 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-3DScene: 3D Scene Understanding by Customizing Masked Modeling with Informative-Preserved Reconstruction and Self-Distilled Consistency
Dec 20, 2022



Masked Modeling (MM) has demonstrated widespread success in various vision challenges, by reconstructing masked visual patches. Yet, applying MM for large-scale 3D scenes remains an open problem due to the data sparsity and scene complexity. The conventional random masking paradigm used in 2D images often causes a high risk of ambiguity when recovering the masked region of 3D scenes. To this end, we propose a novel informative-preserved reconstruction, which explores local statistics to discover and preserve the representative structured points, effectively enhancing the pretext masking task for 3D scene understanding. Integrated with a progressive reconstruction manner, our method can concentrate on modeling regional geometry and enjoy less ambiguity for masked reconstruction. Besides, such scenes with progressive masking ratios can also serve to self-distill their intrinsic spatial consistency, requiring to learn the consistent representations from unmasked areas. By elegantly combining informative-preserved reconstruction on masked areas and consistency self-distillation from unmasked areas, a unified framework called MM-3DScene is yielded. We conduct comprehensive experiments on a host of downstream tasks. The consistent improvement (e.g., +6.1 mAP@0.5 on object detection and +2.2% mIoU on semantic segmentation) demonstrates the superiority of our approach.
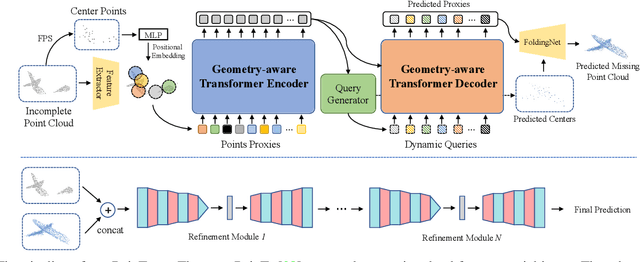
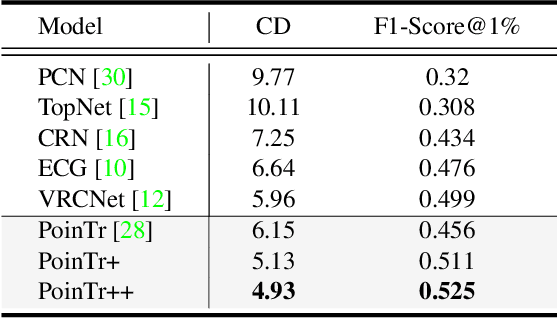
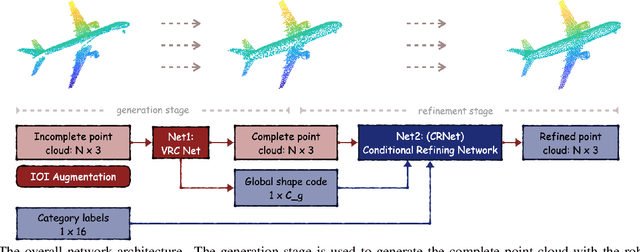
CP3: Unifying Point Cloud Completion by Pretrain-Prompt-Predict Paradigm
Jul 12, 2022



Point cloud completion aims to predict complete shape from its partial observation. Current approaches mainly consist of generation and refinement stages in a coarse-to-fine style. However, the generation stage often lacks robustness to tackle different incomplete variations, while the refinement stage blindly recovers point clouds without the semantic awareness. To tackle these challenges, we unify point cloud Completion by a generic Pretrain-Prompt-Predict paradigm, namely CP3. Inspired by prompting approaches from NLP, we creatively reinterpret point cloud generation and refinement as the prompting and predicting stages, respectively. Then, we introduce a concise self-supervised pretraining stage before prompting. It can effectively increase robustness of point cloud generation, by an Incompletion-Of-Incompletion (IOI) pretext task. Moreover, we develop a novel Semantic Conditional Refinement (SCR) network at the predicting stage. It can discriminatively modulate multi-scale refinement with the guidance of semantics. Finally, extensive experiments demonstrate that our CP3 outperforms the state-of-the-art methods with a large margin.
