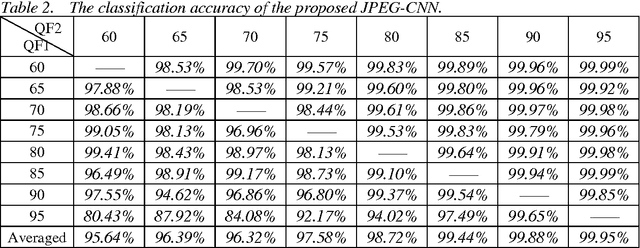
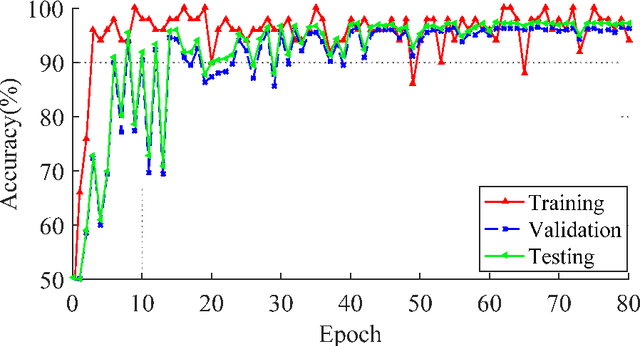
Detection of double JPEG compression is important to forensics analysis. A few methods were proposed based on convolutional neural networks (CNNs). These methods only accept inputs from pre-processed data, such as histogram features and/or decompressed images. In this paper, we present a CNN solution by using raw DCT (discrete cosine transformation) coefficients from JPEG images as input. Considering the DCT sub-band nature in JPEG, a multiple-branch CNN structure has been designed to reveal whether a JPEG format image has been doubly compressed. Comparing with previous methods, the proposed method provides end-to-end detection capability. Extensive experiments have been carried out to demonstrate the effectiveness of the proposed network.