 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Oriented Pedestrian Motion and Scene Occupancy Forecasting
Jan 07, 2021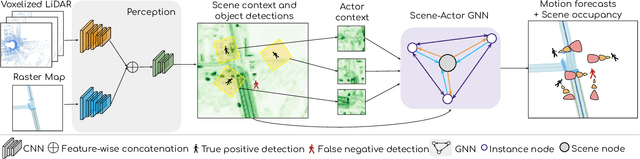
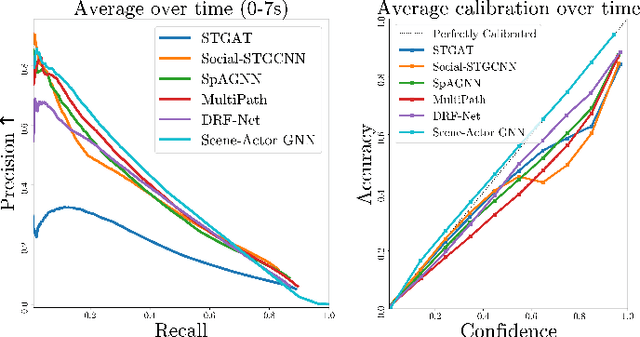
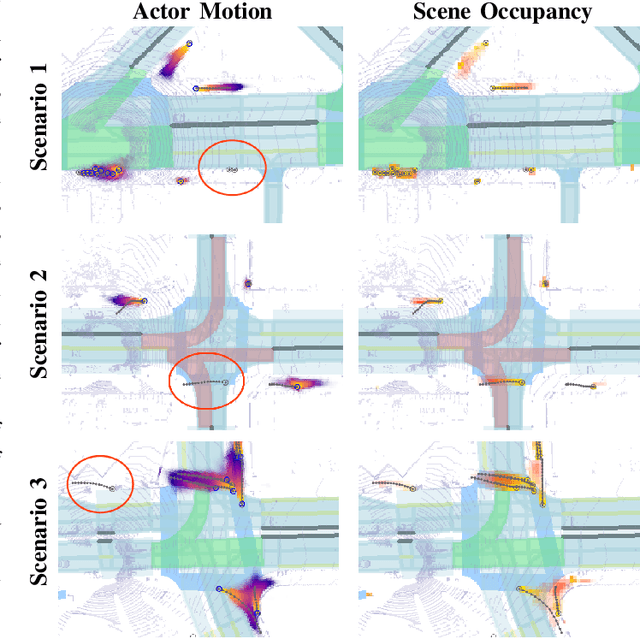
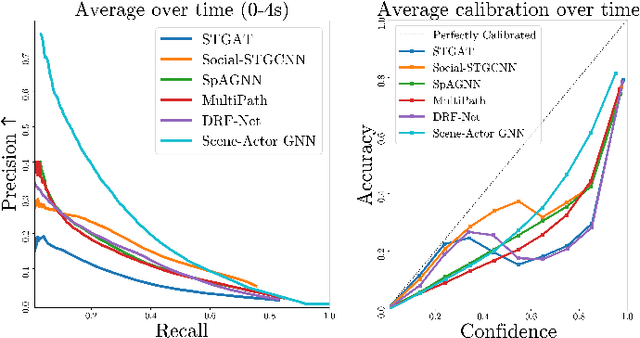
In this paper, we address the important problem in self-driving of forecasting multi-pedestrian motion and their shared scene occupancy map, critical for safe navigation. Our contributions are two-fold. First, we advocate for predicting both the individual motions as well as the scene occupancy map in order to effectively deal with missing detections caused by postprocessing, e.g., confidence thresholding and non-maximum suppression. Second, we propose a Scene-Actor Graph Neural Network (SA-GNN) which preserves the relative spatial information of pedestrians via 2D convolution, and captures the interactions among pedestrians within the same scene, including those that have not been detected, via message passing. On two large-scale real-world datasets, nuScenes and ATG4D, we showcase that our scene-occupancy predictions are more accurate and better calibrated than those from state-of-the-art motion forecasting methods, while also matching their performance in pedestrian motion forecasting metrics.
