 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpleGVR: A Simple Baseline for Latent-Cascaded Video Super-Resolution
Jun 24, 2025Latent diffusion models have emerged as a leading paradigm for efficient video generation. However, as user expectations shift toward higher-resolution outputs, relying solely on latent computation becomes inadequate. A promising approach involves decoupling the process into two stages: semantic content generation and detail synthesis. The former employs a computationally intensive base model at lower resolutions, while the latter leverages a lightweight cascaded video super-resolution (VSR) model to achieve high-resolution output. In this work, we focus on studying key design principles for latter cascaded VSR models, which are underexplored currently. First, we propose two degradation strategies to generate training pairs that better mimic the output characteristics of the base model, ensuring alignment between the VSR model and its upstream generator. Second, we provide critical insights into VSR model behavior through systematic analysis of (1) timestep sampling strategies, (2) noise augmentation effects on low-resolution (LR) inputs. These findings directly inform our architectural and training innovations. Finally, we introduce interleaving temporal unit and sparse local attention to achieve efficient training and inference, drastically reducing computational overhead. Extensive experiments demonstrate the superiority of our framework over existing methods, with ablation studies confirming the efficacy of each design choice. Our work establishes a simple yet effective baseline for cascaded video super-resolution generation, offering practical insights to guide future advancements in efficient cascaded synthesis systems.
FilMaster: Bridging Cinematic Principles and Generative AI for Automated Film Generation
Jun 23, 2025AI-driven content creation has shown potential in film production. However, existing film generation systems struggle to implement cinematic principles and thus fail to generate professional-quality films, particularly lacking diverse camera language and cinematic rhythm. This results in templated visuals and unengaging narratives. To address this, we introduce FilMaster, an end-to-end AI system that integrates real-world cinematic principles for professional-grade film generation, yielding editable, industry-standard outputs. FilMaster is built on two key principles: (1) learning cinematography from extensive real-world film data and (2) emulating professional, audience-centric post-production workflows. Inspired by these principles, FilMaster incorporates two stages: a Reference-Guided Generation Stage which transforms user input to video clips, and a Generative Post-Production Stage which transforms raw footage into audiovisual outputs by orchestrating visual and auditory elements for cinematic rhythm. Our generation stage highlights a Multi-shot Synergized RAG Camera Language Design module to guide the AI in generating professional camera language by retrieving reference clips from a vast corpus of 440,000 film clips. Our post-production stage emulates professional workflows by designing an Audience-Centric Cinematic Rhythm Control module, including Rough Cut and Fine Cut processes informed by simulated audience feedback, for effective integration of audiovisual elements to achieve engaging content. The system is empowered by generative AI models like (M)LLMs and video generation models. Furthermore, we introduce FilmEval, a comprehensive benchmark for evaluating AI-generated films. Extensive experiments show FilMaster's superior performance in camera language design and cinematic rhythm control, advancing generative AI in professional filmmaking.
FullDiT2: Efficient In-Context Conditioning for Video Diffusion Transformers
Jun 05, 2025



Fine-grained and efficient controllability on video diffusion transformers has raised increasing desires for the applicability. Recently, In-context Conditioning emerged as a powerful paradigm for unified conditional video generation, which enables diverse controls by concatenating varying context conditioning signals with noisy video latents into a long unified token sequence and jointly processing them via full-attention, e.g., FullDiT. Despite their effectiveness, these methods face quadratic computation overhead as task complexity increases, hindering practical deployment. In this paper, we study the efficiency bottleneck neglected in original in-context conditioning video generation framework. We begin with systematic analysis to identify two key sources of the computation inefficiencies: the inherent redundancy within context condition tokens and the computational redundancy in context-latent interactions throughout the diffusion process. Based on these insights, we propose FullDiT2, an efficient in-context conditioning framework for general controllability in both video generation and editing tasks, which innovates from two key perspectives. Firstly, to address the token redundancy, FullDiT2 leverages a dynamic token selection mechanism to adaptively identify important context tokens, reducing the sequence length for unified full-attention. Additionally, a selective context caching mechanism is devised to minimize redundant interactions between condition tokens and video latents. Extensive experiments on six diverse conditional video editing and generation tasks demonstrate that FullDiT2 achieves significant computation reduction and 2-3 times speedup in averaged time cost per diffusion step, with minimal degradation or even higher performance in video generation quality. The project page is at \href{https://fulldit2.github.io/}{https://fulldit2.github.io/}.
UNIC: Unified In-Context Video Editing
Jun 04, 2025

