 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCAgent: Enhancing Group Chat Communication through Dialogue Agents System
Mar 05, 2026As a key form in online social platforms, group chat is a popular space for interest exchange or problem-solving, but its effectiveness is often hindered by inactivity and management challenges. While recent large language models (LLMs) have powered impressive one-to-one conversational agents, their seamlessly integration into multi-participant conversations remains unexplored. To address this gap, we introduce GCAgent, an LLM-driven system for enhancing group chats communication with both entertainment- and utility-oriented dialogue agents. The system comprises three tightly integrated modules: Agent Builder, which customizes agents to align with users' interests; Dialogue Manager, which coordinates dialogue states and manage agent invocations; and Interface Plugins, which reduce interaction barriers by three distinct tools. Through extensive experiment, GCAgent achieved an average score of 4.68 across various criteria and was preferred in 51.04\% of cases compared to its base model. Additionally, in real-world deployments over 350 days, it increased message volume by 28.80\%, significantly improving group activity and engagement. Overall, this work presents a practical blueprint for extending LLM-based dialogue agent from one-party chats to multi-party group scenarios.
RedOne 2.0: Rethinking Domain-specific LLM Post-Training in Social Networking Services
Nov 10, 2025As a key medium for human interaction and information exchange, social networking services (SNS) pose unique challenges for large language models (LLMs): heterogeneous workloads, fast-shifting norms and slang, and multilingual, culturally diverse corpora that induce sharp distribution shift. Supervised fine-tuning (SFT) can specialize models but often triggers a ``seesaw'' between in-distribution gains and out-of-distribution robustness, especially for smaller models. To address these challenges, we introduce RedOne 2.0, an SNS-oriented LLM trained with a progressive, RL-prioritized post-training paradigm designed for rapid and stable adaptation. The pipeline consist in three stages: (1) Exploratory Learning on curated SNS corpora to establish initial alignment and identify systematic weaknesses; (2) Targeted Fine-Tuning that selectively applies SFT to the diagnosed gaps while mixing a small fraction of general data to mitigate forgetting; and (3) Refinement Learning that re-applies RL with SNS-centric signals to consolidate improvements and harmonize trade-offs across tasks. Across various tasks spanning three categories, our 4B scale model delivers an average improvements about 2.41 over the 7B sub-optimal baseline. Additionally, RedOne 2.0 achieves average performance lift about 8.74 from the base model with less than half the data required by SFT-centric method RedOne, evidencing superior data efficiency and stability at compact scales. Overall, RedOne 2.0 establishes a competitive, cost-effective baseline for domain-specific LLMs in SNS scenario, advancing capability without sacrificing robustness.
PaRT: Enhancing Proactive Social Chatbots with Personalized Real-Time Retrieval
Apr 29, 2025Social chatbots have become essential intelligent companions in daily scenarios ranging from emotional support to personal interaction. However, conventional chatbots with passive response mechanisms usually rely on users to initiate or sustain dialogues by bringing up new topics, resulting in diminished engagement and shortened dialogue duration. In this paper, we present PaRT, a novel framework enabling context-aware proactive dialogues for social chatbots through personalized real-time retrieval and generation. Specifically, PaRT first integrates user profiles and dialogue context into a large language model (LLM), which is initially prompted to refine user queries and recognize their underlying intents for the upcoming conversation. Guided by refined intents, the LLM generates personalized dialogue topics, which then serve as targeted queries to retrieve relevant passages from RedNote. Finally, we prompt LLMs with summarized passages to generate knowledge-grounded and engagement-optimized responses. Our approach has been running stably in a real-world production environment for more than 30 days, achieving a 21.77\% improvement in the average duration of dialogues.
GenCLS++: Pushing the Boundaries of Generative Classification in LLMs Through Comprehensive SFT and RL Studies Across Diverse Datasets
Apr 28, 2025As a fundamental task in machine learning, text classification plays a crucial role in many areas. With the rapid scaling of Large Language Models (LLMs), particularly through reinforcement learning (RL), there is a growing need for more capable discriminators. Consequently, advances in classification are becoming increasingly vital for enhancing the overall capabilities of LLMs. Traditional discriminative methods map text to labels but overlook LLMs' intrinsic generative strengths. Generative classification addresses this by prompting the model to directly output labels. However, existing studies still rely on simple SFT alone, seldom probing the interplay between training and inference prompts, and no work has systematically leveraged RL for generative text classifiers and unified SFT, RL, and inference-time prompting in one framework. We bridge this gap with GenCLS++, a framework that jointly optimizes SFT and RL while systematically exploring five high-level strategy dimensions-in-context learning variants, category definitions, explicit uncertainty labels, semantically irrelevant numeric labels, and perplexity-based decoding-during both training and inference. After an SFT "policy warm-up," we apply RL with a simple rule-based reward, yielding sizable extra gains. Across seven datasets, GenCLS++ achieves an average accuracy improvement of 3.46% relative to the naive SFT baseline; on public datasets, this improvement rises to 4.00%. Notably, unlike reasoning-intensive tasks that benefit from explicit thinking processes, we find that classification tasks perform better without such reasoning steps. These insights into the role of explicit reasoning provide valuable guidance for future LLM applications.
Redefining Machine Translation on Social Network Services with Large Language Models
Apr 10, 2025The globalization of social interactions has heightened the need for machine translation (MT) on Social Network Services (SNS), yet traditional models struggle with culturally nuanced content like memes, slang, and pop culture references. While large language models (LLMs) have advanced general-purpose translation, their performance on SNS-specific content remains limited due to insufficient specialized training data and evaluation benchmarks. This paper introduces RedTrans, a 72B LLM tailored for SNS translation, trained on a novel dataset developed through three innovations: (1) Supervised Finetuning with Dual-LLM Back-Translation Sampling, an unsupervised sampling method using LLM-based back-translation to select diverse data for large-scale finetuning; (2) Rewritten Preference Optimization (RePO), an algorithm that identifies and corrects erroneous preference pairs through expert annotation, building reliable preference corpora; and (3) RedTrans-Bench, the first benchmark for SNS translation, evaluating phenomena like humor localization, emoji semantics, and meme adaptation. Experiments show RedTrans outperforms state-of-the-art LLMs. Besides, RedTrans has already been deployed in a real-world production environment, demonstrating that domain-specific adaptation, effectively bridges the gap between generic and culturally grounded translation systems.
Anaphor Assisted Document-Level Relation Extraction
Oct 28, 2023