ShapeAdv: Generating Shape-Aware Adversarial 3D Point Clouds
May 24, 2020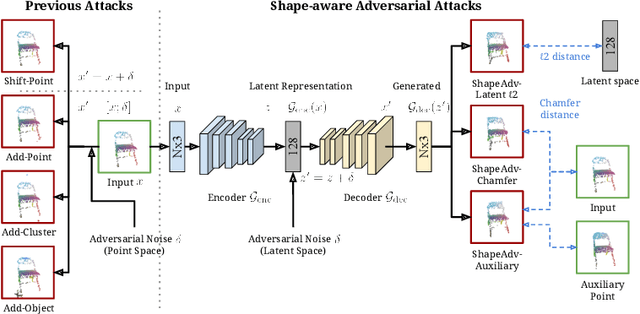
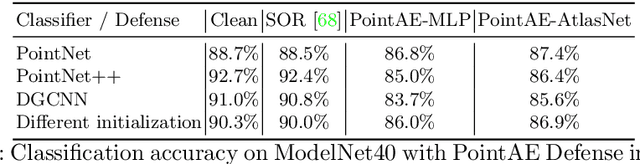
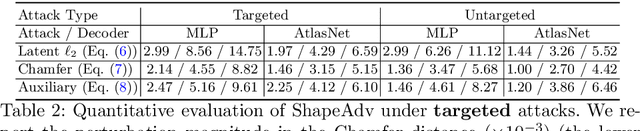
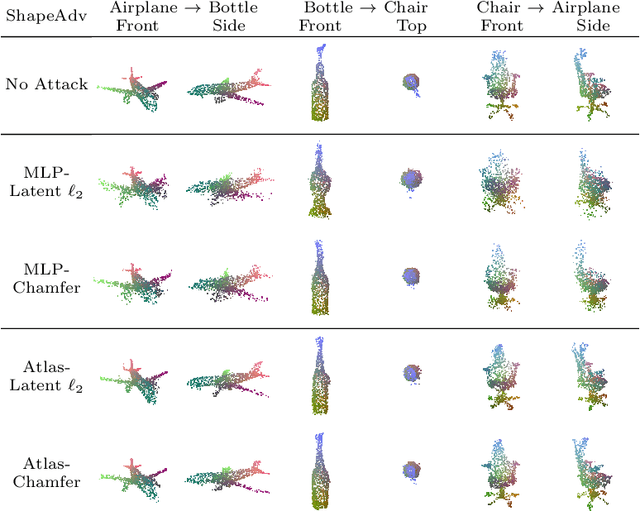
We introduce ShapeAdv, a novel framework to study shape-aware adversarial perturbations that reflect the underlying shape variations (e.g., geometric deformations and structural differences) in the 3D point cloud space. We develop shape-aware adversarial 3D point cloud attacks by leveraging the learned latent space of a point cloud auto-encoder where the adversarial noise is applied in the latent space. Specifically, we propose three different variants including an exemplar-based one by guiding the shape deformation with auxiliary data, such that the generated point cloud resembles the shape morphing between objects in the same category. Different from prior works, the resulting adversarial 3D point clouds reflect the shape variations in the 3D point cloud space while still being close to the original one. In addition, experimental evaluations on the ModelNet40 benchmark demonstrate that our adversaries are more difficult to defend with existing point cloud defense methods and exhibit a higher attack transferability across classifiers. Our shape-aware adversarial attacks are orthogonal to existing point cloud based attacks and shed light on the vulnerability of 3D deep neural networks.