Recent advances in text-to-video generation have sparked interest in generative video editing tasks. Previous methods often rely on task-specific architectures (e.g., additional adapter modules) or dedicated customizations (e.g., DDIM inversion), which limit the integration of versatile editing conditions and the unification of various editing tasks. In this paper, we introduce UNified In-Context Video Editing (UNIC), a simple yet effective framework that unifies diverse video editing tasks within a single model in an in-context manner. To achieve this unification, we represent the inputs of various video editing tasks as three types of tokens: the source video tokens, the noisy video latent, and the multi-modal conditioning tokens that vary according to the specific editing task. Based on this formulation, our key insight is to integrate these three types into a single consecutive token sequence and jointly model them using the native attention operations of DiT, thereby eliminating the need for task-specific adapter designs. Nevertheless, direct task unification under this framework is challenging, leading to severe token collisions and task confusion due to the varying video lengths and diverse condition modalities across tasks. To address these, we introduce task-aware RoPE to facilitate consistent temporal positional encoding, and condition bias that enables the model to clearly differentiate different editing tasks. This allows our approach to adaptively perform different video editing tasks by referring the source video and varying condition tokens "in context", and support flexible task composition. To validate our method, we construct a unified video editing benchmark containing six representative video editing tasks. Results demonstrate that our unified approach achieves superior performance on each task and exhibits emergent task composition abilities.
Can LLMs Learn to Map the World from Local Descriptions?
May 27, 2025Recent advances in Large Language Models (LLMs) have demonstrated strong capabilities in tasks such as code and mathematics. However, their potential to internalize structured spatial knowledge remains underexplored. This study investigates whether LLMs, grounded in locally relative human observations, can construct coherent global spatial cognition by integrating fragmented relational descriptions. We focus on two core aspects of spatial cognition: spatial perception, where models infer consistent global layouts from local positional relationships, and spatial navigation, where models learn road connectivity from trajectory data and plan optimal paths between unconnected locations. Experiments conducted in a simulated urban environment demonstrate that LLMs not only generalize to unseen spatial relationships between points of interest (POIs) but also exhibit latent representations aligned with real-world spatial distributions. Furthermore, LLMs can learn road connectivity from trajectory descriptions, enabling accurate path planning and dynamic spatial awareness during navigation.
Scaling Image and Video Generation via Test-Time Evolutionary Search
May 23, 2025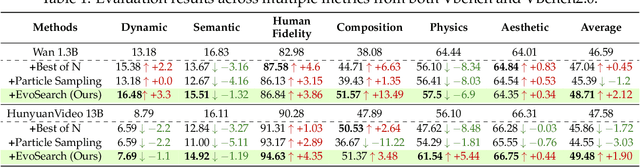

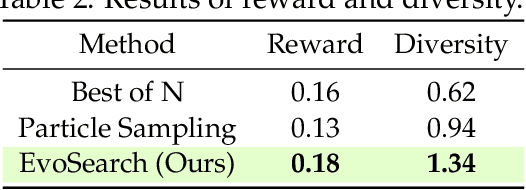
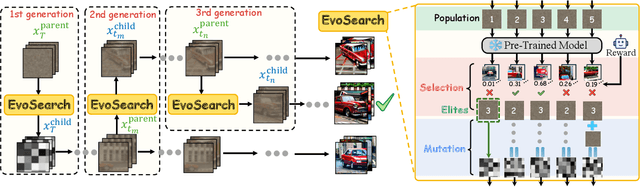
As the marginal cost of scaling computation (data and parameters) during model pre-training continues to increase substantially, test-time scaling (TTS) has emerged as a promising direction for improving generative model performance by allocating additional computation at inference time. While TTS has demonstrated significant success across multiple language tasks, there remains a notable gap in understanding the test-time scaling behaviors of image and video generative models (diffusion-based or flow-based models). Although recent works have initiated exploration into inference-time strategies for vision tasks, these approaches face critical limitations: being constrained to task-specific domains, exhibiting poor scalability, or falling into reward over-optimization that sacrifices sample diversity. In this paper, we propose \textbf{Evo}lutionary \textbf{Search} (EvoSearch), a novel, generalist, and efficient TTS method that effectively enhances the scalability of both image and video generation across diffusion and flow models, without requiring additional training or model expansion. EvoSearch reformulates test-time scaling for diffusion and flow models as an evolutionary search problem, leveraging principles from biological evolution to efficiently explore and refine the denoising trajectory. By incorporating carefully designed selection and mutation mechanisms tailored to the stochastic differential equation denoising process, EvoSearch iteratively generates higher-quality offspring while preserving population diversity. Through extensive evaluation across both diffusion and flow architectures for image and video generation tasks, we demonstrate that our method consistently outperforms existing approaches, achieves higher diversity, and shows strong generalizability to unseen evaluation metrics. Our project is available at the website https://tinnerhrhe.github.io/evosearch.
Flow-GRPO: Training Flow Matching Models via Online RL
May 08, 2025



