 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCAgent: Enhancing Group Chat Communication through Dialogue Agents System
Mar 05, 2026As a key form in online social platforms, group chat is a popular space for interest exchange or problem-solving, but its effectiveness is often hindered by inactivity and management challenges. While recent large language models (LLMs) have powered impressive one-to-one conversational agents, their seamlessly integration into multi-participant conversations remains unexplored. To address this gap, we introduce GCAgent, an LLM-driven system for enhancing group chats communication with both entertainment- and utility-oriented dialogue agents. The system comprises three tightly integrated modules: Agent Builder, which customizes agents to align with users' interests; Dialogue Manager, which coordinates dialogue states and manage agent invocations; and Interface Plugins, which reduce interaction barriers by three distinct tools. Through extensive experiment, GCAgent achieved an average score of 4.68 across various criteria and was preferred in 51.04\% of cases compared to its base model. Additionally, in real-world deployments over 350 days, it increased message volume by 28.80\%, significantly improving group activity and engagement. Overall, this work presents a practical blueprint for extending LLM-based dialogue agent from one-party chats to multi-party group scenarios.
Balancing Understanding and Generation in Discrete Diffusion Models
Feb 01, 2026In discrete generative modeling, two dominant paradigms demonstrate divergent capabilities: Masked Diffusion Language Models (MDLM) excel at semantic understanding and zero-shot generalization, whereas Uniform-noise Diffusion Language Models (UDLM) achieve strong few-step generation quality, yet neither attains balanced performance across both dimensions. To address this, we propose XDLM, which bridges the two paradigms via a stationary noise kernel. XDLM offers two key contributions: (1) it provides a principled theoretical unification of MDLM and UDLM, recovering each paradigm as a special case; and (2) an alleviated memory bottleneck enabled by an algebraic simplification of the posterior probabilities. Experiments demonstrate that XDLM advances the Pareto frontier between understanding capability and generation quality. Quantitatively, XDLM surpasses UDLM by 5.4 points on zero-shot text benchmarks and outperforms MDLM in few-step image generation (FID 54.1 vs. 80.8). When scaled to tune an 8B-parameter large language model, XDLM achieves 15.0 MBPP in just 32 steps, effectively doubling the baseline performance. Finally, analysis of training dynamics reveals XDLM's superior potential for long-term scaling. Code is available at https://github.com/MzeroMiko/XDLM
Decouple Searching from Training: Scaling Data Mixing via Model Merging for Large Language Model Pre-training
Jan 31, 2026Determining an effective data mixture is a key factor in Large Language Model (LLM) pre-training, where models must balance general competence with proficiency on hard tasks such as math and code. However, identifying an optimal mixture remains an open challenge, as existing approaches either rely on unreliable tiny-scale proxy experiments or require prohibitively expensive large-scale exploration. To address this, we propose Decouple Searching from Training Mix (DeMix), a novel framework that leverages model merging to predict optimal data ratios. Instead of training proxy models for every sampled mixture, DeMix trains component models on candidate datasets at scale and derives data mixture proxies via weighted model merging. This paradigm decouples search from training costs, enabling evaluation of unlimited sampled mixtures without extra training burden and thus facilitating better mixture discovery through more search trials. Extensive experiments demonstrate that DeMix breaks the trade-off between sufficiency, accuracy and efficiency, obtaining the optimal mixture with higher benchmark performance at lower search cost. Additionally, we release the DeMix Corpora, a comprehensive 22T-token dataset comprising high-quality pre-training data with validated mixtures to facilitate open research. Our code and DeMix Corpora is available at https://github.com/Lucius-lsr/DeMix.
Benchmarking Machine Translation on Chinese Social Media Texts
Jan 30, 2026The prevalence of rapidly evolving slang, neologisms, and highly stylized expressions in informal user-generated text, particularly on Chinese social media, poses significant challenges for Machine Translation (MT) benchmarking. Specifically, we identify two primary obstacles: (1) data scarcity, as high-quality parallel data requires bilingual annotators familiar with platform-specific slang, and stylistic cues in both languages; and (2) metric limitations, where traditional evaluators like COMET often fail to capture stylistic fidelity and nonstandard expressions. To bridge these gaps, we introduce CSM-MTBench, a benchmark covering five Chinese-foreign language directions and consisting of two expert-curated subsets: Fun Posts, featuring context-rich, slang- and neologism-heavy content, and Social Snippets, emphasizing concise, emotion- and style- driven expressions. Furthermore, we propose tailored evaluation approaches for each subset: measuring the translation success rate of slang and neologisms in Fun Posts, while assessing tone and style preservation in Social Snippets via a hybrid of embedding-based metrics and LLM-as-a-judge. Experiments on over 20 models reveal substantial variation in how current MT systems handle semantic fidelity and informal, social-media-specific stylistic cues. CSM-MTBench thus serves as a rigorous testbed for advancing MT systems capable of mastering real-world Chinese social media texts.