PT2PC: Learning to Generate 3D Point Cloud Shapes from Part Tree Conditions
Mar 19, 2020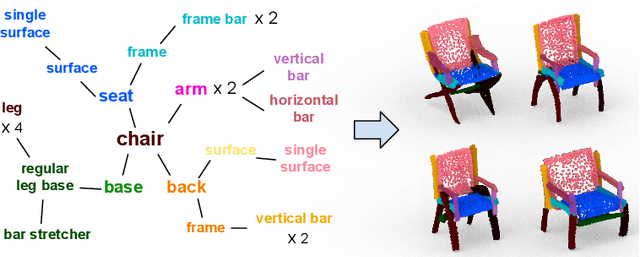
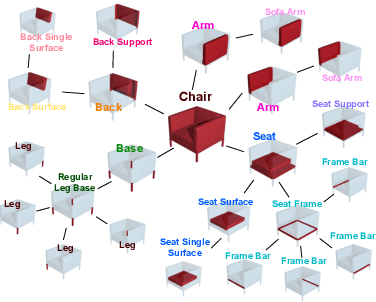
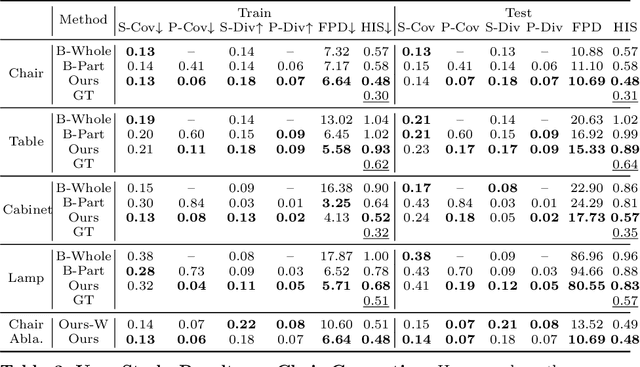
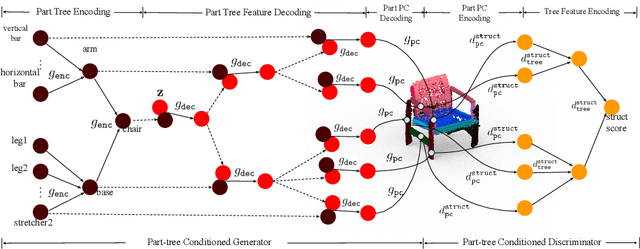
3D generative shape modeling is a fundamental research area in computer vision and interactive computer graphics, with many real-world applications. This paper investigates the novel problem of generating 3D shape point cloud geometry from a symbolic part tree representation. In order to learn such a conditional shape generation procedure in an end-to-end fashion, we propose a conditional GAN "part tree"-to-"point cloud" model (PT2PC) that disentangles the structural and geometric factors. The proposed model incorporates the part tree condition into the architecture design by passing messages top-down and bottom-up along the part tree hierarchy. Experimental results and user study demonstrate the strengths of our method in generating perceptually plausible and diverse 3D point clouds, given the part tree condition. We also propose a novel structural measure for evaluating if the generated shape point clouds satisfy the part tree conditions.
Data-Efficient Learning for Sim-to-Real Robotic Grasping using Deep Point Cloud Prediction Networks
Jun 21, 2019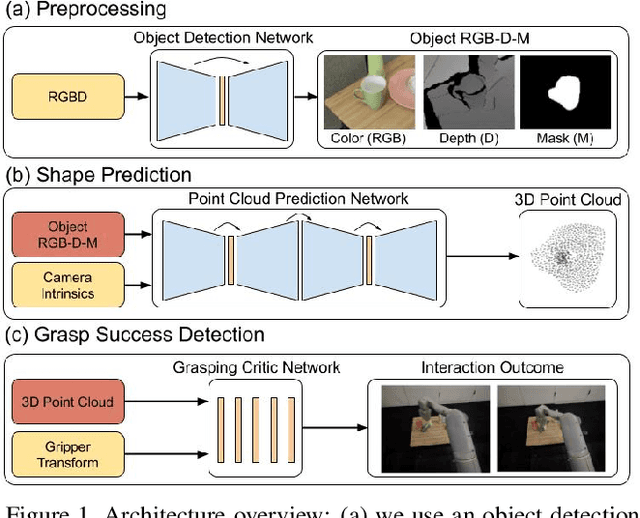
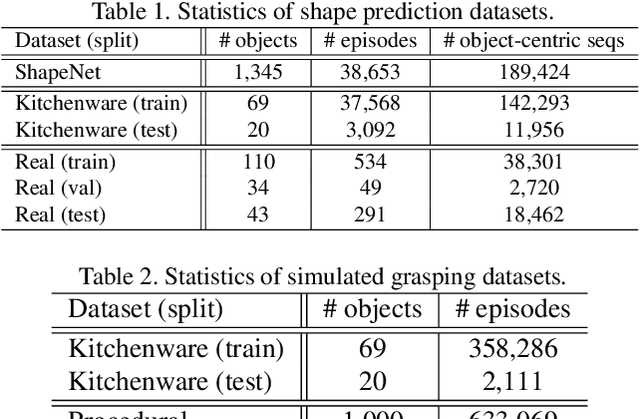
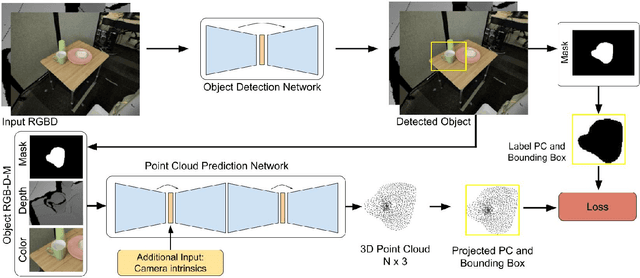
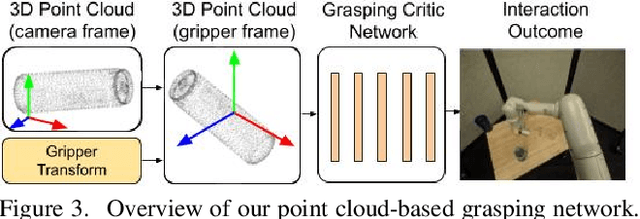
Training a deep network policy for robot manipulation is notoriously costly and time consuming as it depends on collecting a significant amount of real world data. To work well in the real world, the policy needs to see many instances of the task, including various object arrangements in the scene as well as variations in object geometry, texture, material, and environmental illumination. In this paper, we propose a method that learns to perform table-top instance grasping of a wide variety of objects while using no real world grasping data, outperforming the baseline using 2.5D shape by 10%. Our method learns 3D point cloud of object, and use that to train a domain-invariant grasping policy. We formulate