We propose Flow-GRPO, the first method integrating online reinforcement learning (RL) into flow matching models. Our approach uses two key strategies: (1) an ODE-to-SDE conversion that transforms a deterministic Ordinary Differential Equation (ODE) into an equivalent Stochastic Differential Equation (SDE) that matches the original model's marginal distribution at all timesteps, enabling statistical sampling for RL exploration; and (2) a Denoising Reduction strategy that reduces training denoising steps while retaining the original inference timestep number, significantly improving sampling efficiency without performance degradation. Empirically, Flow-GRPO is effective across multiple text-to-image tasks. For complex compositions, RL-tuned SD3.5 generates nearly perfect object counts, spatial relations, and fine-grained attributes, boosting GenEval accuracy from $63\%$ to $95\%$. In visual text rendering, its accuracy improves from $59\%$ to $92\%$, significantly enhancing text generation. Flow-GRPO also achieves substantial gains in human preference alignment. Notably, little to no reward hacking occurred, meaning rewards did not increase at the cost of image quality or diversity, and both remained stable in our experiments.
A Survey of Interactive Generative Video
Apr 30, 2025



Interactive Generative Video (IGV) has emerged as a crucial technology in response to the growing demand for high-quality, interactive video content across various domains. In this paper, we define IGV as a technology that combines generative capabilities to produce diverse high-quality video content with interactive features that enable user engagement through control signals and responsive feedback. We survey the current landscape of IGV applications, focusing on three major domains: 1) gaming, where IGV enables infinite exploration in virtual worlds; 2) embodied AI, where IGV serves as a physics-aware environment synthesizer for training agents in multimodal interaction with dynamically evolving scenes; and 3) autonomous driving, where IGV provides closed-loop simulation capabilities for safety-critical testing and validation. To guide future development, we propose a comprehensive framework that decomposes an ideal IGV system into five essential modules: Generation, Control, Memory, Dynamics, and Intelligence. Furthermore, we systematically analyze the technical challenges and future directions in realizing each component for an ideal IGV system, such as achieving real-time generation, enabling open-domain control, maintaining long-term coherence, simulating accurate physics, and integrating causal reasoning. We believe that this systematic analysis will facilitate future research and development in the field of IGV, ultimately advancing the technology toward more sophisticated and practical applications.
BookWorld: From Novels to Interactive Agent Societies for Creative Story Generation
Apr 20, 2025



Recent advances in large language models (LLMs) have enabled social simulation through multi-agent systems. Prior efforts focus on agent societies created from scratch, assigning agents with newly defined personas. However, simulating established fictional worlds and characters remain largely underexplored, despite its significant practical value. In this paper, we introduce BookWorld, a comprehensive system for constructing and simulating book-based multi-agent societies. BookWorld's design covers comprehensive real-world intricacies, including diverse and dynamic characters, fictional worldviews, geographical constraints and changes, e.t.c. BookWorld enables diverse applications including story generation, interactive games and social simulation, offering novel ways to extend and explore beloved fictional works. Through extensive experiments, we demonstrate that BookWorld generates creative, high-quality stories while maintaining fidelity to the source books, surpassing previous methods with a win rate of 75.36%. The code of this paper can be found at the project page: https://bookworld2025.github.io/.
Any2Caption:Interpreting Any Condition to Caption for Controllable Video Generation
Mar 31, 2025



To address the bottleneck of accurate user intent interpretation within the current video generation community, we present Any2Caption, a novel framework for controllable video generation under any condition. The key idea is to decouple various condition interpretation steps from the video synthesis step. By leveraging modern multimodal large language models (MLLMs), Any2Caption interprets diverse inputs--text, images, videos, and specialized cues such as region, motion, and camera poses--into dense, structured captions that offer backbone video generators with better guidance. We also introduce Any2CapIns, a large-scale dataset with 337K instances and 407K conditions for any-condition-to-caption instruction tuning. Comprehensive evaluations demonstrate significant improvements of our system in controllability and video quality across various aspects of existing video generation models. Project Page: https://sqwu.top/Any2Cap/