 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVinci: A Real-time Embodied Smart Assistant based on Egocentric Vision-Language Model
Dec 30, 2024



We introduce Vinci, a real-time embodied smart assistant built upon an egocentric vision-language model. Designed for deployment on portable devices such as smartphones and wearable cameras, Vinci operates in an "always on" mode, continuously observing the environment to deliver seamless interaction and assistance. Users can wake up the system and engage in natural conversations to ask questions or seek assistance, with responses delivered through audio for hands-free convenience. With its ability to process long video streams in real-time, Vinci can answer user queries about current observations and historical context while also providing task planning based on past interactions. To further enhance usability, Vinci integrates a video generation module that creates step-by-step visual demonstrations for tasks that require detailed guidance. We hope that Vinci can establish a robust framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. We release the complete implementation for the development of the device in conjunction with a demo web platform to test uploaded videos at https://github.com/OpenGVLab/vinci.
Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment
Dec 26, 2024Current multimodal large language models (MLLMs) struggle with fine-grained or precise understanding of visuals though they give comprehensive perception and reasoning in a spectrum of vision applications. Recent studies either develop tool-using or unify specific visual tasks into the autoregressive framework, often at the expense of overall multimodal performance. To address this issue and enhance MLLMs with visual tasks in a scalable fashion, we propose Task Preference Optimization (TPO), a novel method that utilizes differentiable task preferences derived from typical fine-grained visual tasks. TPO introduces learnable task tokens that establish connections between multiple task-specific heads and the MLLM. By leveraging rich visual labels during training, TPO significantly enhances the MLLM's multimodal capabilities and task-specific performance. Through multi-task co-training within TPO, we observe synergistic benefits that elevate individual task performance beyond what is achievable through single-task training methodologies. Our instantiation of this approach with VideoChat and LLaVA demonstrates an overall 14.6% improvement in multimodal performance compared to baseline models. Additionally, MLLM-TPO demonstrates robust zero-shot capabilities across various tasks, performing comparably to state-of-the-art supervised models. The code will be released at https://github.com/OpenGVLab/TPO
CG-Bench: Clue-grounded Question Answering Benchmark for Long Video Understanding
Dec 16, 2024



Most existing video understanding benchmarks for multimodal large language models (MLLMs) focus only on short videos. The limited number of benchmarks for long video understanding often rely solely on multiple-choice questions (MCQs). However, because of the inherent limitation of MCQ-based evaluation and the increasing reasoning ability of MLLMs, models can give the current answer purely by combining short video understanding with elimination, without genuinely understanding the video content. To address this gap, we introduce CG-Bench, a novel benchmark designed for clue-grounded question answering in long videos. CG-Bench emphasizes the model's ability to retrieve relevant clues for questions, enhancing evaluation credibility. It features 1,219 manually curated videos categorized by a granular system with 14 primary categories, 171 secondary categories, and 638 tertiary categories, making it the largest benchmark for long video analysis. The benchmark includes 12,129 QA pairs in three major question types: perception, reasoning, and hallucination. Compensating the drawbacks of pure MCQ-based evaluation, we design two novel clue-based evaluation methods: clue-grounded white box and black box evaluations, to assess whether the model generates answers based on the correct understanding of the video. We evaluate multiple closed-source and open-source MLLMs on CG-Bench. Results indicate that current models significantly underperform in understanding long videos compared to short ones, and a significant gap exists between open-source and commercial models. We hope CG-Bench can advance the development of more trustworthy and capable MLLMs for long video understanding. All annotations and video data are released at https://cg-bench.github.io/leaderboard/.
Bootstrapping Language-Guided Navigation Learning with Self-Refining Data Flywheel
Dec 11, 2024
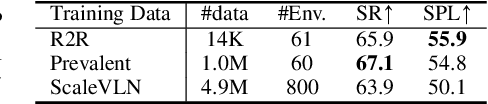

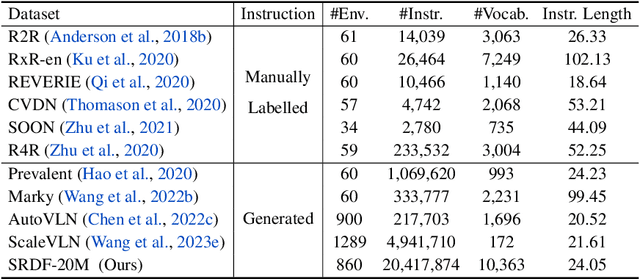
Creating high-quality data for training robust language-instructed agents is a long-lasting challenge in embodied AI. In this paper, we introduce a Self-Refining Data Flywheel (SRDF) that generates high-quality and large-scale navigational instruction-trajectory pairs by iteratively refining the data pool through the collaboration between two models, the instruction generator and the navigator, without any human-in-the-loop annotation. Specifically, SRDF starts with using a base generator to create an initial data pool for training a base navigator, followed by applying the trained navigator to filter the data pool. This leads to higher-fidelity data to train a better generator, which can, in turn, produce higher-quality data for training the next-round navigator. Such a flywheel establishes a data self-refining process, yielding a continuously improved and highly effective dataset for large-scale language-guided navigation learning. Our experiments demonstrate that after several flywheel rounds, the navigator elevates the performance boundary from 70% to 78% SPL on the classic R2R test set, surpassing human performance (76%) for the first time. Meanwhile, this process results in a superior generator, evidenced by a SPICE increase from 23.5 to 26.2, better than all previous VLN instruction generation methods. Finally, we demonstrate the scalability of our method through increasing environment and instruction diversity, and the generalization ability of our pre-trained navigator across various downstream navigation tasks, surpassing state-of-the-art methods by a large margin in all cases.
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Oct 25, 2024



Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.
TransAgent: Transfer Vision-Language Foundation Models with Heterogeneous Agent Collaboration
Oct 16, 2024Vision-language foundation models (such as CLIP) have recently shown their power in transfer learning, owing to large-scale image-text pre-training. However, target domain data in the downstream tasks can be highly different from the pre-training phase, which makes it hard for such a single model to generalize well. Alternatively, there exists a wide range of expert models that contain diversified vision and/or language knowledge pre-trained on different modalities, tasks, networks, and datasets. Unfortunately, these models are "isolated agents" with heterogeneous structures, and how to integrate their knowledge for generalizing CLIP-like models has not been fully explored. To bridge this gap, we propose a general and concise TransAgent framework, which transports the knowledge of the isolated agents in a unified manner, and effectively guides CLIP to generalize with multi-source knowledge distillation. With such a distinct framework, we flexibly collaborate with 11 heterogeneous agents to empower vision-language foundation models, without further cost in the inference phase. Finally, our TransAgent achieves state-of-the-art performance on 11 visual recognition datasets. Under the same low-shot setting, it outperforms the popular CoOp with around 10% on average, and 20% on EuroSAT which contains large domain shifts.
MUSES: 3D-Controllable Image Generation via Multi-Modal Agent Collaboration
Aug 21, 2024



Despite recent advancements in text-to-image generation, most existing methods struggle to create images with multiple objects and complex spatial relationships in 3D world. To tackle this limitation, we introduce a generic AI system, namely MUSES, for 3D-controllable image generation from user queries. Specifically, our MUSES addresses this challenging task by developing a progressive workflow with three key components, including (1) Layout Manager for 2D-to-3D layout lifting, (2) Model Engineer for 3D object acquisition and calibration, (3) Image Artist for 3D-to-2D image rendering. By mimicking the collaboration of human professionals, this multi-modal agent pipeline facilitates the effective and automatic creation of images with 3D-controllable objects, through an explainable integration of top-down planning and bottom-up generation. Additionally, we find that existing benchmarks lack detailed descriptions of complex 3D spatial relationships of multiple objects. To fill this gap, we further construct a new benchmark of T2I-3DisBench (3D image scene), which describes diverse 3D image scenes with 50 detailed prompts. Extensive experiments show the state-of-the-art performance of MUSES on both T2I-CompBench and T2I-3DisBench, outperforming recent strong competitors such as DALL-E 3 and Stable Diffusion 3. These results demonstrate a significant step of MUSES forward in bridging natural language, 2D image generation, and 3D world.
EgoVideo: Exploring Egocentric Foundation Model and Downstream Adaptation
Jun 27, 2024



In this report, we present our solutions to the EgoVis Challenges in CVPR 2024, including five tracks in the Ego4D challenge and three tracks in the EPIC-Kitchens challenge. Building upon the video-language two-tower model and leveraging our meticulously organized egocentric video data, we introduce a novel foundation model called EgoVideo. This model is specifically designed to cater to the unique characteristics of egocentric videos and provides strong support for our competition submissions. In the Ego4D challenges, we tackle various tasks including Natural Language Queries, Step Grounding, Moment Queries, Short-term Object Interaction Anticipation, and Long-term Action Anticipation. In addition, we also participate in the EPIC-Kitchens challenge, where we engage in the Action Recognition, Multiple Instance Retrieval, and Domain Adaptation for Action Recognition tracks. By adapting EgoVideo to these diverse tasks, we showcase its versatility and effectiveness in different egocentric video analysis scenarios, demonstrating the powerful representation ability of EgoVideo as an egocentric foundation model. Our codebase and pretrained models are publicly available at https://github.com/OpenGVLab/EgoVideo.
OmniCorpus: A Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
Jun 13, 2024



Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning. However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10 billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens. Compared to counterparts (e.g., MMC4, OBELICS), our dataset 1) has 15 times larger scales while maintaining good data quality; 2) features more diverse sources, including both English and non-English websites as well as video-centric websites; 3) is more flexible, easily degradable from an image-text interleaved format to pure text corpus and image-text pairs. Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research. Code and data are released at https://github.com/OpenGVLab/OmniCorpus.
OmniCorpus: An Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
Jun 12, 2024Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning. However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10 billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens. Compared to counterparts (e.g., MMC4, OBELICS), our dataset 1) has 15 times larger scales while maintaining good data quality; 2) features more diverse sources, including both English and non-English websites as well as video-centric websites; 3) is more flexible, easily degradable from an image-text interleaved format to pure text corpus and image-text pairs. Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research. Code and data are released at https://github.com/OpenGVLab/OmniCorpus.