CP-Net: Contour-Perturbed Reconstruction Network for Self-Supervised Point Cloud Learning
Jan 20, 2022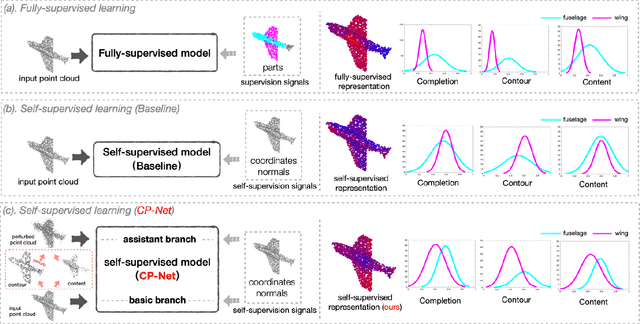
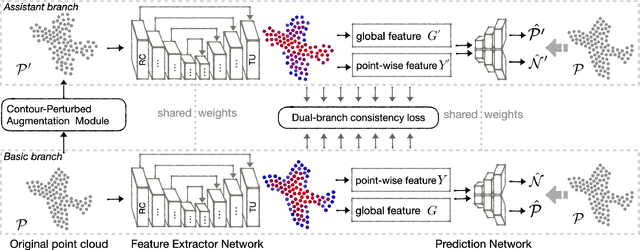
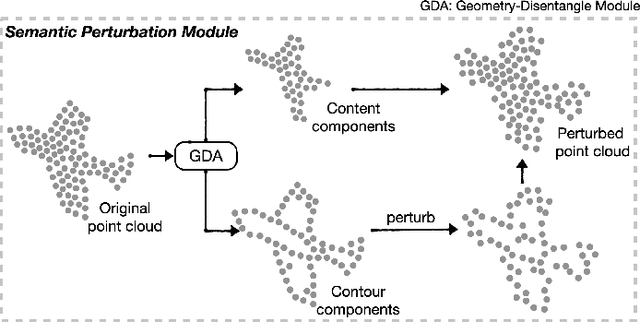

Self-supervised learning has not been fully explored for point cloud analysis. Current frameworks are mainly based on point cloud reconstruction. Given only 3D coordinates, such approaches tend to learn local geometric structures and contours, while failing in understanding high level semantic content. Consequently, they achieve unsatisfactory performance in downstream tasks such as classification, segmentation, etc. To fill this gap, we propose a generic Contour-Perturbed Reconstruction Network (CP-Net), which can effectively guide self-supervised reconstruction to learn semantic content in the point cloud, and thus promote discriminative power of point cloud representation. First, we introduce a concise contour-perturbed augmentation module for point cloud reconstruction. With guidance of geometry disentangling, we divide point cloud into contour and content components. Subsequently, we perturb the contour components and preserve the content components on the point cloud. As a result, self supervisor can effectively focus on semantic content, by reconstructing the original point cloud from such perturbed one. Second, we use this perturbed reconstruction as an assistant branch, to guide the learning of basic reconstruction branch via a distinct dual-branch consistency loss. In this case, our CP-Net not only captures structural contour but also learn semantic content for discriminative downstream tasks. Finally, we perform extensive experiments on a number of point cloud benchmarks. Part segmentation results demonstrate that our CP-Net (81.5% of mIoU) outperforms the previous self-supervised models, and narrows the gap with the fully-supervised methods. For classification, we get a competitive result with the fully-supervised methods on ModelNet40 (92.5% accuracy) and ScanObjectNN (87.9% accuracy). The codes and models will be released afterwards.
Multi-View Partial Point Cloud Challenge 2021 on Completion and Registration: Methods and Results
Dec 22, 2021
As real-scanned point clouds are mostly partial due to occlusions and viewpoints, reconstructing complete 3D shapes based on incomplete observations becomes a fundamental problem for computer vision. With a single incomplete point cloud, it becomes the partial point cloud completion problem. Given multiple different observations, 3D reconstruction can be addressed by performing partial-to-partial point cloud registration. Recently, a large-scale Multi-View Partial (MVP) point cloud dataset has been released, which consists of over 100,000 high-quality virtual-scanned partial point clouds. Based on the MVP dataset, this paper reports methods and results in the Multi-View Partial Point Cloud Challenge 2021 on Completion and Registration. In total, 128 participants registered for the competition, and 31 teams made valid submissions. The top-ranked solutions will be analyzed, and then we will discuss future research directions.