the learning process as a two-step procedure: 1) Learning a domain-invariant 3D shape representation of objects from about 76K episodes in simulation and about 530 episodes in the real world, where each episode lasts less than a minute and 2) Learning a critic grasping policy in simulation only based on the 3D shape representation from step 1. Our real world data collection in step 1 is both cheaper and faster compared to existing approaches as it only requires taking multiple snapshots of the scene using a RGBD camera. Finally, the learned 3D representation is not specific to grasping, and can potentially be used in other interaction tasks.
SemanticAdv: Generating Adversarial Examples via Attribute-conditional Image Editing
Jun 19, 2019

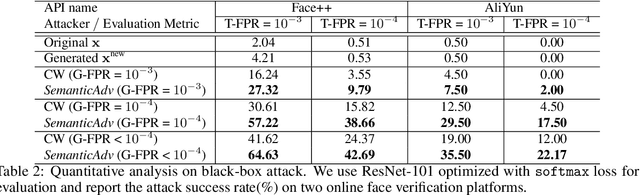
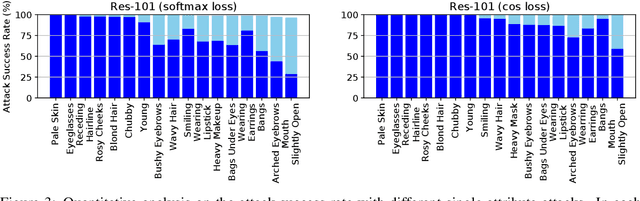
Deep neural networks (DNNs) have achieved great success in various applications due to their strong expressive power. However, recent studies have shown that DNNs are vulnerable to adversarial examples which are manipulated instances targeting to mislead DNNs to make incorrect predictions. Currently, most such adversarial examples try to guarantee "subtle perturbation" by limiting its $L_p$ norm. In this paper, we aim to explore the impact of semantic manipulation on DNNs predictions by manipulating the semantic attributes of images and generate "unrestricted adversarial examples". Such semantic based perturbation is more practical compared with pixel level manipulation. In particular, we propose an algorithm SemanticAdv which leverages disentangled semantic factors to generate adversarial perturbation via altering either single or a combination of semantic attributes. We conduct extensive experiments to show that the semantic based adversarial examples can not only fool different learning tasks such as face verification and landmark detection, but also achieve high attack success rate against real-world black-box services such as Azure face verification service. Such structured adversarial examples with controlled semantic manipulation can shed light on further understanding about vulnerabilities of DNNs as well as potential defensive approaches.