One Token Is Enough: Improving Diffusion Language Models with a Sink Token
Jan 27, 2026Diffusion Language Models (DLMs) have emerged as a compelling alternative to autoregressive approaches, enabling parallel text generation with competitive performance. Despite these advantages, there is a critical instability in DLMs: the moving sink phenomenon. Our analysis indicates that sink tokens exhibit low-norm representations in the Transformer's value space, and that the moving sink phenomenon serves as a protective mechanism in DLMs to prevent excessive information mixing. However, their unpredictable positions across diffusion steps undermine inference robustness. To resolve this, we propose a simple but effective extra sink token implemented via a modified attention mask. Specifically, we introduce a special token constrained to attend solely to itself, while remaining globally visible to all other tokens. Experimental results demonstrate that introducing a single extra token stabilizes attention sinks, substantially improving model performance. Crucially, further analysis confirms that the effectiveness of this token is independent of its position and characterized by negligible semantic content, validating its role as a robust and dedicated structural sink.
EComStage: Stage-wise and Orientation-specific Benchmarking for Large Language Models in E-commerce
Jan 06, 2026Large Language Model (LLM)-based agents are increasingly deployed in e-commerce applications to assist customer services in tasks such as product inquiries, recommendations, and order management. Existing benchmarks primarily evaluate whether these agents successfully complete the final task, overlooking the intermediate reasoning stages that are crucial for effective decision-making. To address this gap, we propose EComStage, a unified benchmark for evaluating agent-capable LLMs across the comprehensive stage-wise reasoning process: Perception (understanding user intent), Planning (formulating an action plan), and Action (executing the decision). EComStage evaluates LLMs through seven separate representative tasks spanning diverse e-commerce scenarios, with all samples human-annotated and quality-checked. Unlike prior benchmarks that focus only on customer-oriented interactions, EComStage also evaluates merchant-oriented scenarios, including promotion management, content review, and operational support relevant to real-world applications. We evaluate a wide range of over 30 LLMs, spanning from 1B to over 200B parameters, including open-source models and closed-source APIs, revealing stage/orientation-specific strengths and weaknesses. Our results provide fine-grained, actionable insights for designing and optimizing LLM-based agents in real-world e-commerce settings.
RedOne 2.0: Rethinking Domain-specific LLM Post-Training in Social Networking Services
Nov 10, 2025As a key medium for human interaction and information exchange, social networking services (SNS) pose unique challenges for large language models (LLMs): heterogeneous workloads, fast-shifting norms and slang, and multilingual, culturally diverse corpora that induce sharp distribution shift. Supervised fine-tuning (SFT) can specialize models but often triggers a ``seesaw'' between in-distribution gains and out-of-distribution robustness, especially for smaller models. To address these challenges, we introduce RedOne 2.0, an SNS-oriented LLM trained with a progressive, RL-prioritized post-training paradigm designed for rapid and stable adaptation. The pipeline consist in three stages: (1) Exploratory Learning on curated SNS corpora to establish initial alignment and identify systematic weaknesses; (2) Targeted Fine-Tuning that selectively applies SFT to the diagnosed gaps while mixing a small fraction of general data to mitigate forgetting; and (3) Refinement Learning that re-applies RL with SNS-centric signals to consolidate improvements and harmonize trade-offs across tasks. Across various tasks spanning three categories, our 4B scale model delivers an average improvements about 2.41 over the 7B sub-optimal baseline. Additionally, RedOne 2.0 achieves average performance lift about 8.74 from the base model with less than half the data required by SFT-centric method RedOne, evidencing superior data efficiency and stability at compact scales. Overall, RedOne 2.0 establishes a competitive, cost-effective baseline for domain-specific LLMs in SNS scenario, advancing capability without sacrificing robustness.