Investigate Indistinguishable Points in Semantic Segmentation of 3D Point Cloud
Mar 18, 2021



This paper investigates the indistinguishable points (difficult to predict label) in semantic segmentation for large-scale 3D point clouds. The indistinguishable points consist of those located in complex boundary, points with similar local textures but different categories, and points in isolate small hard areas, which largely harm the performance of 3D semantic segmentation. To address this challenge, we propose a novel Indistinguishable Area Focalization Network (IAF-Net), which selects indistinguishable points adaptively by utilizing the hierarchical semantic features and enhances fine-grained features for points especially those indistinguishable points. We also introduce multi-stage loss to improve the feature representation in a progressive way. Moreover, in order to analyze the segmentation performances of indistinguishable areas, we propose a new evaluation metric called Indistinguishable Points Based Metric (IPBM). Our IAF-Net achieves the comparable results with state-of-the-art performance on several popular 3D point cloud datasets e.g. S3DIS and ScanNet, and clearly outperforms other methods on IPBM.
Learning Geometry-Disentangled Representation for Complementary Understanding of 3D Object Point Cloud
Jan 08, 2021



In 2D image processing, some attempts decompose images into high and low frequency components for describing edge and smooth parts respectively. Similarly, the contour and flat area of 3D objects, such as the boundary and seat area of a chair, describe different but also complementary geometries. However, such investigation is lost in previous deep networks that understand point clouds by directly treating all points or local patches equally. To solve this problem, we propose Geometry-Disentangled Attention Network (GDANet). GDANet introduces Geometry-Disentangle Module to dynamically disentangle point clouds into the contour and flat part of 3D objects, respectively denoted by sharp and gentle variation components. Then GDANet exploits Sharp-Gentle Complementary Attention Module that regards the features from sharp and gentle variation components as two holistic representations, and pays different attentions to them while fusing them respectively with original point cloud features. In this way, our method captures and refines the holistic and complementary 3D geometric semantics from two distinct disentangled components to supplement the local information. Extensive experiments on 3D object classification and segmentation benchmarks demonstrate that GDANet achieves the state-of-the-arts with fewer parameters.
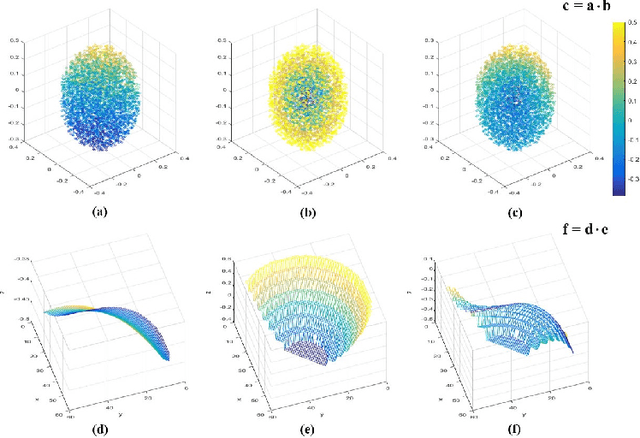