Learning Hierarchical Semantic Image Manipulation through Structured Representations
Aug 28, 2018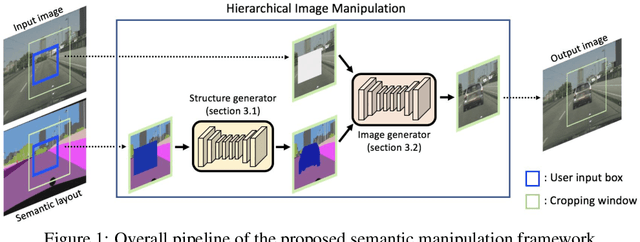


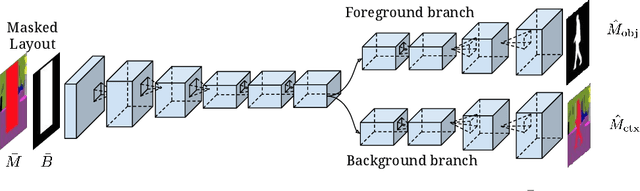
Understanding, reasoning, and manipulating semantic concepts of images have been a fundamental research problem for decades. Previous work mainly focused on direct manipulation on natural image manifold through color strokes, key-points, textures, and holes-to-fill. In this work, we present a novel hierarchical framework for semantic image manipulation. Key to our hierarchical framework is that we employ a structured semantic layout as our intermediate representation for manipulation. Initialized with coarse-level bounding boxes, our structure generator first creates pixel-wise semantic layout capturing the object shape, object-object interactions, and object-scene relations. Then our image generator fills in the pixel-level textures guided by the semantic layout. Such framework allows a user to manipulate images at object-level by adding, removing, and moving one bounding box at a time. Experimental evaluations demonstrate the advantages of the hierarchical manipulation framework over existing image generation and context hole-filing models, both qualitatively and quantitatively. Benefits of the hierarchical framework are further demonstrated in applications such as semantic object manipulation, interactive image editing, and data-driven image manipulation.
MT-VAE: Learning Motion Transformations to Generate Multimodal Human Dynamics
Aug 14, 2018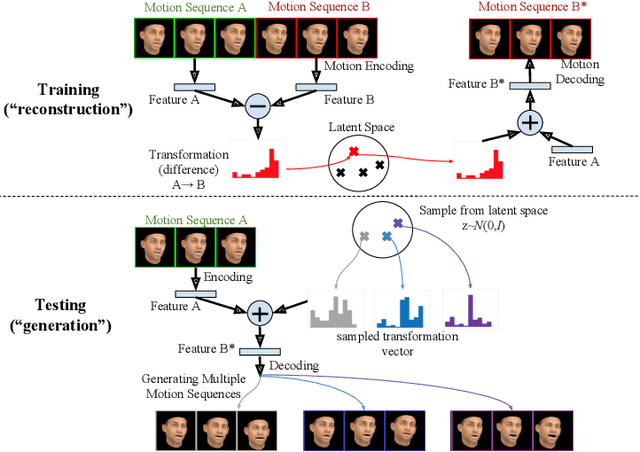
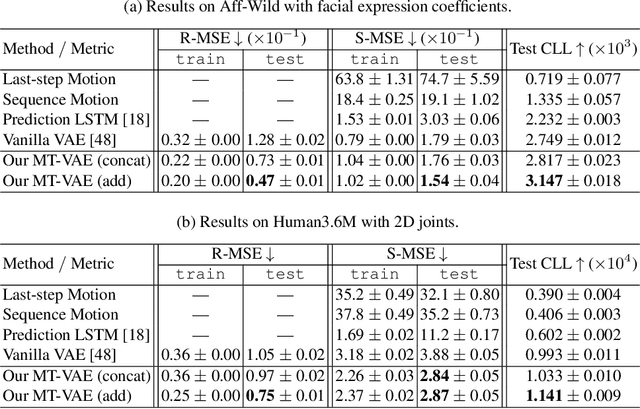
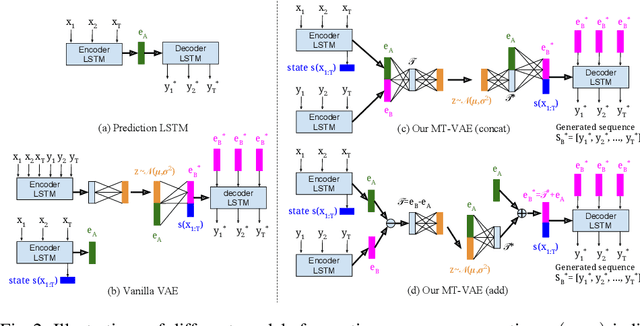