Interleaving Reasoning for Better Text-to-Image Generation
Sep 09, 2025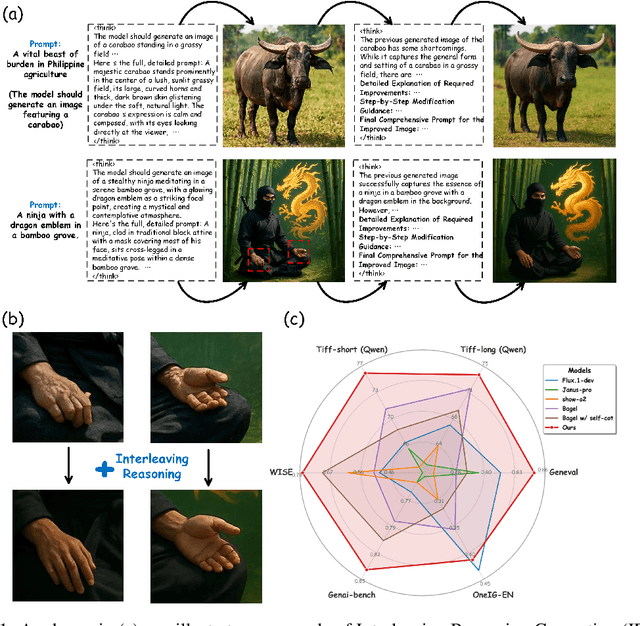

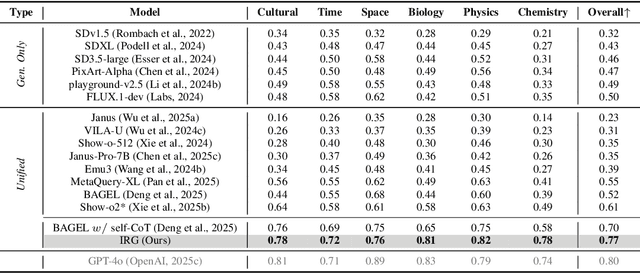
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
Act-as-Pet: Benchmarking the Abilities of Large Language Models as E-Pets in Social Network Services
Jun 04, 2025As interest in using Large Language Models (LLMs) for interactive and emotionally rich experiences grows, virtual pet companionship emerges as a novel yet underexplored application. Existing approaches focus on basic pet role-playing interactions without systematically benchmarking LLMs for comprehensive companionship. In this paper, we introduce Pet-Bench, a dedicated benchmark that evaluates LLMs across both self-interaction and human-interaction dimensions. Unlike prior work, Pet-Bench emphasizes self-evolution and developmental behaviors alongside interactive engagement, offering a more realistic reflection of pet companionship. It features diverse tasks such as intelligent scheduling, memory-based dialogues, and psychological conversations, with over 7,500 interaction instances designed to simulate complex pet behaviors. Evaluation of 28 LLMs reveals significant performance variations linked to model size and inherent capabilities, underscoring the need for specialized optimization in this domain. Pet-Bench serves as a foundational resource for benchmarking pet-related LLM abilities and advancing emotionally immersive human-pet interactions.
SNS-Bench-VL: Benchmarking Multimodal Large Language Models in Social Networking Services
May 29, 2025With the increasing integration of visual and textual content in Social Networking Services (SNS), evaluating the multimodal capabilities of Large Language Models (LLMs) is crucial for enhancing user experience, content understanding, and platform intelligence. Existing benchmarks primarily focus on text-centric tasks, lacking coverage of the multimodal contexts prevalent in modern SNS ecosystems. In this paper, we introduce SNS-Bench-VL, a comprehensive multimodal benchmark designed to assess the performance of Vision-Language LLMs in real-world social media scenarios. SNS-Bench-VL incorporates images and text across 8 multimodal tasks, including note comprehension, user engagement analysis, information retrieval, and personalized recommendation. It comprises 4,001 carefully curated multimodal question-answer pairs, covering single-choice, multiple-choice, and open-ended tasks. We evaluate over 25 state-of-the-art multimodal LLMs, analyzing their performance across tasks. Our findings highlight persistent challenges in multimodal social context comprehension. We hope SNS-Bench-VL will inspire future research towards robust, context-aware, and human-aligned multimodal intelligence for next-generation social networking services.