Geometry Sharing Network for 3D Point Cloud Classification and Segmentation
Dec 23, 2019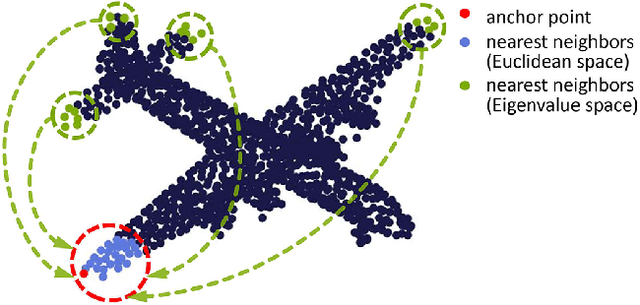
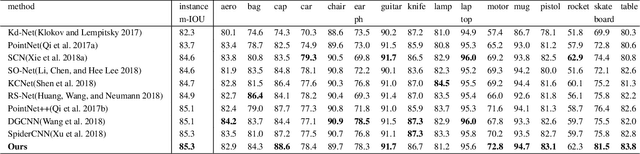
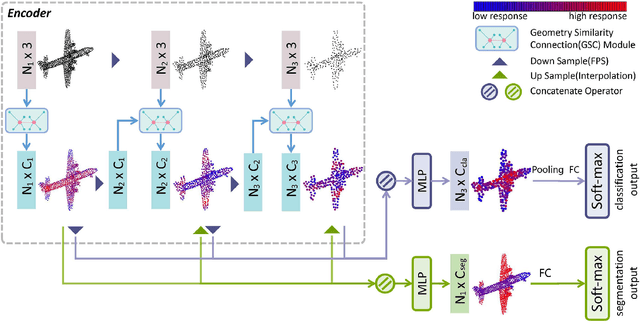
In spite of the recent progresses on classifying 3D point cloud with deep CNNs, large geometric transformations like rotation and translation remain challenging problem and harm the final classification performance. To address this challenge, we propose Geometry Sharing Network (GS-Net) which effectively learns point descriptors with holistic context to enhance the robustness to geometric transformations. Compared with previous 3D point CNNs which perform convolution on nearby points, GS-Net can aggregate point features in a more global way. Specially, GS-Net consists of Geometry Similarity Connection (GSC) modules which exploit Eigen-Graph to group distant points with similar and relevant geometric information, and aggregate features from nearest neighbors in both Euclidean space and Eigenvalue space. This design allows GS-Net to efficiently capture both local and holistic geometric features such as symmetry, curvature, convexity and connectivity. Theoretically, we show the nearest neighbors of each point in Eigenvalue space are invariant to rotation and translation. We conduct extensive experiments on public datasets, ModelNet40, ShapeNet Part. Experiments demonstrate that GS-Net achieves the state-of-the-art performances on major datasets, 93.3% on ModelNet40, and are more robust to geometric transformations.
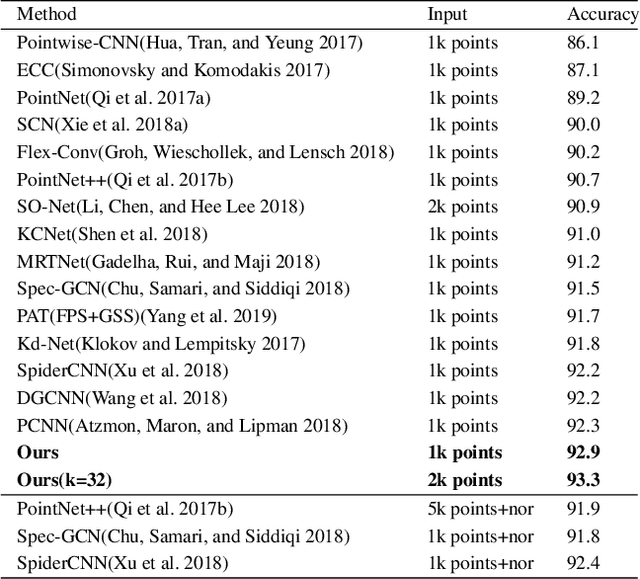
SpiderCNN: Deep Learning on Point Sets with Parameterized Convolutional Filters
Sep 12, 2018


Deep neural networks have enjoyed remarkable success for various vision tasks, however it remains challenging to apply CNNs to domains lacking a regular underlying structures such as 3D point clouds. Towards this we propose a novel convolutional architecture, termed SpiderCNN, to efficiently extract geometric features from point clouds. SpiderCNN is comprised of units called SpiderConv, which extend convolutional operations from regular grids to irregular point sets that can be embedded in R^n, by parametrizing a family of convolutional filters. We design the filter as a product of a simple step function that captures local geodesic information and a Taylor polynomial that ensures the expressiveness. SpiderCNN inherits the multi-scale hierarchical architecture from classical CNNs, which allows it to extract semantic deep features. Experiments on ModelNet40 demonstrate that SpiderCNN achieves state-of-the-art accuracy 92.4% on standard benchmarks, and shows competitive performance on segmentation task.