Long-term human motion can be represented as a series of motion modes---motion sequences that capture short-term temporal dynamics---with transitions between them. We leverage this structure and present a novel Motion Transformation Variational Auto-Encoders (MT-VAE) for learning motion sequence generation. Our model jointly learns a feature embedding for motion modes (that the motion sequence can be reconstructed from) and a feature transformation that represents the transition of one motion mode to the next motion mode. Our model is able to generate multiple diverse and plausible motion sequences in the future from the same input. We apply our approach to both facial and full body motion, and demonstrate applications like analogy-based motion transfer and video synthesis.
Learning 6-DOF Grasping Interaction via Deep Geometry-aware 3D Representations
Jun 15, 2018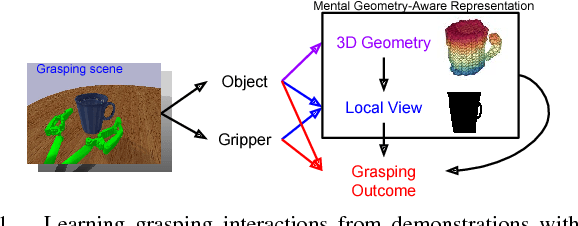
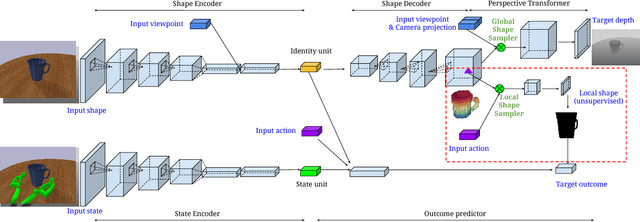
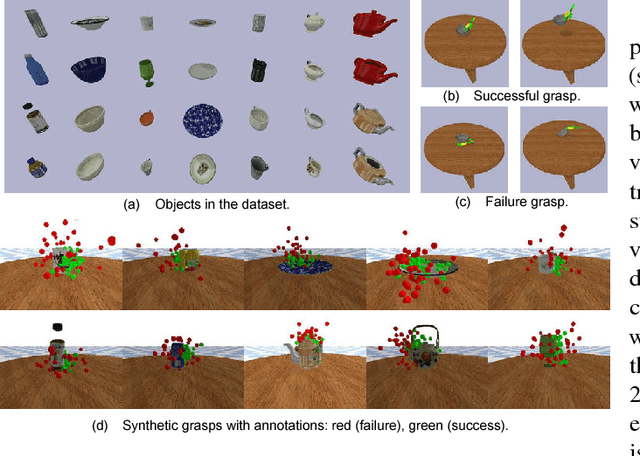
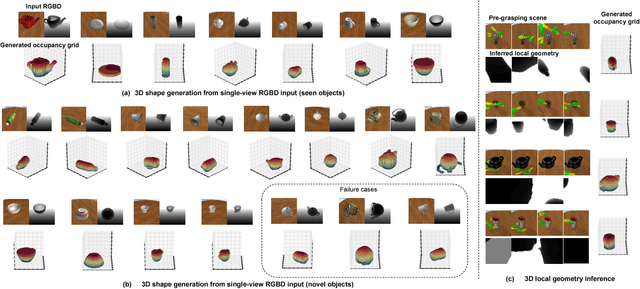
This paper focuses on the problem of learning 6-DOF grasping with a parallel jaw gripper in simulation. We propose the notion of a geometry-aware representation in grasping based on the assumption that knowledge of 3D geometry is at the heart of interaction. Our key idea is constraining and regularizing grasping interaction learning through 3D geometry prediction. Specifically, we formulate the learning of deep geometry-aware grasping model in two steps: First, we learn to build mental geometry-aware representation by reconstructing the scene (i.e., 3D occupancy grid) from RGBD input via generative 3D shape modeling. Second, we learn to predict grasping outcome with its internal geometry-aware representation. The learned outcome prediction model is used to sequentially propose grasping solutions via analysis-by-synthesis optimization. Our contributions are fourfold: (1) To best of our knowledge, we are presenting for the first time a method to learn a 6-DOF grasping net from RGBD input; (2) We