Document-level relation extraction (DocRE) involves identifying relations between entities distributed in multiple sentences within a document. Existing methods focus on building a heterogeneous document graph to model the internal structure of an entity and the external interaction between entities. However, there are two drawbacks in existing methods. On one hand, anaphor plays an important role in reasoning to identify relations between entities but is ignored by these methods. On the other hand, these methods achieve cross-sentence entity interactions implicitly by utilizing a document or sentences as intermediate nodes. Such an approach has difficulties in learning fine-grained interactions between entities across different sentences, resulting in sub-optimal performance. To address these issues, we propose an Anaphor-Assisted (AA) framework for DocRE tasks. Experimental results on the widely-used datasets demonstrate that our model achieves a new state-of-the-art performance.
Sleep Staging Based on Multi Scale Dual Attention Network
Aug 14, 2021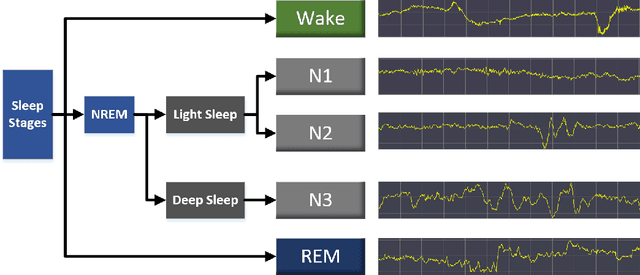

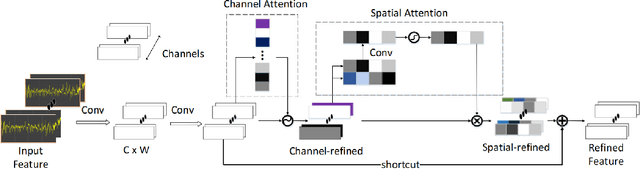

Sleep staging plays an important role on the diagnosis of sleep disorders. In general, experts classify sleep stages manually based on polysomnography (PSG), which is quite time-consuming. Meanwhile, the acquisition process of multiple signals is much complex, which can affect the subject's sleep. Therefore, the use of single-channel electroencephalogram (EEG) for automatic sleep staging has become a popular research topic. In the literature, a large number of sleep staging methods based on single-channel EEG have been proposed with promising results and achieve the preliminary automation of sleep staging. However, the performance for most of these methods in the N1 stage do not satisfy the needs of the diagnosis. In this paper, we propose a deep learning model multi scale dual attention network(MSDAN) based on raw EEG, which utilizes multi-scale convolution to extract features in different waveforms contained in the EEG signal, connects channel attention and spatial attention mechanisms in series to filter and highlight key information, and uses soft thresholding to remove redundant information. Experiments were conducted using two datasets with 5-fold cross-validation and hold-out validation method. The final average accuracy, overall accuracy, macro F1 score and Cohen's Kappa coefficient of the model reach 96.70%, 91.74%, 0.8231 and 0.8723 on the Sleep-EDF dataset, 96.14%, 90.35%, 0.7945 and 0.8284 on the Sleep-EDFx dataset. Significantly, our model performed superiorly in the N1 stage, with F1 scores of 54.41% and 52.79% on the two datasets respectively. The results show the superiority of our network over the existing methods, reaching a new state-of-the-art. In particular, the proposed method achieves excellent results in the N1 sleep stage compared to other methods.