build a grasping dataset from demonstrations in virtual reality with rich sensory and interaction annotations. This dataset includes 101 everyday objects spread across 7 categories, additionally, we propose a data augmentation strategy for effective learning; (3) We demonstrate that the learned geometry-aware representation leads to about 10 percent relative performance improvement over the baseline CNN on grasping objects from our dataset. (4) We further demonstrate that the model generalizes to novel viewpoints and object instances.
Perspective Transformer Nets: Learning Single-View 3D Object Reconstruction without 3D Supervision
Aug 13, 2017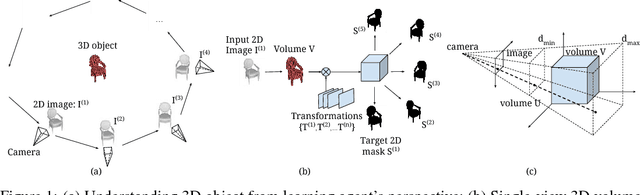
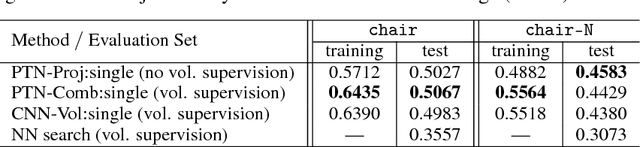
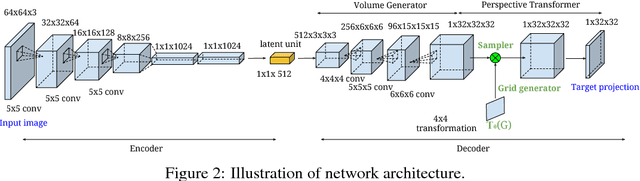
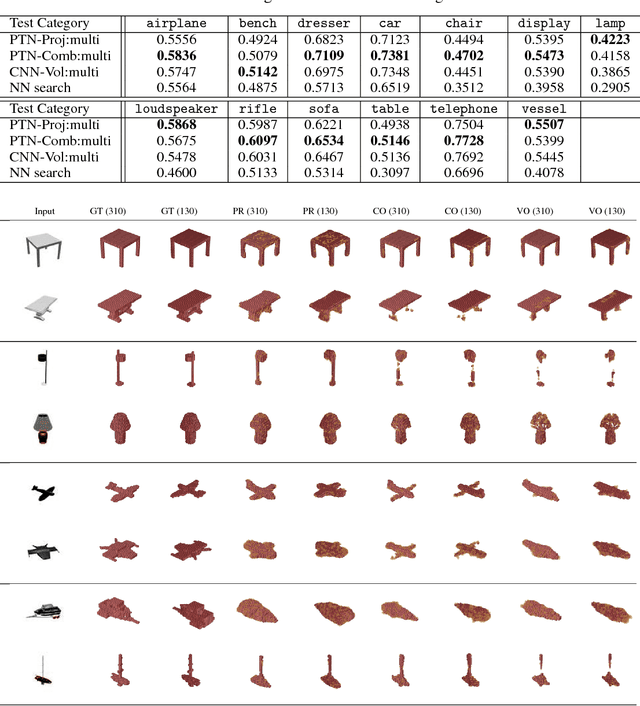
Understanding the 3D world is a fundamental problem in computer vision. However, learning a good representation of 3D objects is still an open problem due to the high dimensionality of the data and many factors of variation involved. In this work, we investigate the task of single-view 3D object reconstruction from a learning agent's perspective. We formulate the learning process as an interaction between 3D and 2D representations and propose an encoder-decoder network with a novel projection loss defined by the perspective transformation. More importantly, the projection loss enables the unsupervised learning using 2D observation without explicit 3D supervision. We demonstrate the ability of the model in generating 3D volume from a single 2D image with three sets of experiments: (1) learning from single-class objects; (2) learning from multi-class objects and (3) testing on novel object classes. Results show superior performance and better generalization ability for 3D object reconstruction when the projection loss is involved.
Deep Variational Canonical Correlation Analysis
Feb 25, 2017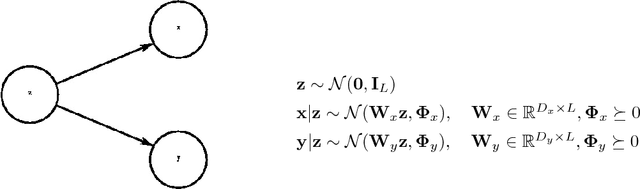

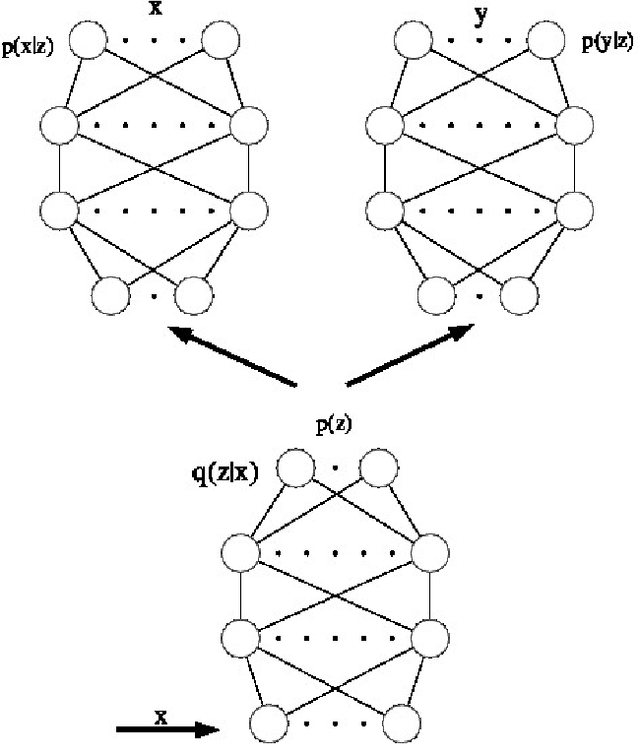
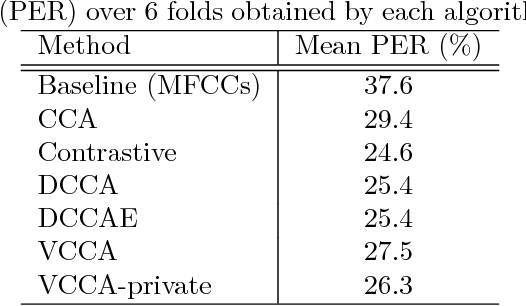
We present deep variational canonical correlation analysis (VCCA), a deep multi-view learning model that extends the latent variable model interpretation of linear CCA to nonlinear observation models parameterized by deep neural networks. We derive variational lower bounds of the data likelihood by parameterizing the posterior probability of the latent variables from the view that is available at test time. We also propose a variant of VCCA called VCCA-private that can, in addition to the "common variables" underlying both views, extract the "private variables" within each view, and disentangles the shared and private information for multi-view data without hard supervision. Experimental results on real-world datasets show that our methods are competitive across domains.